Pada chapter ini penulis hendak mengajak pembaca lebih familiar dengan sintaks atau perintah yang ada pada R yang akan membantu pembaca untuk melakukan pemrograman pada R. Pembaca akan mempelajari penggunaan operator dalam melakukan operasi pengolahan data pada R, jenis data yang ada pada R, sampai dengan bagaimana kita melakukan proses decision making menggunakan R.
Daftar Isi
2.1 Operator Aritmatika
Proses perhitungan akan ditangani oleh fungsi khusus. R akan memahami urutannya secara benar. Kecuali kita secara eksplisit menetapkan yang lain. Sebagai contoh jalankan sintaks berikut:
2+4*2## [1] 10Bandingkan dengan sintaks berikut:
(2+4)*2## [1] 12
Rdapat digunakan sebagai kalkulator
Berdasarkan kedua hasil tersebut dapat disimpulkan bahwa ketika kita tidak menetapkan urutan perhitungan menggunakan tanda kurung, R akan secara otomatis akan menghitung terlebih dahulu perkalian atau pembangian.
Operator aritmatika yang disediakan R adalah sebagai berikut:
Table 1 Operator Aritmatika R
| Simbol | Keterangan |
|---|---|
| + | Addition, untuk operasi penjumlahan |
| - | Substraction, untuk operasi pengurangan |
| * | Multiplication, untuk operasi pembagian |
| / | Division, untuk operasi pembagian |
| ^ | Eksponentiation, untuk operasi pemangkatan |
| %% | Modulus, Untuk mencari sisa pembagian |
| %/% | Integer, Untuk mencari bilangan bulat hasil pembagian saja dan tanpa sisa pembagian |
Untuk lebih memahaminya berikut contoh sintaks penerapan operator tersebut.
# Addition
5+3## [1] 8# Substraction
5-3## [1] 2# Multiplication
5*3## [1] 15# Division
5/3## [1] 1.666667# Eksponetiation
5^3## [1] 125# Modulus
5%%3## [1] 2# Integer
5%/%3## [1] 1Note: Pada
Rtanda#berfungsi menambahkan keterangan untuk menjelaskan sebuah sintaks padaR.
2.2 Fungsi Aritmetik
Selain fungsi operator aritmetik, pada R juga telah tersedia fungsi aritmetik yang lain seperti logaritmik, ekponensial, trigonometri, dll.
- Logaritma dan eksponensial
Untuk contoh fungsi logaritmik dan eksponensial jalankan sintaks berikut:
log2(8) # logaritma basis 2 untuk 8## [1] 3log10(8) # logaritma basis 10 untuk 8## [1] 0.90309exp(8) # eksponensial 8## [1] 2980.958- Fungsi trigonometri
fungsi trigonometri yang ditampilkan seperti sin,cos, tan, dll.
cos(x) # cos x
sin(x) # Sin x
tan(x) # Tan x
acos(x) # arc-cos x
asin(x) # arc-sin x
atan(x) #arc-tan xNote: x dalam fungsi trigonometri memiliki satuan radian
Berikut adalah salah satu contoh penggunaannya:
cos(pi)## [1] -1- Fungsi matematik lainnya
Fungsi lainnya yang dapat digunakan adalah fungsi absolut, akar kuadrat, dll. Berikut adalah contoh sintaks penggunaan fungsi absolut dan akar kuadrat.
abs(-2) # nilai absolut -2## [1] 2sqrt(4) # akar kuadrat 4## [1] 22.3 Operator Relasi
Operator relasi digunakan untuk membandingkan satu objek dengan objek lainnya. Operator yang disediakan R disajikan pada Table 2.
Table 2 Operator Relasi R
| Simbol | Keterangan |
|---|---|
| “>” | Lebih besar dari |
| “<” | Lebih Kecil dari |
| “==” | Sama dengan |
| “>=” | Lebih besar sama dengan |
| “<=” | Lebih kecil sama dengan |
| “!=” | Tidak sama dengan |
Berikut adalah penerapan operator pada tabel tersebut:
x <- 34
y <- 35
# Operator >
x > y## [1] FALSE# Operator <
x < y## [1] TRUE# operator ==
x == y## [1] FALSE# Operator >=
x >= y## [1] FALSE# Operator <=
x <= y## [1] TRUE# Operator !=
x != y## [1] TRUE2.4 Operator Logika
Operator logika hanya berlaku pada vektor dengan tipe logical, numeric, atau complex. Semua angka bernilai 1 akan dianggap bernilai logika TRUE. Operator logika yang disediakan R dapat dilihat pada Table 3.
Table 3 Operator logika R
| Simbol | Keterangan |
|---|---|
| && | Operator logika AND |
| ! | Opeartor logika NOT |
| & | Operator logika AND element wise |
| Operator logika OR element wise |
Penerapannya terdapat pada sintaks berikut:
v <- c(TRUE,TRUE, FALSE)
t <- c(FALSE,FALSE,FALSE)
# Operator &&
print(v&&t)## [1] FALSE# Operator ||
print(v||t)## [1] TRUE# Operator !
print(!v)## [1] FALSE FALSE TRUE# operator &
print(v&t)## [1] FALSE FALSE FALSE# Operator |
print(v|t)## [1] TRUE TRUE FALSENote:
operator & dan | akan mengecek logika tiap elemen pada vektor secara berpesangan (sesuai urutan dari kiri ke kanan).
Operator %% dan || hanya mengecek dari kiri ke kanan pada observasi pertama. Misal saat menggunakan && jika observasi pertama TRUE maka observasi pertama pada vektor lainnya akan dicek, namun jika observasi pertama FALSE maka proses akan segera dihentikan dan menghasilkan FALSE.
2.5 Memasukkan Nilai Kedalam Variabel
Variabel pada R dapat digunakan untuk menyimpan nilai. Sebagai contoh jalankan sintaks berikut:
# Harga sebuah lemon adalah 500 rupiah
lemon <- 500
# Atau
500 -> lemon
# dapat juga menggunakan tanda "="
lemon = 500Note:
Rmemungkinkan penggunaan <-,->, atau = sebagai perintah pengisi nilai variabel
Rbersifat case-sensitive. Maksudnya adalah variabel Lemon tidak sama dengan lemon (Besar kecil huruf berpengaruh)
Untuk mengetahui nilai dari objek lemon kita dapat menggunakan fungsi print() atau mengetikkan nama objeknya secara langsung.
# Menggunakan fungsi print()
print(lemon)## [1] 500# Atau
lemon## [1] 500R akan menyimpan variabel lemon sebagai objek pada memori. Sehingga kita dapat melakukan operasi terhadap objek tersebut seperti mengalikannya atau menjumlahkannya dengan bilangan lain. Sebagai contoh jalankan sintaks berikut:
# Operasi perkalian terhadap objek lemon
5*lemon## [1] 2500Kita dapat juga mengubah nilai dari objek lemon dengan cara menginput nilai baru terhadap objek yang sama. R secara otomatis akan menggatikan nilai sebelumnya. Untuk lebih memahaminya jalankan sintaks berikut:
lemon <- 1000
# Print lemon
print(lemon)## [1] 1000Untuk lebih memahaminya berikut adalah sintaks untuk menghitung volume suatu objek.
# Dimensi objek
panjang <- 10
lebar <- 5
tinggi <- 5
# Menghitung volume
volume <- panjang*lebar*tinggi
# Print objek volume
print(volume)## [1] 250Untuk mengetahui objek apa saja yang telah kita buat sepanjang artikel ini kita dapang menggunakan fungsi ls().
ls()## [1] "lebar" "lemon" "panjang" "t" "tinggi" "v" "volume"
## [8] "x" "y"Kumpulan objek yang telah tersimpan dalam memori disebut sebagai workspace
Untuk menghapus objek pada memori kita dapat menggunakan fungsi rm(). Pada sintaks berikut penulis hendak menghapus objek lemon dan volume.
# Menghapus objek lemon dan volume
rm(lemon, volume)
# Tampilkan kembali objek yang tersisa
ls()## [1] "lebar" "panjang" "t" "tinggi" "v" "x" "y"Note: Setiap variabel atau objek yang dibuat akan menempati sejumlah memori pada komputer sehingga jika kita bekerja dengan jumlah data yang banyak pastikan kita menghapus seluruh objek pada memori sebelum memulai kerja.
2.6 Tipe Data
Data pada R dapat dikelompokan berdasarkan beberapa tipe. Tipe data pada R disajikan pada Table 4.
