Data manajemen merupakan bagian penting dalam setiap proses analisa data. Proses import dan eksport data pada berbagai format penting untuk dipelajari. Selain itu, proses perapihan data sebelum analisa menjadi bagian yang harus ada pada awal proses analisa. Proses-proses tersebut akan kita ulas secara mendalam pada chapter ini.Chapter ini juga akan membahas bagaimana kita dapat melakukan sejumlah manipulasi data untuk memperoleh informasi lebih yang terkandung pada.
Pada Chapter ini pembaca juga akan belajar bagaimana bekerja menggunakan tidyverse, sebuah paket yang berisi kumpulan library data science. Paket ini sangat berguna bagi pembaca khusunya pemula yang ingin bekerja dengan secara rapi dan mudah bersama R
Daftar Isi:
3.1 Tidyverse
Tidyverse merupakan kumpulan library yang dikhususkan bagi pengguna R yang ingin melakukan analisa data. Paket ini terdiri dari kumpulan berbagai library yang pada buku ini tidak akan dibahas seluruhnya. Library ini dari tidyverse antara lain:
ggplot2: library yang digunakan untuk membuat visualisasi data yang menarik yang didasarkan pada sistem Grammar of Graphics.dplyr: berisi kumpulan fungsi yang digunakan untuk melakukan manipulasi pada data dengan nama fungsi dan output yang konsisten.tidyr: library yang berisi kumpulan fungsi merapikan data atau membuat pivot table dari data.readr: library yang berfungsi untuk membaca file format .csv, .txt, .tsv, dan .fwf.purrr: library yang berguna untuk meningkatkan fuctional programming padaR. Fungsi ini telah penulis bahas secara garis besar pada Chapter 1.tibble: library yang digunakan untuk mengubah dataframe menjadi format tibble (bentuk lain dataframe yang lebih konsisten).
Selain fungsi-fungsi tersebut, masih terdapat banyak fungsi lain yang ada seperti stringr, forcats, dll.
Untuk menginstall dan menjalankan library tidyverse jalankan sintaks berikut:
install.packages("tidyverse")library(tidyverse)## Warning: package 'tidyverse' was built under R version 3.5.3## -- Attaching packages -------------------------------------- tidyverse 1.2.1 --## v ggplot2 3.1.1 v purrr 0.3.2
## v tibble 2.1.1 v dplyr 0.8.1
## v tidyr 0.8.3 v stringr 1.4.0
## v readr 1.3.1 v forcats 0.4.0## Warning: package 'ggplot2' was built under R version 3.5.3## Warning: package 'tibble' was built under R version 3.5.3## Warning: package 'tidyr' was built under R version 3.5.3## Warning: package 'readr' was built under R version 3.5.3## Warning: package 'purrr' was built under R version 3.5.3## Warning: package 'dplyr' was built under R version 3.5.3## Warning: package 'forcats' was built under R version 3.5.3## -- Conflicts ----------------------------------------- tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()3.2 Import File
Pada sesi bagian ini penulis akan menjelaskan cara mengimport file pada R. File yang diimport ke dalam R terdiri atas file yang sering digunakan pada saat akan melakukan analisis data, antara lain: TXT, CSv, Excel, SPSS, SAS, dan STATA.
Pada bagian ini akan dijelaskan pula bagaimana melakukan import data menggunakan library readr serta kelebihan dari metode import data yang digunakan. Berikut adalah cara mengimport data berbagai format pada R.
Note: Pastikan kita telah mengatur lokasi working directory pada tempat dimana lokasi file yang akan kita baca berada untuk mempermudah dalam melakukan import file.
3.2.1 Import File Menggunakan Fungsi Bawaan R
Fungsi bawaan R secara umum hanya dapat membaca data dengan format TXT dan CSV. Pada RStudio fungsi ini bertambah dengan adanya library tambahan yang telah terinstall di RStudio untuk membaca file dengan format EXCEL, SPSS, SAS dan STATA.
Secara umum fungsi yang digunakan untuk membaca data dengan format tabel seperti TXT dan CSV adalah fungsiread.table(). Berikut adalah list fungsi dasar lainnya untuk membaca file dengan format TXT dan CSV pada R:
- read.csv(): untuk membaca file dengan format comma separated value(“.csv”).
- read.csv2(): varian yang digunakan jika pada file “.csv” yang akan dibaca mengandung koma (“,”) sebagai desimal dan semicolon (“;”) sebagai pemisah antar variabel atau kolom.
- read.delim(): untuk membaca file dengan format tab-separated value(“.txt”).
- read.delim2(): membaca file dengan format “.txt” dengan tanda koma (“,”) sebagai penujuk bilangan desimal.