Table 4 Tipe Data R
| Tipe Data | Contoh | Keterangan |
|---|---|---|
| Logical | TRUE, FALSE | Nilai Boolean |
| Numeric | 12.3, 5, 999 | Segala jenis angka |
| Integer | 23L, 97L, 3L | Bilangan integer (bilangan bulat) |
| Complex | 2i, 3i, 9i | Bilangan kompleks |
| Character | ‘a’, “b”, “123” | Karakter dan string |
| Raw | Identik dengan “hello” | Segala jenis data yang disimpan sebagai raw bytes |
Sintaks berikut adalah contoh dari tipe data pada R. Untuk mengetahui tipa data suatu objek kita dapat menggunakan perintah class()
# Logical
apel <- TRUE
class(apel)## [1] "logical"# Numeric
x <- 2.3
class(x)## [1] "numeric"# Integer
y <- 2L
class(y)## [1] "integer"# Compleks
z <- 5+2i
class(z)## [1] "complex"# string
w <- "saya"
class(w)## [1] "character"# Raw
xy <- charToRaw("hello world")
class(xy)## [1] "raw"Keenam jenis data tersebut disebut sebagai tipe data atomik. Hal ini disebabkan karena hanya dapat menangani satu tipe data saja. Misalnya hanya numeric atau hanya integer.
Selain menggunakan fungsi class(), kita dapat pula menggunakan fungsi is_numeric(), is.character(), is.logical(), dan sebagainya berdasarkan jenis data apa yang ingin kita cek. Berbeda dengan fungsi class(), ouput yang dihasilkan pada fungsi seperti is_numeric() adalah nilai Boolean sehingga fungsi ini hanya digunakan untuk mengecek apakah jenis data pada objek sama seperti yang kita pikirkan. Sebagai contoh disajikan pada sintaks berikut:
data <- 25
# Cek apakah objek berisi data numerik
is.numeric(data)## [1] TRUE# Cek apakah objek adalah karakter
is.character(data)## [1] FALSEKita juga dapat mengubah jenis data menjadi jenis lainnya seperti integer menjadi numerik atau sebaliknya. Fungsi yang digunakan adalah as.numeric() jika ingin mengubah suatu jenis data menjadi numerik. Fungsi lainnya juga dapat digunakan sesuai dengan kita ingin mengubah jenis data objek menjadi jenis data lainnya.
# Integer
apel <- 2L
# Ubah menjadi numerik
as.numeric(apel)## [1] 2# Cek
is.numeric(apel)## [1] TRUE# Logical
nangka <- TRUE
# Ubah logical menjadi numeric
as.numeric(nangka)## [1] 1# Karakter
minum <- "minum"
# ubah karakter menjadi numerik
as.numeric(minum)## Warning: NAs introduced by coercion## [1] NANote: Konversi karakter menjadi numerik akan menghasilkan output NA (not available).
Rtidak mengetahui bagaimana cara merubah karakter menjadi bentuk numerik.
Berdasarkan Tabel 2, vektor karakter dapat dibuat menggunakan tanda kurung baik double quote (“”) maupun single quote (’’).Jika pada teks yang kita tuliskan mengandung quote maka kita harus menghentikannya menggunakan tanda ( ). Sbegai contoh kita ingin menuliskan `My friend’s name is “Adi”, pada sintaks akan dituliskan:
'My friend\`s name is "Adi"'## [1] "My friend`s name is \"Adi\""# Atau
"My friend's name \"Adi\""## [1] "My friend's name \"Adi\""Struktur data diklasifikasikan berdasarkan dimensi data dan tie data di dalamnya (homogen atau heterogen). Klasifikasi jenis data disajikan pada Tabel 1.
| Dimensi | Homogen | Heterogen |
|---|---|---|
| 1d | Atomik vektor | List |
| 2d | Matriks | Dataframe |
| nd | Array |
Berdasarkan Tabel tersebut dapat kita lihat bahwa objek terbagi atas dua buah struktur data yaitu homogen dan heterogen. Objek dengan struktur data homogen hanya dapat menyimpan satu tipe atau jenis data saja (numerik saja atau factor saja), sedangkan objek dengan struktur data heterogen akan dapat menyimpan berbagai jenis data.
Berdasarkan daftar yang ada di Tabel 1, kita tidak akan membahas struktur data Array pada buku ini. Struktur data tersebut lebih banyak digunakan untuk kepentingan akademis seperti membuat model matematis yang akan penulis bahas pada buku lain.
2.7 Vektor
Vektor merupakan kombinasi berbagai nilai (numerik, karakter, logical, dan sebagainya berdasarkan jenis input data) pada objek yang sma. Pada contoh kasus berikut, pembaca akan memiliki sesuai jenis data input yaituvektor numerik, vector karakter, vektor logical, dll.
2.7.1 Membuat vektor
Vektor dibuat dengan menggunakan fungsi c()(concatenate) seperti yang disajikan pada sintaks berikut:
# membuat vektor numerik
x <- c(3,3.5,4,7)
x # print vektor## [1] 3.0 3.5 4.0 7.0# membuat vektor karakter
y <- c("Apel", "Jeruk", "Rambutan", "Salak")
y # print vektor## [1] "Apel" "Jeruk" "Rambutan" "Salak"# membuat vektor logical
t <- c("TRUE", "FALSE", "TRUE")
t # print vektor## [1] "TRUE" "FALSE" "TRUE"selain menginput nilai pada vektor, kita juga dapat memberi nama nilai setiap vektor menggunakan fungsi names().
# Membuat vektor jumlah buah yang dibeli
Jumlah <- c(5,5,6,7)
names(Jumlah) <- c("Apel", "Jeruk", "Rambutan", "Salak")
# Atau
Jumlah <- c(Apel=5, Jeruk=5, Rambutan=6, Salak=7)
# Print
Jumlah## Apel Jeruk Rambutan Salak
## 5 5 6 7Note: Vektor hanya dapat memuat satu buah jenis data. Vektor hanya dapat mengandung jenis data numerik saja, karakter saja, dll.
Untuk menentukan panjang sebuah vektor kita dapat menggunakan fungsi lenght().
length(Jumlah)## [1] 42.7.2 Missing Values
Seringkali nilai pada vektor kita tidak lengkap atau terdapat nilai yang hilang (missing value) pada vektor. Missing value pada R dilambangkan oleh NA(not available). Berikut adalah contoh vektor dengan missing value.
Jumlah <- c(Apel=5, Jeruk=NA, Rambutan=6, Salak=7)Untuk mengecek apakah dalam objek terdapat missing value dapat menggunakan fungsi is.na(). ouput dari fungsi tersebut adalah nilai Boolean. Jika terdapat Missing value, maka output yang dihasilkan akan memberikan nilai TRUE.
is.na(Jumlah)## Apel Jeruk Rambutan Salak
## FALSE TRUE FALSE FALSENote:
Selain NA terdapat NaN (not a number) sebagai missing value8. Nilai tersebut muncul ketika fungsi matematika yang digunakan pada proses perhitungan tidak bekerja sebagaimana mestinya. Contoh: 0/0 = NaN
is.na()juga akan menghasilkan nilaiTRUEpada NaN. Untuk membedakannya dengan NA dapat digunakan fungsiis.nan().
2.7.3 Subset Pada Vektor
Subseting vector terdiri atas tiga jenis, yaitu: positive indexing, Negative Indexing, dan .
- Positive indexing: memilih elemen vektor berdasarkan posisinya (indeks) dalam kurung siku.
# Subset vektor pada urutan kedua
Jumlah[2]## Jeruk
## NA# Subset vektor pada urutan 2 dan 4
Jumlah[c(2, 4)]## Jeruk Salak
## NA 7Selain melalui urutan (indeks), kita juga dapat melakukan subset berdasarkan nama elemen vektornya.
Jumlah["Jeruk"]## Jeruk
## NANote: Indeks pada
Rdimulai dari 1. Sehingga kolom atau elemen pertama vektor dimulai dari [1]
- Negative indexing: mengecualikan (exclude) elemen vektor.
# mengecualikan elemen vektor 2 dan 4
Jumlah[-c(2,4)]## Apel Rambutan
## 5 6# mengecualikan elemen vektor 1 sampai 3
Jumlah[-c(1:3)]## Salak
## 7- Subset berdasarkan vektor logical: Hanya, elemen-elemen yang nilai yang bersesuaian dalam vektor pemilihan bernilai TRUE, akan disimpan dalam subset.
Note: panjang vektor yang digunakan untuk subset harus sama.
Jumlah <- c(Apel=5, Jeruk=NA, Rambutan=6, Salak=7)
# selecting vector
merah <- c(TRUE, FALSE, TRUE, FALSE)
# Subset
Jumlah[merah==TRUE]## Apel Rambutan
## 5 6# Subset untuk elemen vektor bukan missing value
Jumlah[!is.na(Jumlah)]## Apel Rambutan Salak
## 5 6 72.7.4 Perhitungan Menggunakan Vektor
Jika Anda melakukan operasi dengan vektor, operasi akan diterapkan ke setiap elemen vektor. Contoh disediakan pada sintaks di bawah ini:
pendapatan <- c(2000, 1800, 2500, 3000)
names(pendapatan) <- c("Andi", "Joni", "Lina", "Rani")
pendapatan## Andi Joni Lina Rani
## 2000 1800 2500 3000# Kalikan pendapatan dengan 3
pendapatan*3## Andi Joni Lina Rani
## 6000 5400 7500 9000Seperti yang dapat dilihat, R mengalikan setiap elemen dengan bilangan pengali.
Kita juga dapat mengalikan vektor dengan vektor lainnya.Contohnya disajikan pada sintaks berikut:
# membuat vektor dengan panjang sama dengan dengan vektor pendapatan
coefs <- c(2, 1.5, 1, 3)
# Mengalikan pendapatan dengan vektor coefs
pendapatan*coefs## Andi Joni Lina Rani
## 4000 2700 2500 9000Berdasarkan sintaks tersebut dapat terlihat bahwa operasi matematik terhadap masing-masing vektor dapat berlangsung jika panjang vektornya sama.
Berikut adalah fungsi lain yang dapat digunakan pada operasi matematika vektor.
max(x) # memperoleh nilai maksimum x
min(x) # memperoleh nilai minimum x
range(x) # memperoleh range vektor x
length(x) # memperoleh jumlah elemen vektor x
sum(x) # memperoleh total penjumlahan elemen vektor x
prod(x) # memeperoleh produk elemen vektor x
mean(x) # memperoleh nilai rata-rata seluruh elemen vektor x
sd(x) # standar deviasi vektor x
var(x) # varian vektor x
sort(x) # mengurutkan elemen vektor x dari yang terbesarContoh penggunaan fungsi tersebut disajikan beberapa pada sintaks berikut:
# Menghitung range pendapatan
range(pendapatan)## [1] 1800 3000# menghitung rata-rata dan standar deviasi pendapatan
mean(pendapatan)## [1] 2325sd(pendapatan)## [1] 537.74222.8 Matriks
Matriks seperti Excel sheet yang berisi banyak baris dan kolom (kumpulan bebrapa vektor). Matriks digunakan untuk menggabungkan vektor dengan tipe yang sama, yang bisa berupa numerik, karakter, atau logis. Matriks digunakan untuk menyimpan tabel data dalam R. Baris-baris matriks pada umumnya adalah individu / pengamatan dan kolom adalah variabel.
2.8.1 Membuat matriks
Untuk membuat matriks kita dapat menggunakan fungsi cbind() atau rbind(). Berikut adalah contoh sintaks untuk membuat matriks.
# membuat vektor numerik
col1 <- c(5, 6, 7, 8, 9)
col2 <- c(2, 4, 5, 9, 8)
col3 <- c(7, 3, 4, 8, 7)
# menggabungkan vektor berdasarkan kolom
my_data <- cbind(col1, col2, col3)
my_data## col1 col2 col3
## [1,] 5 2 7
## [2,] 6 4 3
## [3,] 7 5 4
## [4,] 8 9 8
## [5,] 9 8 7# Mengubah atau menambahkan nama baris
rownames(my_data) <- c("row1", "row2", "row3", "row4", "row5")
my_data## col1 col2 col3
## row1 5 2 7
## row2 6 4 3
## row3 7 5 4
## row4 8 9 8
## row5 9 8 7Note:
- cbind(): menggabungkan objek
Rberdasarkan kolom- rbind(): menggabungkan objek
Rberdasarkan baris- rownames(): mengambil atau menetapkan nama-nama baris dari objek seperti-matriks
- colnames(): mengambil atau menetapkan nama-nama kolom dari objek seperti-matriks
Kita dapat melakukan tranpose (merotasi matriks sehingga kolom menjadi baris dan sebaliknya) menggunakan fungsi t(). Berikut adalah contoh penerapannya:
t(my_data)## row1 row2 row3 row4 row5
## col1 5 6 7 8 9
## col2 2 4 5 9 8
## col3 7 3 4 8 7Selain melalui pembentukan sejumlah objek vektor, kita juga dapat membuat matriks menggunakan fungsi matrix(). Secara sederhana fungsi tersebut dapat dituliskan sebagai berikut:
matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE,
dimnames = NULL)Note:
- data: vektor data opsional
- nrow, ncol: jumlah baris dan kolom yang diinginkan, masing-masing.
- byrow: nilai logis. Jika FALSE (default) matriks diisi oleh kolom, jika tidak, matriks diisi oleh baris.
- dimnames: Daftar dua vektor yang memberikan nama baris dan kolom masing-masing.
Dalam kode R di bawah ini, data input memiliki panjang 6. Kita ingin membuat matriks dengan dua kolom. Kita tidak perlu menentukan jumlah baris (di sini nrow = 3). R akan menyimpulkan ini secara otomatis. Matriks diisi kolom demi kolom saat argumen byrow = FALSE. Jika kita ingin mengisi matriks dengan baris, gunakan byrow = TRUE. Berikut adalah contoh pembuatan matriks menggunakan fungsi matrix().
data <- matrix(
data = c(1,2,3, 11,12,13),
nrow = 2, byrow = TRUE,
dimnames = list(c("row1", "row2"), c("C.1", "C.2", "C.3"))
)
data## C.1 C.2 C.3
## row1 1 2 3
## row2 11 12 13Untuk mengetahui dimensi dari suatu matriks, kita dapat menggunakan fungsi ncol() untuk mengetahui jumlah kolom matriks dan nrow() untuk mengetahui jumlah baris pada matriks. Berikut adalah contoh penerapannya:
# mengetahui jumlah kolom
ncol(my_data)## [1] 3# mengetahui jumlah baris
nrow(my_data)## [1] 5Jika ingin memperoleh ringkasan terkait dimensi matriks kita juga dapat mengunakan fungsi dim() untuk mengetahui jumlah baris dan kolom matriks. Berikut adalah contoh penerapannya:
dim(my_data) # jumlah baris dan kolom## [1] 5 32.8.2 Subset Pada Matriks
Sama dengan vektor, subset juga dapat dilakukan pada matriks. Bedanya subset dilakukan berdasarkan baris dan kolom pada matriks.
- Memilih baris/kolom berdasarkan pengindeksan positif
baris atau kolom dapat diseleksi menggunakan format data[row, col]. Cara selesi ini sama dengan vektor, bedanya kita harus menetukan baris dan kolom dari data yang akan kita pilih. Berikut adalah contoh penerapannya:
# Pilih baris ke-2
my_data[2,]## col1 col2 col3
## 6 4 3# Pilih baris 2 sampai 4
my_data[2:4,]## col1 col2 col3
## row2 6 4 3
## row3 7 5 4
## row4 8 9 8# Pilih baris 2 dan 4
my_data[c(2,4),]## col1 col2 col3
## row2 6 4 3
## row4 8 9 8# Pilih baris 2 dan kolom 3
my_data[2, 3]## [1] 3- Pilih berdasarkan nama baris/kolom
Berikut adalah contoh subset berdasarkan nama baris atau kolom.
# Pilih baris 1 dan kolom 3
my_data["row1","col3"]## [1] 7# Pilih baris 1 sampai 4 dan kolom 3
baris <- c("row1","row2","row3")
my_data[baris, "col3"]## row1 row2 row3
## 7 3 4- Kecualikan baris/kolom dengan pengindeksan negatif
Sama seperti vektor pengecualian data dapat dilakukan di matriks menggunakan pengindeksan negatif. Berikut cara melakukannya:
# Kecualikan baris 2 dan 3 serta kolom 3
my_data[-c(2,3), -3]## col1 col2
## row1 5 2
## row4 8 9
## row5 9 8- Pilihan dengan logik
Dalam kode R di bawah ini, misalkan kita ingin hanya menyimpan baris di mana col3> = 4:
col3 <- my_data[, "col3"]
my_data[col3 >= 4, ]## col1 col2 col3
## row1 5 2 7
## row3 7 5 4
## row4 8 9 8
## row5 9 8 72.8.3 Perhitungan Menggunakan Matriks
_ Kita juga dapat melakukan operasi matematika pada matriks. Pada operasi matematika pada matriks proses yang terjadi bisa lebih kompleks dibanding pada vektor, dimana kita dapat melakukan operasi untuk memperoleh gambaran data pada tiap kolom atau baris.