Masing-masing fungsi diatas dapat dituliskan kedalam R dengan format sebagai berikut:
# Membaca tabular data pada R
read.table(file, header = FALSE, sep = "", dec = ".")
# Membaca"comma separated value" files (".csv")
read.csv(file, header = TRUE, sep = ",", dec = ".", ...)
# atau gunakan read.csv2 jika tanda desimal pada data adalah "," dan pemisah kolom adalah ";"
read.csv2(file, header = TRUE, sep = ";", dec = ",", ...)
# MembacaTAB delimited files
read.delim(file, header = TRUE, sep = "\t", dec = ".", ...)
read.delim2(file, header = TRUE, sep = "\t", dec = ",", ...)Note:
- file: nama file diakhiri dengan format file (misal: “nama_file.txt”) yang akan di import ke dalam file. Dapat pula diisi lokasi file tersebut berada, misal:(C:/Users/My PC/Documents/nama_file.txt atau .csv)
- sep: pemisah antar kolom. “” digunakan untuk tab-delimited file.
- header: nilai logik. jika TRUE, maka
read.table()akan menganggap bahwa file yang akan dibaca pada baris pertama file merupakan header data.- dec: karakter yang digunakan sebagai penunjuk desimal pada data.
Untuk info lebih lanjut terkait fungsi-fungsi tersebut dan contoh bagaimana menggunakannya, pembaca dapat mengakses fitur batuan dari fungsi tersebut menggunakan sintaks berikut:
# mengakses menu bantuan
?read.table
?read.csv
?read.csv2
?read.delim
?read.delim2Misalkan penulis memiliki data pada file bernama “mtcars.csv” dengan desimal berupa titik pada datanya. Penulsi ingin membaca file tersebut, maka penulis akan menuliskan sintaks berikut:
data <- read.csv("mtcars.csv")Secara default perintah tersebut akan membaca baris pertama data sebagai header serta data berupa karakter menjadi factor. Untuk mencegah agar data berupa karakter menjadi faktor, perintah tersebut dapat ditambahkan parameter stringAsFactor = FALSE.
Kita juga dapat memilih file yang akan kita baca secara interakti. Misal pada working directory terdapat beberapa file yang akan kita baca. Kita ingin melihat file dengan format tertentu yang hendak kita baca, namun kita malas mengecek file explorer pada windows. Untuk mengatasi masalah tersebut, kita dapat menggunakan fungsi file.choose() pada R. Fungsi tersebut akan menampilkan jendela windows explores sehingga kita dapat memilih file apa yang hendak dibaca. Berikut adalah contoh penerapannya:
data <- read.csv(file.choose())Note: pastikan format file yang dibaca sama dengan fungsi import yang digunakan.
Kita juga dapat membaca file dari internet. Untuk melakukannya kit hanya perlu meng-copy url file tersebut. Berikut adalah contoh file yang dibaca dari internet:
# Membaca file dari internet
data <- read.delim("http://www.sthda.com/upload/boxplot_format.txt")
# mengecek 6 observasi awal
head(data)## Nom variable Group
## 1 IND1 10 A
## 2 IND2 7 A
## 3 IND3 20 A
## 4 IND4 14 A
## 5 IND5 14 A
## 6 IND6 12 A3.2.2 Membaca File CSV dan TXT Menggunakan Library readr
Pada bagian sebelumnya kita telah belajar bagaimana cara membaca file dengan format CSV dan TXT menggunakan paket dasar R. Pada bagian ini penulis akan menjelaskan bagaimana cara membaca file dengan format TXT dan CSV pada R menggunakan paket readr.
readr dikembangkan oleh Hadley Wickham. paket readr memberikan solusi cepat dan ramah untuk membaca delimited file ke dalam R.
Dibandingkan dengan paket dasar R, readr memiliki kelebihan sebagai berikut:
- Mampu membaca file 10x lebih cepat dibandingkan pada paket bawaan
R. - Menampilkan progress bar yang bermanfaat jika proses pemuatan berlangsung agak lama.
- semua fungsi bekerja dengan cara yang persis sama dengan paket bawaan
R.
Untuk dapat menggunakan readr, kita perlu menginstall paketnya terlebih dahulu. Untuk melakukannya jalankan sintaks berikut:
# Menginstall paket
install.packages("readr")
# Memuat paket
library(readr)Berikut adalah format bebrapa fungsi yang dapat digunakan:
# Fungsi umum (membaca TXT dan CSV) dapat juga membaca flat file dan tsv
read_delim(file, delim, col_names = TRUE)
# Membaca comma (",") separated values
read_csv(file, col_names = TRUE)
# Membaca semicolon (";") separated values
read_csv2(file, col_names = TRUE)
# Membaca tab separated values
read_tsv(file, col_names = TRUE)Note:
- file: path file, koneksi atau raw vector. File yang berakhiran .gz, .bz2, .xz, atau .zip akan secara otomatis tidak terkompresi. File yang dimulai dengan “http: //”, “https: //”, “ftp: //”, atau “ftps: //” akan diunduh secara otomatis. File gz jarak jauh juga dapat diunduh & didekompresi secara otomatis.