Berikut adalah contoh operasi matematika sederhana pada matriks:
# mengalikan masing-masing elemen matriks dengan 2
my_data*2## col1 col2 col3
## row1 10 4 14
## row2 12 8 6
## row3 14 10 8
## row4 16 18 16
## row5 18 16 14# memperoleh nilai log basis 2 pada masing-masing elemen matriks
log2(my_data)## col1 col2 col3
## row1 2.321928 1.000000 2.807355
## row2 2.584963 2.000000 1.584963
## row3 2.807355 2.321928 2.000000
## row4 3.000000 3.169925 3.000000
## row5 3.169925 3.000000 2.807355Seperti yang telah penulis jelaskan sebelumnya, kita juga dapat melakukan operasi matematika untuk memperoleh hasil penjumlahan elemen pada tiap baris atau kolom dengan menggunakan fungsi rowSums() untuk baris dan colSums() untuk kolom.
# Total pada tiap kolom
colSums(my_data)## col1 col2 col3
## 35 28 29# Total pada tiap baris
rowSums(my_data)## row1 row2 row3 row4 row5
## 14 13 16 25 24Jika kita tertarik untuk mencari nilai rata-rata tiap baris arau kolom kita juga dapat menggunakan fungsi rowMeans() atau colMeans(). Berikut adalah contoh penerapannya:
# Rata-rata tiap baris
rowMeans(my_data)## row1 row2 row3 row4 row5
## 4.666667 4.333333 5.333333 8.333333 8.000000# Rata-rata tiap kolom
colMeans(my_data)## col1 col2 col3
## 7.0 5.6 5.8Kita juga dapat melakukan perhitungan statistika lainnya menggunakan fungsi apply(). Berikut adalah format sederhananya:
apply(x, MARGIN, FUN)Note:
- x : data matriks
- MARGIN : Nilai yang dapat digunakan adalah 1 (untuk operasi pada baris) dan 2 (untuk operasi pada kolom)
- FUN : fungsi yang diterapkan pada baris atau kolom
untuk mengetahui fungsi (FUN) apa saja yang dapat diterapkan pada fungsi apply() jalankan sintaks bantuan berikut:
help(apply)Berikut adalah contoh penerapannya:
# Rata-rata pada tiap baris
apply(my_data, 1, mean)## row1 row2 row3 row4 row5
## 4.666667 4.333333 5.333333 8.333333 8.000000# Median pada tiap kolom
apply(my_data, 2, median)## col1 col2 col3
## 7 5 72.9 Faktor
Dalam bahasa R , faktor merupakan verktor dengan level. Level disimpan sebagai R Character. Jika kita menggunakan SPSS maka factor ini akan sama dengan jenis data numerik atau ordinal.
Faktor merepresentasikan kategori atau grup pada data. Untuk membuat faktor pada R, kita dapat menggunakan fungsi factor().
2.9.1 Membuat Variabel Faktor
Berikut adalah contoh sintaks pembuatan variabel faktor.
# membuat variabel faktor
faktor <- factor(c(1,2,1,2))
faktor## [1] 1 2 1 2
## Levels: 1 2Pada sintaks tersebut objek faktor terdiri atas dua buah kategori atau pada R disebut sebagai factor levels. Kita dapat mengecek factor levels menggunakan fungsi levels().
levels(faktor)## [1] "1" "2"Kita juga dapat memberikan label atau mengubah level pada faktor. Berikut adalah contoh bagaimana kita melakukannya:
# Ubah level
levels(faktor) <- c("baik","tidak_baik")
faktor## [1] baik tidak_baik baik tidak_baik
## Levels: baik tidak_baik# Ubah urutan level
faktor <- factor(faktor,
levels = c("tidak_baik","baik"))
faktor## [1] baik tidak_baik baik tidak_baik
## Levels: tidak_baik baikNote:
- Fungsi
is.factor()dapat digunakan untuk mengecek apakah sebuah variabel adalah faktor. Hasil yang dimunculkan dapat berupa TRUE (jika faktor) atau FALSE (jika bukan)- Fungsi
as.factor()dapat digunakan untuk merubah sebuah variabel menjadi faktor.
# Cek jika objek faktor adalah faktor
is.factor(faktor)## [1] TRUE# Cek jika objek Jumlah adalah faktor
is.factor(Jumlah)## [1] FALSE# Ubah objek Jumlah menjadi faktor
as.factor(Jumlah)## Apel Jeruk Rambutan Salak
## 5 <NA> 6 7
## Levels: 5 6 72.9.2 Perhitungan Menggunakan Faktor
Jika kita ingin mengetahui jumlah masing-masing observasi pada masing-masing faktor, kita dapat menggunakan fungsi summary(). Berikut adalah contoh penerapannya:
summary(faktor)## tidak_baik baik
## 2 2Pada contoh perhitungan menggunakan vektor kita telah membuat objek pendapatan. Pada objek tersebut kita ingin menghitung nilai rata-rata pendapatan berdasarkan objek faktor. Untuk melakukannya kita dapat menggunakan fungsi tapply().
pendapatan## Andi Joni Lina Rani
## 2000 1800 2500 3000faktor## [1] baik tidak_baik baik tidak_baik
## Levels: tidak_baik baik# Rata-rata pendapatan dan simpan sebagai objek dengan nama:
# mean_pendapatan
mean_pendapatan <- tapply(pendapatan, faktor, mean)
mean_pendapatan## tidak_baik baik
## 2400 2250# Hitung ukuran/panjang masing-masing grup
tapply(pendapatan, faktor, length)## tidak_baik baik
## 2 2Untuk mengetahui jumlah masing-masing observasi masing-masing factor levels kita juga dapat menggunakan fungsi table(). Fungsi tersebut akan membuat frekuensi tabel pada masing-masing factor levels atau yang dikenal sebagai contingency table.
table(faktor)## faktor
## tidak_baik baik
## 2 2# Cross-tabulation antara
# faktor dan pendapatan
table(pendapatan, faktor)## faktor
## pendapatan tidak_baik baik
## 1800 1 0
## 2000 0 1
## 2500 0 1
## 3000 1 02.10 Data Frames
Data frame merupakan kumpulan vektor dengan panjang sama atau dapat pula dikatan sebagai matriks yang memiliki kolom dengan jenis data yang berbeda-beda (numerik, karakter, logical). Pada data frame terdapat baris dan kolom. Baris disebut sebagai observasi, sedangkan kolom disebut sebagai variabel. Sehingga dapat dikatakan bahwa setiap observasi akan memiliki satu atau beberapa variabel.
2.10.1 Membuat Data Frame
Data frame dapat dibuat menggunakan fungsi data.frame(). Berikut adalah contoh cara membuat data frame:
# Membuat data frame
nama <- c("Andi","Rizal","Ani","Ina")
pendapatan <- c(1000, 2000, 3500, 500)
tinggi <- c(160, 155, 170, 146)
usia <- c(35, 40, 25, 27)
menikah <- c(TRUE, FALSE, TRUE, TRUE)
data_teman <- data.frame(nama = nama,
gaji = pendapatan,
tinggi = tinggi,
menikah = menikah)
data_teman## nama gaji tinggi menikah
## 1 Andi 1000 160 TRUE
## 2 Rizal 2000 155 FALSE
## 3 Ani 3500 170 TRUE
## 4 Ina 500 146 TRUEUntuk mengecek apakah objek data_teman merupakan data frame, kita dapat menggunakan fungsi is.data.frame(). Jika hasilnya TRUE, maka objek tersebut adalah data frame. Berikut adalah contoh penerapannya:
is.data.frame(data_teman)## [1] TRUENote: untuk konversi objek menjadi data frame, kita dapat menjalankan fungsi
as.data.frame().
2.10.2 Subset Pada Data Frame
Subset pada data frame sebenarnya tidak berbeda dengan subset pada matriks. Bedanya adalah kita juga bisa melakukan subset langsung terhadap nama variabel menggunakan dollar sign. Untuk lebih memahaminya berikut adalah jenis subset pada data frame.
- Pengindeksan positif menggunakan nama dan lokasi.
# Subset menggunakan dollar sign
data_teman$nama## [1] Andi Rizal Ani Ina
## Levels: Andi Ani Ina Rizal# atau
data_teman[, "nama"]## [1] Andi Rizal Ani Ina
## Levels: Andi Ani Ina Rizal# subset baris 1 sampai 3 serta kolom 1 dan 3
data_teman[1:3, c(1,3)]## nama tinggi
## 1 Andi 160
## 2 Rizal 155
## 3 Ani 170- Pengindeksan negatif
# Kecualikan kolom nama
data_teman[,-1]## gaji tinggi menikah
## 1 1000 160 TRUE
## 2 2000 155 FALSE
## 3 3500 170 TRUE
## 4 500 146 TRUE- Pengideksan berdasarkan karakteristik
Kita ingin memilih data dengan kriteria teman yang telah menikah
data_teman[data_teman$menikah==TRUE, ]## nama gaji tinggi menikah
## 1 Andi 1000 160 TRUE
## 3 Ani 3500 170 TRUE
## 4 Ina 500 146 TRUE# Tampilkan hanya kolom nama dan gaji untuk yang telah menikah
data_teman[data_teman$menikah==TRUE, 1:2]## nama gaji
## 1 Andi 1000
## 3 Ani 3500
## 4 Ina 500kita juga dapat menggunakan fungsi subset() agar lebih mudah. Berikut adalah contoh penerapannya:
# subset terhadap teman yang berusia >=30 tahun
subset(data_teman, usia>=30)## nama gaji tinggi menikah
## 1 Andi 1000 160 TRUE
## 2 Rizal 2000 155 FALSEOpsi lain adalah menggunakan fungsi attach() dan detach(). Fungsi attach() mengambil data frame dan membuat kolomnya dapat diakses hanya dengan memberikan nama mereka.
# attach data frame
attach(data_teman)## The following objects are masked _by_ .GlobalEnv:
##
## menikah, nama, tinggi# ==== memulai data manipulation ====
data_teman[usia>=30]## nama gaji
## 1 Andi 1000
## 2 Rizal 2000
## 3 Ani 3500
## 4 Ina 500# ==== mengakhiri data manipulation ====
# detach data frame
detach(data_teman)2.10.3 Memperluas Data Frame
Kita dapat juga memperluas data frame dengan cara menambahkan variabel atau kolombaru pada data frame. Pada contoh kali ini penulis akan menambahkan kolom pendidikan terakhir pada objek data_teman. Berikut adalah sintaks yang digunakan.
# membuat vektor pendidikan
pendidikan <- c("S1","S2","D3","D1")
# menambahkan variabel pendidikan pada data frame
data_teman$pendidikan <- pendidikan# atau
cbind(data_teman, pendidikan=pendidikan)2.10.4 Perhitungan Pada Data Frame
Perhitungan pada variabel numerik data frame pada dasarnya sama dengan perhitungan pada matriks. kita dapat menggunakan fungsi rowSums(), colSums(), rowMeans() dan apply(). Proses perhitungan dan manipulasi pada data frame akan dibahas pada sesi yang lain secara lebih detail.
2.11 List
List adalah kumpulan objek yang diurutkan, yang dapat berupa vektor, matriks, data frame, dll. Dengan kata lain, daftar dapat berisi semua jenis objek R.
2.11.1 Membuat List
List dapat dibuat menggunakan fungsi list(). Berikut disajikan contoh sebuah list sebuah keluarga:
# Membuat list keluarga
keluarga <- list(
ayah = "Budi",
usia_ayah = 48,
ibu = "Ani",
usia_ibu = "47",
anak = c("Andi", "Adi"),
usia_anak = c(15,10)
)
# Print
keluarga## $ayah
## [1] "Budi"
##
## $usia_ayah
## [1] 48
##
## $ibu
## [1] "Ani"
##
## $usia_ibu
## [1] "47"
##
## $anak
## [1] "Andi" "Adi"
##
## $usia_anak
## [1] 15 10# Nama elemen dalam list
names(keluarga)## [1] "ayah" "usia_ayah" "ibu" "usia_ibu" "anak" "usia_anak"# Jumlah elemen pada list
length(keluarga)## [1] 62.11.2 Subset List
Kita dapat memilih sebuah elemen pada list dengan menggunakan nama elemen atau indeks dari elemen tersebut. Berikut adalah contoh penerapannya:
# Subset berdasarkan nama
# mengambil elemen usia_ayah
keluarga$usia_ayah## [1] 48# Atau
keluarga[["usia_ayah"]]## [1] 48# Subset berdasarkan indeks
keluarga[[2]]## [1] 48# subset elemen pertama pada keluarga[[5]]
keluarga[[5]][1]## [1] "Andi"2.11.3 Memperluas List
Kita juga dapat menambahkan elemen pada list yang telah kita buat. Pada contoh list sebelumnya penulis akan menambahkan elemen keluarga yang lain seperti berikut:
# Menambahkan kakek dan nenek pada list
keluarga$kakek <- "Suprapto"
keluarga$nenek <- "Sri"
# Print
keluarga## $ayah
## [1] "Budi"
##
## $usia_ayah
## [1] 48
##
## $ibu
## [1] "Ani"
##
## $usia_ibu
## [1] "47"
##
## $anak
## [1] "Andi" "Adi"
##
## $usia_anak
## [1] 15 10
##
## $kakek
## [1] "Suprapto"
##
## $nenek
## [1] "Sri"Kita juga dapat menggabungkan beberapa list menjadi satu. Berikut adalah format sederhana bagaimana cara menggabungkan beberapa list menjadi satu:
list_baru <- c(list_a, list_b, list_c, ...)2.12 Loop
Loop merupakan kode program yang berulang-ulang. Loop berguna saat kita ingin melakukan sebuah perintah yang perlu dijalankan berulang-ulang seperti melakukan perhitungan maupaun melakukan visualisasi terhadap banyak variabel secara serentak. Hal ini tentu saja membantu kita karena kita tidak perlu menulis sejumlah sintaks yang berulang-ulang. Kita hanya perlu mengatur statement berdasarkan hasil yang kita harapkan.
Pada R bentuk loop dapat bermacam-macam (“for loop”,“while loop”, dll). R menyederhanakan bentuk loop ini dengan menyediakan sejumlah fungsi seperti apply(),tapply(), dll. Sehingga loop jarang sekali muncul dalam kode R. Sehingga R sering disebut sebagai loopless loop.
Meski loop jarang muncul bukan berarti kita tidak akan melakukannya. Terkadang saat kita melakukan komputasi statistik atau matematik dan belum terdapat paket yang mendukung proses tersebut, sering kali kita akan membuat sintaks sendiri berdasarkan algoritma metode tersebut. Pada algoritma tersebut sering pula terdapat loop yang diperlukan selama proses perhitungan. Secara sederhana diagram umum loop ditampilkan pada Figure 1
## Warning: package 'knitr' was built under R version 3.5.3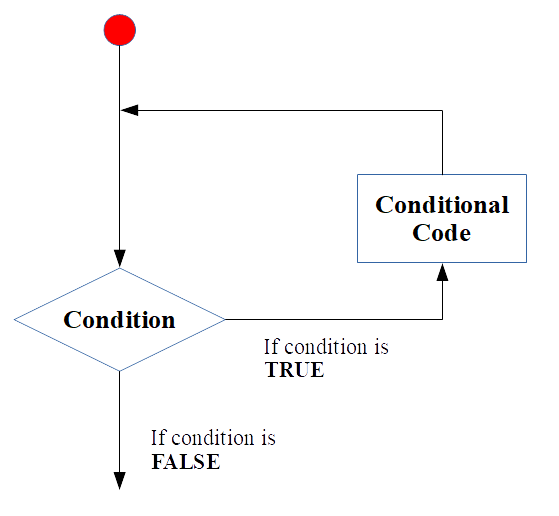
Figure 1: Diagram umum loop (sumber: Primartha, 2018).
2.12.1 For Loop
Mengulangi sebuah statement atau sekelompok statement sebanyak nilai yang ditentukan di awal. Jadi operasi akan terus dilakukan sampai dengan jumlah yang telah ditetapkan di awal atau dengan kata lain tes kondisi (Jika jumlah pengulangan telah cukup) hanya akan dilakukan di akhir. Secara sederhana bentuk dari for loop dapat dituliskan sebagai berikut:
for (value in vector){
statements
}Berikut adalah contoh sintaks penerapan for loop:
# Membuat vektor numerik
vektor <- c(1:5)
# loop
for(i in vektor){
print(i)
}## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5Loop akan dimulai dari blok statement for sampai dengan print(i). Berdasarkan loop pada contoh tersebut, loop hanya dilakukan sebanyak 5 kali sesuai dengan jumlah vektor yang ada.
2.12.2 While Loop
While loop merupakan loop yang digunakan ketika kita telah menetapkan stop condition sebelumnya. Blok statement/kode yang sama akan terus dijalankan sampai stop condition ini tercapai. Stop condition akan di cek sebelum melakukan proses loop. Berikut adalah pola dari while loop dapat dituliskan sebagai berikut:
while (test_expression){
statement
}Berikut adalah contoh penerapan dari while loop:
coba <- c("Contoh")
counter <- 1
# loop
while (counter<5){
# print vektor
print(coba)
# tambahkan nilai counter sehingga proses terus berlangsung sampai counter = 5
counter <- counter + 1
}## [1] "Contoh"
## [1] "Contoh"
## [1] "Contoh"
## [1] "Contoh"Loop akan dimulai dari blok statement while sampai dengan counter <- 1. Loop hanya akan dilakukan sepanjang nilai counter < 5.