- delim: karakter yang membatasi tiap nilai pada file.
- col_names: nilai logik. Jika TRUE, maka baris pertama akan menjadi header.
Berikut adalah contoh bagaimana cara membaca file menggunakan fungsi pada paket readr:
# Membaca file lokal
data <- read_csv("mtcars.csv")
# atau
data <- read_csv(file.choose())
# Membaca dari internet
data <- read_tsv("http://www.sthda.com/upload/boxplot_format.txt")Kita juga dapat menspesifikasi jenis data pada kolom yang akan dibaca. Keuntungan dari penentuan jenis kolom (tipe data) akan memastikan data yang telah dibaca tidak salah berdasarkan jenis data pada masing-masing kolom.
Beberapa format jenis kolom yang tersedia pada readr adalah sebagi berikut:
- col_integer(): untuk menentukan integer (alias = “i”).
- col_double(): untuk menentukan kolom sebagai jenis data double (alias = “d”).
- col_logical(): untuk menentukan variabel logis (alias = “l”).
- col_character(): meninggalkan string apa adanya.Tidak mengonversinya menjadi faktor (alias = “c”).
- col_factor(): untuk menentukan variabel faktor (atau pengelompokan) (alias = “f”)
- col_skip(): untuk mengabaikan kolom (alias = “-” atau “_“)
- col_date() (alias = “D”), col_datetime() (alias = “T”) dan col_time() (“t”) untuk menentukan tanggal, waktu tanggal, dan waktu.
Berikut adalah contoh penerapannya:
data <- read_csv("my_file.csv", col_types = cols(
x = "i", # kolom integer
treatment = "c" # kolom karakter/string
))3.2.3 Import File Excel Pada R
Keunggulan penggunaan excel sebagai format penyimpan data adalah kita dapat menyimpan banyak data dan memisahkannya pada lembar (sheet) yang berbeda sebagai suatu data yang independen dibandingkan pembacaan pada file csv yang hanya berisikan satu tabel data saja tiap file.
Pada R kita dapat melakukan pembacaan file menggunakan berbagai macam cara seperti menggunakan paket bawaan R maupun menggunakan library yang perlu kita install. Berikut adalah beberapa cara membaca file excel pada R.
Mengkonversi terlebih dahulu satu sheet excel yang akan kita baca menjadi format “.csv” maupun “.txt” sehingga dapat dibaca seperti pada sub-bab 3.1.1.
Menyalin data dari excel dan mengimport data pada
R.
Cara ini sedikit mirip dengan cara sebelumnya, dimana kita perlu membuka file excel dan melakukan select dan copy (ctrl+c) tabel data yang hendak dibaca. Data tersebut selanjutnya akan tersimpan pada clipboard.
Data yang telah tersalin selanjutnya diimport ke R dengan mengetikkan sintaks berikut:
data <- read.table(file= "clipboard",
sep = "\t", header = TRUE)Cara ini merupakan cara yang paling sering penulis gunakan. Kelemahan penggunaan cara ini adalah ketika kita melakukan proses select dan copy (ctrl+c) tabel yang jumlahnya sangat banyak dan terdapat teks-teks penjelasan terkait tabel data pada lembar kerja excel yang tidak ingin kita sertakan akan memakan waktu yang lebih lama pada proses select.
- Mengimport data menggunakan library readxl.
Paket readxl, yang dikembangkan oleh Hadley Wickham, dapat digunakan untuk dengan mudah mengimpor file Excel (xls | xlsx) ke R tanpa ada ketergantungan eksternal.
Untuk dapat menggunakan library readxl kita harus menginstallnya terlebih dahulu menggunakan sintaks berikut:
# Instal paket
install.packages("readxl")
# memuat paket
library(readxl)Berikut adalah contoh cara mengimport data dengan format xls atau xlsx pada R.