2.12.3 Repeat Loop
Repeat loop akan menjalankan statement/kode yang sama berulang-ulang hingga stop condition tercapai. Berikut adalah pola dari repeat loop.
repeat {
commands
if(condition){
break
}
}Berikut adalah contoh penerapan dari repeat loop:
coba <- c("contoh")
counter <- 1
repeat {
print(coba)
counter <- counter + 1
if(counter < 5){
break
}
}## [1] "contoh"Loop akan dimulai dari blok statement while sampai dengan break. Loop hanya akan dilakukan sepanjang nilai counter < 5. Hasil yang diperoleh berbeda dengan while loop, dimana kita memperoleh 4 buah kata “contoh”. Hal ini disebabkan karena repeat loop melakukan pengecekan stop condition tidak di awal loop seperti while loop sehingga berapapun nilainya, selama nilainya sesuai dengan stop condition maka loop akan dihentikan. Hal ini berbeda dengan while loop dimana proses dilakukan berulang-ulang sampai jumlahnya mendekati stop condition.
2.12.4 Break
Break sebenarnya bukan bagian dari loop, namun sering digunakan dalam loop. Break dapat digunakan pada loop manakala dirasa perlu, yaitu saat kondisi yang disyaratkan pada break tercapai.
Berikut adalah contoh penerapan break pada beberapa jenis loop.
# for loop
a = c(2,4,6,8,10,12,14)
for(i in a){
if(i>8){
break
}
print(i)
}## [1] 2
## [1] 4
## [1] 6
## [1] 8# while loop
a = 2
b = 4
while(a<7){
print(a)
a = a +1
if(b+a>10){
break
}
}## [1] 2
## [1] 3
## [1] 4
## [1] 5
## [1] 6# repeat loop
a = 1
repeat{
print(a)
a = a+1
if(a>6){
break
}
}## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5
## [1] 62.13 Loop Menggunakan Apply Family Function
Penggunaan loop sangat membantu kita dalam melakukan proses perhitungan berulang. Namun, metode ini tidak cukup ringkas dalam penerapannya dan perlu penulisan sintaks yang cukup panjang untuk menyelesaikan sebuah kasus yang kita inginkan. Berikut adalah sebuah sintaks yang digunakan untuk menghitung nilai mean pada suatu dataset:
# subset data iris
sub_iris <- iris[,-5]
# membuat vektor untuk menyimpan hasil loop
a <- rep(NA,4)
# loop
for(i in 1:length(sub_iris)){
a[i]<-mean(sub_iris[,i])
}
# print
a## [1] 5.843333 3.057333 3.758000 1.199333class(a) # cek kelas objek## [1] "numeric"Metode alternatif lain untuk melakukan loop suatu fungsi adalah dengan menggunakan Apply function family. Metode ini memungkinkan kita untuk melakukan loop suatu fungsi tanpa perlu menuliskan sintaks loop. Berikut adalah beberapa fungsi dari apply family yang nantinya akan sering kita gunakan:
apply(): fungsi generik yang mengaplikasikan fungsi kepada kolom atau baris pada matriks atau secara lebih general aplikasi dilakukan pada dimensi untuk jenis data array.lapply(): fungsi apply yang bekerja pada jenis data list dan memberikan output berupa list juga.sapply(): bentuk sederhana dari lapply yang menghasilkan output berupa matriks atau vektor.vapply(): disebut juga verified apply (memungkinkan untuk menghasilkan output dengan jenis data yang telah ditentukan sebelumnya).tapply(): tagged apply dimana dimana tag menentukan subset dari data.
2.13.1 Apply
Fungsi apply() bekerja dengan jenis data matrik atau array (jenis data homogen). Kita dapat melakukan spesifikasi apakah suatu fungsi hanya akan bekerja pada kolom saja, baris saja atau keduanya. Format fungsi ini adalah sebagai berikut:
apply(X, MARGIN, FUN, ...)Note:
- X: matriks atau array
- MARGIN: menentukan bagaimana fungsi bekerja terhadap matriks atau array. Jika nilai yang diinputkan 1, maka fungsi akan bekerja pada masing-masing baris pada matriks. Jika nilainya 2, maka fungsi akan bekerja pada tiap kolom pada matriks.
- FUN: fungsi yang akan digunakan. Fungsi yang dapat digunakan dapat berupa fungsi dasar matematika atau statistika, serta user define function.
- …: opsional argumen pada fungsi yang digunakan.
Berikut adalah contoh bagaimana aplikasi fungsi tersebut pada matriks:
## membuat matriks
x <- cbind(x1 = 3, x2 = c(4:1, 2:5))
x # print## x1 x2
## [1,] 3 4
## [2,] 3 3
## [3,] 3 2
## [4,] 3 1
## [5,] 3 2
## [6,] 3 3
## [7,] 3 4
## [8,] 3 5class(x) # cek kelas objek## [1] "matrix"## menghitung mean masing-masing kolom
apply(x, MARGIN=2 ,FUN=mean, trim=0.2, na.rm=TRUE)## x1 x2
## 3 3## menghitung range nilai pada masing-masing baris
## menggunakan user define function
apply(x, MARGIN=1,
FUN=function(x){
max(x)-min(x)
})## [1] 1 0 1 2 1 0 1 22.13.2 lapply
Fungsi ini melakukan loop fungsi terhadap input data berupa list. Output yang dihasilkan juga merupakan list dengan panjang list yang sama dengan yang diinputkan. Format yang digunakan adalah sebagai berikut:
lapply(X, FUN, ...)Note:
- X: vektor, data frame atau list
- FUN: fungsi yang akan digunakan. Fungsi yang dapat digunakan dapat berupa fungsi dasar matematika atau statistika, serta user define function. Subset juga dimungkinkan pada fungsi ini.
- …: opsional argumen pada fungsi yang digunakan.
Berikut adalah contoh penerapan fungsi lapply:
## Membuat list
x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,FALSE,TRUE))
x # print## $a
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $beta
## [1] 0.04978707 0.13533528 0.36787944 1.00000000 2.71828183 7.38905610
## [7] 20.08553692
##
## $logic
## [1] TRUE FALSE FALSE TRUEclass(x) # cek kelas objek## [1] "list"## Menghitung nilai mean pada masing-masing baris lits
lapply(x, FUN=mean)## $a
## [1] 5.5
##
## $beta
## [1] 4.535125
##
## $logic
## [1] 0.5## Menghitung mean tiap kolom dataset iris
lapply(iris, FUN=mean)## Warning in mean.default(X[[i]], ...): argument is not numeric or logical:
## returning NA## $Sepal.Length
## [1] 5.843333
##
## $Sepal.Width
## [1] 3.057333
##
## $Petal.Length
## [1] 3.758
##
## $Petal.Width
## [1] 1.199333
##
## $Species
## [1] NA## Mengalikan elemen vektor dengan suatu nilai
y <- c(1:5)
lapply(y, FUN=function(x){x*5})## [[1]]
## [1] 5
##
## [[2]]
## [1] 10
##
## [[3]]
## [1] 15
##
## [[4]]
## [1] 20
##
## [[5]]
## [1] 25## Mengubah output menjadi vektor
unlist(lapply(y, FUN=function(x){x*5}))## [1] 5 10 15 20 252.13.3 sapply
Fungsi sapply() merupakan bentuk lain dari fungsi lapply(). Perbedaanya terletak pada output default yang dihasilkan. Secara default sapply() menerima input utama berupa list (dapat pula dataframe atau vektor), namun tidak seperti lapply() jenis data output yang dihasilkan adalah vektor. Untuk mengubah output menjadi list perlu argumen tambahan berupa simplify=FALSE. Format fungsi tersebut adalah sebagai berikut:
sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE)Note:
- X: vektor, data frame atau list
- FUN: fungsi yang akan digunakan. Fungsi yang dapat digunakan dapat berupa fungsi dasar matematika atau statistika, serta user define function. Subset juga dimungkinkan pada fungsi ini.
- …: opsional argumen pada fungsi yang digunakan.
- simplify: logical. Jika nilainya
TRUEmaka output yang dihasilkan adalah bentuk sederhana dari vektor, matrix atau array.- USE.NAMES: jika list memiliki nama pada setiap elemennya, maka nama elemen tersebut akan secara default ditampilkan.