# Tentukan sheet dengan nama sheet pada file
data <- read_excel("my_file.xlsx", sheet = "data")
# Tentukan sheet berdasarkan indeks sheet
data <- read_excel("my_file.xlsx", sheet = 2) # membaca sheet ke-2- Mengimport data menggunakan library xlsx
Paket xlsx, solusi berbasis java, adalah salah satu paket R yang ampuh untuk membaca, menulis, dan memformat file Excel. Untuk dapat menggunakannya kita harus menginstall dan memuatnya terlebih dahulu. Berikut sintaks yang digunakan:
# Menginstall paket
install.packages("xlsx")
# Memuat paket
library(xlsx)Terdapat dua buah fungsi yang disediakan pada paket tersebut yaitu read.xlsx() dan read.xlsx2(). Perbedaan keduanya adalah read.xlsx2() digunakan pada file data dengan ukuran yang besar serta proses pembacaan data yang lebih cepat dibandingkan dengan read.xlsx(). Fromat yang digunakan untuk kedua fungsi tersebut disajikan sebagai berikut:
read.xlsx(file, sheetIndex, header=TRUE)
read.xlsx2(file, sheetIndex, header=TRUE)Note:
- file: nama atau lokasi file berada
- sheetIndex: Indeks dari sheet yang hendak dibaca
- header: nilai logik. Jika bernilai TRUE, maka baris pertama dari sheet menjadi header.
Berikut adalah contoh penggunaanya:
data <- read.xlsx(file.choose(), 1) # membaca sheet 1Note: kita juga dapat membaca file dari internet seperti pada sub-bab 3.1.1.
3.2.4 Membaca File Dari Format Aplikasi Statistik
Untuk membaca file yang berasal dari format aplikasi statistik seperti SPSS, SAS, dan STATA kita perlu menginstal dan memuat paket-paket yang dibutuhkan sesuai dengan file yang akan kita install. Berikut adalah sintaks bagaimana cara mengimport file dari berbagai format aplikasi statistik.
# membaca file SPSS
install.packages("Hmisc") # menginstall paket
library(Hmisc) # memuat paket
# simpan SPSS dataset pada transport format
get file='c:\mydata.sav'.
export outfile='c:\mydata.por'.
data <- spss.get("c:\mydata.por", use.value.labels= TRUE) # use.value.labels digunakan untuk mengubah label menjadi factor
# membaca file SAS
install.packages("Hmisc") # menginstall paket
library(Hmisc) # memuat paket
# simpan SAS dataset pada transport format
libname out xport 'c:/mydata.xpt';
data out.mydata;
set sasuser.mydata;
run;
data <- sasxport.get("c:/mydata.xpt") # Variabel yang berupa karakter akan dikonversi menjadi factor
# membaca file STATA
install.packages("foreign") # menginstall paket
library(foreign) # memuat paket
data <- read.dta("c:/mydata.dta")Library haven dari paket tidyverse juga dapat digunakan untuk membacadata dari ekstensi program-program tersebut. Fungsi yang tersedia antara lain:
read_sas(): membaca format file.sas7bdat+.sas7bcatdari SAS. Fungsiread_xpt()dapat digunakan untuk membaca SAS transport files (versi 5 dan versi 8).read_sav(): membaca format file.savdari SPSS. Untuk versi file yang lebih lama (.por), kita dapat menggunakan fungsiread_por().read_dta(): Membaca format file.dtadari STATA (berfungsi hingga versi 15).
Berikut adalah sintaks untuk mengistall, memuat, dan contoh penggunaan library haven:
library(haven)
# SAS
read_sas("mtcars.sas7bdat")
# SPSS
read_sav("mtcars.sav")
# Stata
read_dta("mtcars.dta")3.3 Import Beberapa File Dalam Beberapa Baris Kode
Kita dapat melakukan import beberapa file kedalam R menggunakan beberapa baris kode. Pada contoh ini penulsi akan memberikan contoh bagaimana cara mengimport beberapa file csv yang sejenis kedalam R.
Terlebih dahulu kita perlu memuat dua buah library untuk membantu proses ini yaitu readr (membaca file) dan purrr (melakukan iterasi). Berikut adalah sintaks untuk melakukannya:
library(readr)
library(purrr)Pada contoh kali ini data yang hendak penulis import adalah data lelang kota bandung. Penulis dapat mengunduh dataset yang dibutuhkan pada tahutan berikut.
Untuk melakukan import, langkah pertama yang perlu kita lakukan adalah membuat list lokasi dari file yang akan kita import. Fungsi yang kita perlukan untuk membuat list ini adalah list.files. Format fungsi yang digunakan tersebut adalah sebagi berikut:
list.files(path = ".", pattern = NULL, full.names = FALSE)path: path (jalur) lokasi file data berada.patern: pola nama file yang hendak di import.full.names: nilai logik. JikaTRUE, jalur direktori didahului dengan nama file untuk memberikan jalur file relatif. JikaFALSE, nama file (bukan path) dikembalikan.
File yang akan penulis import terletak di folder data pada working directory. Pada contoh ini penulis akan menggunakan path relatif (biasanya didahului oleh titik dan bukan lokasi drive yang digunakan) agar pemabaca juga dapat melakukannya sendiri. File yang akan di upload memiliki pola penamaan yang sama yaitu mengandung kata lelang-bandung. Berikut adalah sintaks untuk membuat list lokasi file akan di import.
list <- list.files(path="./data", pattern="lelang-bandung", full.names=TRUE)
list## [1] "./data/001_lelang-bandung_2013.csv"
## [2] "./data/002_lelang-bandung_2014.csv"
## [3] "./data/003_lelang-bandung_2015.csv"
## [4] "./data/004_lelang-bandung_2016.csv"
## [5] "./data/005_lelang-bandung_2017.csv"Setelah lokasi file kita peroleh selanjutnya kita dapat melakukan import seluruh file sekaligus menggunakan metode iterasi.
3.3.1 for loop
Cara pertama untuk melakukan import seluruh file adalah dengan menggunakan for loop. Untuk melakukannya kita terlebih dahulu perlu membuat list kosong yang kan menyimpan hasil loop yang kita lakukan. Untuk melakukannya kita perlu menggunakan fungsi vector(). Format fungsi tersebut adalah sebagi berikut:
vector(mode = "logical", length = 0)mode: jenis file yang hendak dibuat.length: panjang file yang hendak dibuat.
Berikut adalah sintaks yang digunakan:
# print list lokasi file
list## [1] "./data/001_lelang-bandung_2013.csv"
## [2] "./data/002_lelang-bandung_2014.csv"
## [3] "./data/003_lelang-bandung_2015.csv"
## [4] "./data/004_lelang-bandung_2016.csv"
## [5] "./data/005_lelang-bandung_2017.csv"# membuat list kosong
output_for <- vector(mode="list", length=length(list))
# for looop
for (i in seq_along(output_for)) {
output_for[[i]] <- read_csv(list[[i]])
}## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_logical(),
## tanggal_pembuatan = col_date(format = ""),
## keterangan = col_logical(),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## keterangan = col_logical(),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## keterangan = col_logical(),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_double(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.# print hasil for loops
output_for## [[1]]
## # A tibble: 680 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <lgl> <date> <lgl>
## 1 5260 J5-Peningk~ NA 2013-02-19 NA
## 2 171260 B2-Peningk~ NA 2013-02-21 NA
## 3 374260 J126-Penin~ NA 2013-04-24 NA
## 4 452260 J140-Penin~ NA 2013-05-19 NA
## 5 521260 Belanja Mo~ NA 2013-05-20 NA
## 6 571260 Pengadaan ~ NA 2013-06-11 NA
## 7 727260 Pembanguna~ NA 2013-08-07 NA
## 8 628260 SS-06 Bang~ NA 2013-06-25 NA
## 9 772260 Belanja Mo~ NA 2013-08-13 NA
## 10 889260 PKP1-Penga~ NA 2013-09-18 NA
## # ... with 670 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <lgl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>
##
## [[2]]
## # A tibble: 763 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <dbl> <date> <lgl>
## 1 1002260 Jasa Konsu~ NA 2014-02-21 NA
## 2 1003260 Jasa Konsu~ 625017 2014-02-21 NA
## 3 1008260 Pengoperas~ NA 2014-03-03 NA
## 4 1007260 Pengoperas~ NA 2014-03-03 NA
## 5 1009260 Jasa Konsu~ 792674 2014-03-10 NA
## 6 1013260 Kajian Mod~ NA 2014-03-12 NA
## 7 1014260 Belanja Pr~ NA 2014-03-14 NA
## 8 1016260 Jasa Tenag~ NA 2014-03-18 NA
## 9 1015260 Jasa Konsu~ NA 2014-03-18 NA
## 10 1017260 Jasa Tenag~ NA 2014-03-18 NA
## # ... with 753 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <lgl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>
##
## [[3]]
## # A tibble: 638 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <dbl> <date> <lgl>
## 1 2161260 Belanja Ba~ NA 2015-01-06 NA
## 2 2164260 Pengadaan ~ 2558197 2015-02-09 NA
## 3 2166260 Perawatan ~ NA 2015-02-10 NA
## 4 2165260 Perawatan ~ NA 2015-02-10 NA
## 5 2163260 "Pengadaan~ 2837522 2015-02-12 NA
## 6 2173260 Peningkata~ 3024560 