Berikut adalah contoh penerapannya:
## membuat list
x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,FALSE,TRUE))
## menghitung nilai mean setiap elemen
sapply(x, FUN=mean)## a beta logic
## 5.500000 4.535125 0.500000## menghitung nilai mean dengan output list
sapply(x, FUN=mean, simplify=FALSE)## $a
## [1] 5.5
##
## $beta
## [1] 4.535125
##
## $logic
## [1] 0.5## summary objek dataframe
sapply(mtcars, FUN=summary)## mpg cyl disp hp drat wt qsec vs
## Min. 10.40000 4.0000 71.1000 52.0000 2.760000 1.51300 14.50000 0.0000
## 1st Qu. 15.42500 4.0000 120.8250 96.5000 3.080000 2.58125 16.89250 0.0000
## Median 19.20000 6.0000 196.3000 123.0000 3.695000 3.32500 17.71000 0.0000
## Mean 20.09062 6.1875 230.7219 146.6875 3.596563 3.21725 17.84875 0.4375
## 3rd Qu. 22.80000 8.0000 326.0000 180.0000 3.920000 3.61000 18.90000 1.0000
## Max. 33.90000 8.0000 472.0000 335.0000 4.930000 5.42400 22.90000 1.0000
## am gear carb
## Min. 0.00000 3.0000 1.0000
## 1st Qu. 0.00000 3.0000 2.0000
## Median 0.00000 4.0000 2.0000
## Mean 0.40625 3.6875 2.8125
## 3rd Qu. 1.00000 4.0000 4.0000
## Max. 1.00000 5.0000 8.0000## summary objek list
a <- list(mobil=mtcars, anggrek=iris)
sapply(a, FUN=summary)## $mobil
## mpg cyl disp hp
## Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0
## 1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5
## Median :19.20 Median :6.000 Median :196.3 Median :123.0
## Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7
## 3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0
## Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
## drat wt qsec vs
## Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
## 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
## Median :3.695 Median :3.325 Median :17.71 Median :0.0000
## Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
## 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
## Max. :4.930 Max. :5.424 Max. :22.90 Max. :1.0000
## am gear carb
## Min. :0.0000 Min. :3.000 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
## Median :0.0000 Median :4.000 Median :2.000
## Mean :0.4062 Mean :3.688 Mean :2.812
## 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
## Max. :1.0000 Max. :5.000 Max. :8.000
##
## $anggrek
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species
## setosa :50
## versicolor:50
## virginica :50
##
##
## 2.13.4 vapply
Funsgi ini merupakan bentuk lain dari sapply(). Bedanya secara kecepatan proses fungsi ini lebih cepat dari sapply(). Hal yang menarik dari fungsi ini kita dapat menambahkan argumen FUN.VALUE. pada argumen ini kita memasukkan vektor berupa output fungsi yang diinginkan. Perbedaan lainnya adalah output yang dihasilkan hanya berupa matriks atau array. Format dari fungsi ini adalah sebagai berikut:
vapply(X, FUN, FUN.VALUE, ..., USE.NAMES = TRUE)Note:
- X: vektor, data frame atau list
- FUN: fungsi yang akan digunakan. Fungsi yang dapat digunakan dapat berupa fungsi dasar matematika atau statistika, serta user define function. Subset juga dimungkinkan pada fungsi ini.
- FUN.VALUE: vektor, template dari return value FUN.
- …: opsional argumen pada fungsi yang digunakan.
- USE.NAMES: jika list memiliki nama pada setiap elemennya, maka nama elemen tersebut akan secara default ditampilkan.
Berikut adalah contoh penerapannya:
## membuat list
x <- sapply(3:9, seq)
x # print## [[1]]
## [1] 1 2 3
##
## [[2]]
## [1] 1 2 3 4
##
## [[3]]
## [1] 1 2 3 4 5
##
## [[4]]
## [1] 1 2 3 4 5 6
##
## [[5]]
## [1] 1 2 3 4 5 6 7
##
## [[6]]
## [1] 1 2 3 4 5 6 7 8
##
## [[7]]
## [1] 1 2 3 4 5 6 7 8 9## membuat ringkasan data pada tiap elemen list
vapply(x, fivenum,
c(Min. = 0, "1st Qu." = 0,
Median = 0, "3rd Qu." = 0, Max. = 0))## [,1] [,2] [,3] [,4] [,5] [,6] [,7]
## Min. 1.0 1.0 1 1.0 1.0 1.0 1
## 1st Qu. 1.5 1.5 2 2.0 2.5 2.5 3
## Median 2.0 2.5 3 3.5 4.0 4.5 5
## 3rd Qu. 2.5 3.5 4 5.0 5.5 6.5 7
## Max. 3.0 4.0 5 6.0 7.0 8.0 9## membuat ringkasan data pada tiap kolom dataframe
vapply(mtcars, summary,
c(Min. = 0, "1st Qu." = 0,
Median = 0, "3rd Qu." = 0, Max. = 0, Mean=0))## mpg cyl disp hp drat wt qsec vs
## Min. 10.40000 4.0000 71.1000 52.0000 2.760000 1.51300 14.50000 0.0000
## 1st Qu. 15.42500 4.0000 120.8250 96.5000 3.080000 2.58125 16.89250 0.0000
## Median 19.20000 6.0000 196.3000 123.0000 3.695000 3.32500 17.71000 0.0000
## 3rd Qu. 20.09062 6.1875 230.7219 146.6875 3.596563 3.21725 17.84875 0.4375
## Max. 22.80000 8.0000 326.0000 180.0000 3.920000 3.61000 18.90000 1.0000
## Mean 33.90000 8.0000 472.0000 335.0000 4.930000 5.42400 22.90000 1.0000
## am gear carb
## Min. 0.00000 3.0000 1.0000
## 1st Qu. 0.00000 3.0000 2.0000
## Median 0.00000 4.0000 2.0000
## 3rd Qu. 0.40625 3.6875 2.8125
## Max. 1.00000 4.0000 4.0000
## Mean 1.00000 5.0000 8.00002.13.5 tapply
Fungsi ini sangat berguna jika pembaca ingin menghitung suatu nilai misalnya mean berdasarkan grup data atau factor. Format fungsi ini adalah sebagi berikut:
tapply(X, INDEX, FUN = NULL, ..., simplify = TRUE)Note:
- X: vektor, data frame atau list
- INDEX: list satu atau beberapa factor yang memiliki panjang sama dengan X.
- FUN: fungsi yang akan digunakan. Fungsi yang dapat digunakan dapat berupa fungsi dasar matematika atau statistika, serta user define function. Subset juga dimungkinkan pada fungsi ini.
- …: opsional argumen pada fungsi yang digunakan.
- simplify: logical. Jika nilainya TRUE maka output yang dihasilkan adalah bentuk skalar.
Berikut adalah contoh penerapannya:
## membuat tabel frekuensi
groups <- as.factor(rbinom(32, n = 5, prob = 0.4))
tapply(groups, groups, length)## 11 12 13 14
## 1 2 1 1# atau
table(groups)## groups
## 11 12 13 14
## 1 2 1 1## membuat tabel kontingensi
# menghitung jumlah breaks berdasarkan faktor jenis wool
# dan tensi level
tapply(X=warpbreaks$breaks, INDEX=warpbreaks[,-1], FUN=sum)## tension
## wool L M H
## A 401 216 221
## B 254 259 169# menghitung mean panjang gigi babi hutan berdasarkan
# jenis suplemen dan dosisnya
tapply(ToothGrowth$len, ToothGrowth[,-1], mean)## dose
## supp 0.5 1 2
## OJ 13.23 22.70 26.06
## VC 7.98 16.77 26.14# menghitung mpg minimum berdasarkan jumlah silinder pada mobil
tapply(mtcars$mpg, mtcars$cyl, min, simplify=FALSE)## $`4`
## [1] 21.4
##
## $`6`
## [1] 17.8
##
## $`8`
## [1] 10.42.14 Loop Menggunakan map function pada Library purrr
Map function dari library purrr merupakan alternatif lain untuk melakukan looping selain dengan menggunakan for loop, while loop, atau apply family. Berbeda dengan metode tersebut, map function mempermudah proses kita dalam melakukan looping karena dapat diintegrasikan dengan fungsi-fungsi dari library tidyverse seperti dplyr, tibble, tidyr, dll, yang akan banyak penulis bahas pada Chapter selanjutnya. Selain itu, integrasi dengan library tersebut membuat setiap sintaks yang kita buat lebih mudah kita baca serta lebih cepat dalam prosesnya.
Fungsi-fungsi yang tersedia berdasarkan jenis output yang kita inginkan. Berikut adalah fungsi-fungsi map family beserta output yang dihasilkan:
map(): membuat output berupa listmap_lgl(): membuat output berupa vektor logicalmap_int(): membuat output berupa vektor integermap_dbl(): membuat output berupa vektor doublemap_chr(): membuat output berupa vektor karakter
Berikut adalah format dari fungsi-fungsi tersebut:
map(.x, .f, ...)
map_lgl(.x, .f, ...)
map_chr(.x, .f, ...)
map_int(.x, .f, ...)
map_dbl(.x, .f, ...)Note:
- .x: list atau vaktor atomik.