2015-02-17 NA
## 7 2174260 Peningkata~ 3024515 2015-02-17 NA
## 8 2178260 Peningkata~ 3024663 2015-02-17 NA
## 9 2172260 Peningkata~ 3024534 2015-02-17 NA
## 10 2167260 Peningkata~ 3024431 2015-02-17 NA
## # ... with 628 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <lgl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>
##
## [[4]]
## # A tibble: 785 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <dbl> <date> <chr>
## 1 2994260 Belanja Ba~ 5035789 2015-12-11 <NA>
## 2 2995260 Belanja Ja~ 5026929 2015-12-11 <NA>
## 3 2996260 Belanja Ma~ 5027086 2015-12-11 <NA>
## 4 2997260 Belanja Ja~ 5027006 2015-12-11 <NA>
## 5 2998260 Belanja Ja~ 5037194 2015-12-11 <NA>
## 6 2999260 Belanja Ja~ 5037172 2015-12-11 <NA>
## 7 3000260 Belanja Ja~ 5037210 2015-12-11 <NA>
## 8 3007260 Jasa Penga~ 5054575 2015-12-11 <NA>
## 9 3013260 Penyediaan~ 5057427 2015-12-11 <NA>
## 10 3014260 Pengadaan ~ 5043143 2016-01-12 <NA>
## # ... with 775 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <lgl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>
##
## [[5]]
## # A tibble: 414 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <dbl> <date> <chr>
## 1 4542260 Pengadaan ~ 11633430 2017-09-08 <NA>
## 2 4135260 Belanja Al~ 11005893 2017-05-03 <NA>
## 3 4244260 Belanja Ja~ 11367750 2017-06-09 <NA>
## 4 4462260 Belanja Ja~ 12437947 2017-08-11 <NA>
## 5 4393260 Belanja Ja~ 11999277 2017-07-27 <NA>
## 6 4231260 Belanja ja~ 12162438 2017-05-31 <NA>
## 7 4233260 Belanja ja~ 12156963 2017-05-31 <NA>
## 8 4234260 Belanja ja~ 12150139 2017-05-31 <NA>
## 9 4232260 Belanja ja~ 12150318 2017-05-31 <NA>
## 10 4238260 Belanja ja~ 12156804 2017-05-31 <NA>
## # ... with 404 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <dbl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>File kita inginkan telah kita import seluruhnya. Kita dapat membuat objek tunggal pada masing-masing dataset tersebut atau menggabungkannya menjadi satu dataset jika data tersebut merupakan data yang sama (menjelaskan hal yang sama). Misalkan kita ingin menyimpan dataset pertama kedalam objek dengan nama list1, kita dapat melakukan subset seperti berikut:
list1 <- output_for[[1]]
# subset kolom 1 baris 1
list1[1,1]## # A tibble: 1 x 1
## kode_lelang
## <dbl>
## 1 5260Kita dapat juga menggabungkan list output_for menjadi satu data frame utuh menggunakan fungsi rbind (menggabungkan baris data) karena dataset pada list tersebut memiliki kolom yang sama. Untuk mengefisienkan proses tersebut atau agar kita tidak mengabungkannya satu-persatu kita dapat menggunakan fungsi Reduce(). Format fungsi tersebut adalah sebagai berikut:
Reduce(f, x)Note:
- f: fungsi yang digunakan.
- length: objek (vektor, list, data frame, dan matriks) yang hendak dikenai fungsi.
Berikut adalah sintaks yang digunakan:
df_for <- Reduce(f=rbind, x=output_for)
# print
df_for## # A tibble: 3,280 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <dbl> <date> <chr>
## 1 5260 J5-Peningk~ NA 2013-02-19 <NA>
## 2 171260 B2-Peningk~ NA 2013-02-21 <NA>
## 3 374260 J126-Penin~ NA 2013-04-24 <NA>
## 4 452260 J140-Penin~ NA 2013-05-19 <NA>
## 5 521260 Belanja Mo~ NA 2013-05-20 <NA>
## 6 571260 Pengadaan ~ NA 2013-06-11 <NA>
## 7 727260 Pembanguna~ NA 2013-08-07 <NA>
## 8 628260 SS-06 Bang~ NA 2013-06-25 <NA>
## 9 772260 Belanja Mo~ NA 2013-08-13 <NA>
## 10 889260 PKP1-Penga~ NA 2013-09-18 <NA>
## # ... with 3,270 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <dbl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>3.3.2 Apply Family Function
Dibandingkan dengan metode for loops, metode ini menggunakan sedikit baris kolom. Pada metode sebelumnya kita perlu menuliskan iterasi for loop dengan beberapa baris kolom. Pada metode ini kita akan menggunakan sebuah fungsi untuk mengimport file yaitu lapply(). Fungsi ini telah kita bahas pada Chapter sebelumnya, dimana fungsi ini melakukan iterasi suatu fungsi terhadap objek input berupa list (dapat pula vektor atau data frame) dan menghasilkan output list. Berikut adalah sintaks yang digunakan untuk melakukan import data:
# list lokasi berkas
list## [1] "./data/001_lelang-bandung_2013.csv"
## [2] "./data/002_lelang-bandung_2014.csv"
## [3] "./data/003_lelang-bandung_2015.csv"
## [4] "./data/004_lelang-bandung_2016.csv"
## [5] "./data/005_lelang-bandung_2017.csv"# lapply function
output_lapply <- lapply(X=list, FUN=read_csv)## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_logical(),
## tanggal_pembuatan = col_date(format = ""),
## keterangan = col_logical(),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## keterangan = col_logical(),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## keterangan = col_logical(),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_double(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.# print
output_lapply## [[1]]
## # A tibble: 680 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <lgl> <date> <lgl>
## 1 5260 J5-Peningk~ NA 2013-02-19 NA
## 2 171260 B2-Peningk~ NA 2013-02-21 NA
## 3 374260 J126-Penin~ NA 2013-04-24 NA
## 4 452260 J140-Penin~ NA 2013-05-19 NA
## 5 521260 Belanja Mo~ NA 2013-05-20 NA
## 6 571260 Pengadaan ~ NA 2013-06-11 NA
## 7 727260 Pembanguna~ NA 2013-08-07 NA
## 8 628260 SS-06 Bang~ NA 2013-06-25 NA
## 9 772260 Belanja Mo~ NA 2013-08-13 NA
## 10 889260 PKP1-Penga~ NA 2013-09-18 NA
## # ... with 670 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <lgl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>
##
## [[2]]
## # A tibble: 763 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <dbl> <date> <lgl>
## 1 1002260 Jasa Konsu~ NA 2014-02-21 NA
## 2 1003260 Jasa Konsu~ 625017 2014-02-21 NA
## 3 1008260 Pengoperas~ NA 2014-03-03 NA
## 4 1007260 Pengoperas~ NA 2014-03-03 NA
## 5 1009260 Jasa Konsu~ 792674 2014-03-10 NA
## 6 1013260 Kajian Mod~ NA 2014-03-12 NA
## 7 1014260 Belanja Pr~ NA 2014-03-14 NA
## 8 1016260 Jasa Tenag~ NA 2014-03-18 NA
## 9 1015260 Jasa Konsu~ NA 2014-03-18 NA
## 10 1017260 Jasa Tenag~ NA 2014-03-18 NA
## # ... with 753 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <lgl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>
##
## [[3]]
## # A tibble: 638 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <dbl> <date> <lgl>
## 1 2161260 Belanja Ba~ NA 2015-01-06 NA
## 2 2164260 Pengadaan ~ 2558197 2015-02-09 NA
## 3 2166260 Perawatan ~ NA 2015-02-10 NA
## 4 2165260 Perawatan ~ NA 2015-02-10 NA
## 5 2163260 "Pengadaan~ 2837522 2015-02-12 NA
## 6 2173260 Peningkata~ 3024560 2015-02-17 NA
## 7 2174260 Peningkata~ 3024515 2015-02-17 NA
## 8 2178260 Peningkata~ 3024663 2015-02-17 NA
## 9 2172260 Peningkata~ 3024534 2015-02-17 NA
## 10 2167260 Peningkata~ 3024431 2015-02-17 NA
## # ... with 628 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <lgl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>
##
## [[4]]
## # A tibble: 785 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <dbl> <date> <chr>
## 1 2994260 Belanja Ba~ 5035789 2015-12-11 <NA>
## 2 2995260 Belanja Ja~ 5026929 2015-12-11 <NA>
## 3 2996260 Belanja Ma~ 5027086 2015-12-11 <NA>
## 4 2997260 Belanja Ja~ 5027006 2015-12-11 <NA>
## 5 2998260 Belanja Ja~ 5037194 2015-12-11 <NA>
## 6 2999260 Belanja Ja~ 5037172 2015-12-11 <NA>
## 7 3000260 Belanja Ja~ 5037210 2015-12-11 <NA>
## 8 3007260 Jasa Penga~ 5054575 2015-12-11 <NA>
## 9 3013260 Penyediaan~ 5057427 2015-12-11 <NA>
## 10 3014260 Pengadaan ~ 5043143 2016-01-12 <NA>
## # ... with 775 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <lgl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>
##
## [[5]]
## # A tibble: 414 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <dbl> <date> <chr>
## 1 4542260 Pengadaan ~ 11633430 2017-09-08 <NA>
## 2 4135260 