- .f: formula fungsi.
- …: argumen tambahan dari fungsi.
Berikut adalah contoh dari penerapan fungsi-fungsi tersebut:
library(purrr)## Warning: package 'purrr' was built under R version 3.5.3# list
map(.x=iris[,-5], .f=mean, na.rm=TRUE)## $Sepal.Length
## [1] 5.843333
##
## $Sepal.Width
## [1] 3.057333
##
## $Petal.Length
## [1] 3.758
##
## $Petal.Width
## [1] 1.199333# vektor numerik
map_dbl(.x=iris[,-5], .f=mean, na.rm=TRUE)## Sepal.Length Sepal.Width Petal.Length Petal.Width
## 5.843333 3.057333 3.758000 1.199333# vektor integer
map_int(.x=iris[,-5], length)## Sepal.Length Sepal.Width Petal.Length Petal.Width
## 150 150 150 150# vektor logical
map_lgl(.x=iris, .f=is.double)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## TRUE TRUE TRUE TRUE FALSE# vektor karakter
x <- c("Jakarta", "Bandung", "Surabaya")
map_chr(.x=x, .f=paste, "Kota")## [1] "Jakarta Kota" "Bandung Kota" "Surabaya Kota"2.15 Decision Making
Decicion Making atau sering disebut sebagai if then else statement merupakan bentuk percabagan yang digunakan manakala kita ingin agar program dapat melakukan pengujian terhadap syarat kondisi tertentu. Pada Table 5 disajikan daftar percabangan yang digunakan pada R.
Table 5 Daftar percabangan pada R
| Statement | Keterangan |
|---|---|
| if statement | if statement hanya terdiri atas sebuah ekspresi Boolean, dan diikuti satu atau lebih statement |
| if…else statement | if else statement terdiri atas beberapa buah ekspresi Boolean. Ekspressi Boolean berikutnya akan dijalankan jika ekspresi *Boolan sebelumnya bernilai FALSE |
| switch statement | switch statement digunakan untuk mengevaluasi sebuah variabel beberapa pilihan |
2.15.1 if statement
Pola if statement disajikan pada Figure 2
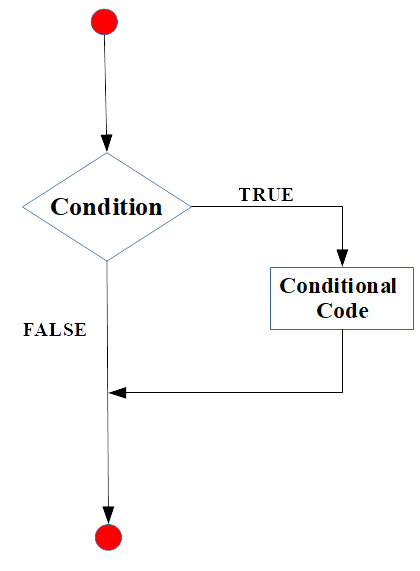
Figure 2: Diagram if statement (sumber: Primartha, 2018).
Berikut adalah contoh penerapan if statement:
x <- c(1:5)
if(is.vector(x)){
print("x adalah sebuah vector")
}## [1] "x adalah sebuah vector"2.15.2 if else statement
Pola dari if else statement disajikan pada Figure 3
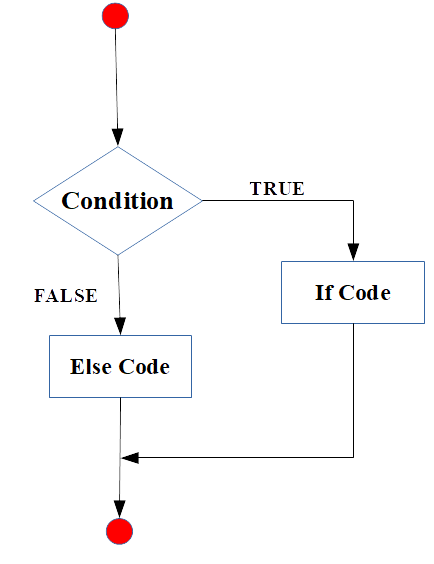
Figure 3: Diagram if else statement (sumber: Primartha, 2018).
Berikut adalah contoh penerapan if else statement:
x <- c("Andi","Iwan", "Adi")
if("Rina" %in% x){
print("Rina ditemukan")
} else if("Adi" %in% x){
print("Adi ditemukan")
} else{
print("tidak ada yang ditemukan")
}## [1] "Adi ditemukan"2.15.3 switch statement
Pola dari switch statement disajikan pada Figure 4
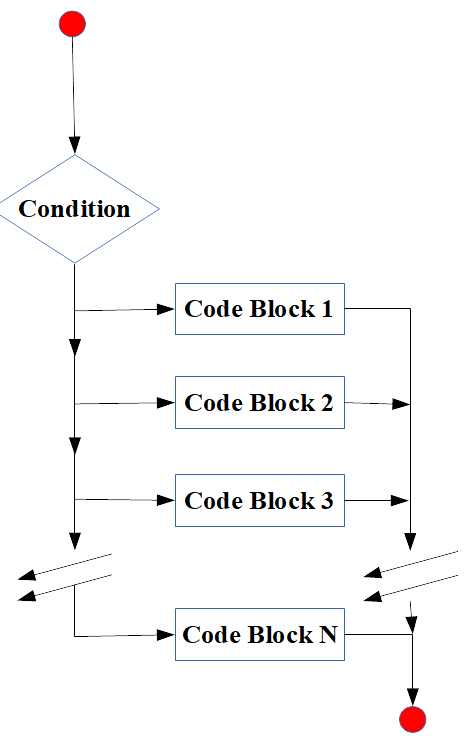
Figure 4: Diagram switch statement (sumber: Primartha, 2018).
Berikut adalah contoh penerapan switch statement:
y = 3
x = switch(
y,
"Selamat Pagi",
"Selamat Siang",
"Selamat Sore",
"Selamat Malam"
)
print(x)## [1] "Selamat Sore"2.16 Fungsi
Fungsi merupakan sekumpulan instruksi atau statement yang dapat melakukan tugas khusus. Sebagai contoh fungsi perkalian untuk menyelesaikan operasi perkalian, fungsi pemangkatan hanya untuk operasi pemangkatan, dll.
Pada R terdapat 2 jenis fungsi, yaitu: build in fuction dan user define function. build in fnction merupakan fungsi bawaan R saat pertama kita menginstall R. Contohnya adalah mean(), sum(), ls(), rm(), dll. Sedangkan user define fuction merupakan fungsi-fungsi yang dibuat sendiri oleh pengguna.
Fungsi-fungsi buatan pengguna haruslah dideklarasikan (dibuat) terlebih dahulu sebelum dapat dijalankan. Pola pembentukan fungsi adalah sebagai berikut:
function_name <- function(argument_1, argument_2, ...){
function body
}Note:
- function_name : Nama dari fungsi
R.Rakan menyimpan fungsi tersebut sebagai objek- argument_1, argument_2,… : Argument bersifat opsional (tidak wajib). Argument dapat digunakan untuk memberi inputan kepada fungsi
- function body : Merupakan inti dari fungsi. Fuction body dapat terdiri atas 0 statement (kosong) hingga banyak statement.
- return : Fungsi ada yang memiliki output atau return value ada juga yang tidak. Jika fungsi memiliki return value maka return value dapat diproses lebih lanjut
Berikut adalah contoh penerapan user define function:
# Fungsi tanpa argument
bilang <- function(){
print("Hello World!!")
}
# Print
bilang()## [1] "Hello World!!"# Fungsi dengan argumen
tambah <- function(a,b){
print(a+b)
}
# Print
tambah(5,3)## [1] 8# Fungsi dengan return value
kali <- function(a,b){
return(a*b)
}
# Print
kali(4,3)## [1] 12Referensi
- Primartha, R. 2018. Belajar Machine Learning Teori dan Praktik. Penerbit Informatika : Bandung.
- Rosadi,D. 2016. Analisis Statistika dengan R. Gadjah Mada University Press: Yogyakarta.
- STHDA. Easy R Programming Basics. http://www.sthda.com/english/wiki/easy-r-programming-basics
- Venables, W.N. Smith D.M. and R Core Team. 2018. An Introduction to R. R Manuals.
- The R Core Team. 2018. R: A Language and Environment for Statistical Computing. R Manuals.