Belanja Al~ 11005893 2017-05-03 <NA>
## 3 4244260 Belanja Ja~ 11367750 2017-06-09 <NA>
## 4 4462260 Belanja Ja~ 12437947 2017-08-11 <NA>
## 5 4393260 Belanja Ja~ 11999277 2017-07-27 <NA>
## 6 4231260 Belanja ja~ 12162438 2017-05-31 <NA>
## 7 4233260 Belanja ja~ 12156963 2017-05-31 <NA>
## 8 4234260 Belanja ja~ 12150139 2017-05-31 <NA>
## 9 4232260 Belanja ja~ 12150318 2017-05-31 <NA>
## 10 4238260 Belanja ja~ 12156804 2017-05-31 <NA>
## # ... with 404 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <dbl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>Seperti sebelumnya kita akan menggabungkan dataset pada list yang dihasilkan menggunakan fungsi Reduce(). Berikut adalah sintaks yang digunakan:
df_lapply <- Reduce(rbind,output_lapply)
# print
head(df_lapply)
# cek apakah output for dan lapply seragam
identical(df_for, df_lapply)3.3.3 Map Family Function
Terakhir, Anda akan melakukan impor data dengan menggunakan keluarga map dari paket purrr. Adapun fungsi yang akan digunakan adalah map_dfr. Fungsi ini menerima input list berisi lokasi file berada. Fungsi ini selanjutnya membaca sekaligus menggabungkan file yang telah dibaca dengan menambahkan fungsi read_csv. File akan digabungkan berdasarkan baris. Untuk file yang ingi digabungkan secara menyamping (berdasarkan kolom) dapat menggunakan fungsi map_dfc. Struktur penulisan kode di keluarga map serupa dengan penulisan kode di keluarga apply, yaitu sebagai berikut:
library(purrr) # aktifkan paket purrr
list## [1] "./data/001_lelang-bandung_2013.csv"
## [2] "./data/002_lelang-bandung_2014.csv"
## [3] "./data/003_lelang-bandung_2015.csv"
## [4] "./data/004_lelang-bandung_2016.csv"
## [5] "./data/005_lelang-bandung_2017.csv"output_map <- map_dfr(list, read_csv)## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_logical(),
## tanggal_pembuatan = col_date(format = ""),
## keterangan = col_logical(),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## keterangan = col_logical(),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## keterangan = col_logical(),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_logical(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.## Parsed with column specification:
## cols(
## .default = col_character(),
## kode_lelang = col_double(),
## kode_rup = col_double(),
## tanggal_pembuatan = col_date(format = ""),
## tahun = col_double(),
## pagu = col_double(),
## hps = col_double(),
## peserta_lelang = col_double(),
## hasil_negosiasi = col_double(),
## harga_penawaran = col_double(),
## harga_terkoreksi = col_double()
## )## See spec(...) for full column specifications.output_map## # A tibble: 3,280 x 32
## kode_lelang nama_lelang kode_rup tanggal_pembuat~ keterangan
## <dbl> <chr> <dbl> <date> <chr>
## 1 5260 J5-Peningk~ NA 2013-02-19 <NA>
## 2 171260 B2-Peningk~ NA 2013-02-21 <NA>
## 3 374260 J126-Penin~ NA 2013-04-24 <NA>
## 4 452260 J140-Penin~ NA 2013-05-19 <NA>
## 5 521260 Belanja Mo~ NA 2013-05-20 <NA>
## 6 571260 Pengadaan ~ NA 2013-06-11 <NA>
## 7 727260 Pembanguna~ NA 2013-08-07 <NA>
## 8 628260 SS-06 Bang~ NA 2013-06-25 <NA>
## 9 772260 Belanja Mo~ NA 2013-08-13 <NA>
## 10 889260 PKP1-Penga~ NA 2013-09-18 <NA>
## # ... with 3,270 more rows, and 27 more variables: tahapan_lelang <chr>,
## # instansi <chr>, satuan_kerja <chr>, kategori <chr>,
## # metode_pengadaan <chr>, metode_kualifikasi <chr>,
## # metode_dokumen <chr>, metode_evaluasi <chr>, tahun_anggaran <chr>,
## # tahun <dbl>, pagu <dbl>, hps <dbl>, cara_pembayaran <chr>,
## # pembebanan_ta <chr>, sumber_pendanaan <chr>, lokasi <chr>,
## # kualifikasi_usaha <chr>, peserta_lelang <dbl>, agency <chr>,
## # satker <chr>, nama_pemenang <chr>, alamat <chr>, npwp <chr>,
## # hasil_negosiasi <dbl>, harga_penawaran <dbl>, harga_terkoreksi <dbl>,
## # gagal_lelang <chr>class(output_map)## [1] "spec_tbl_df" "tbl_df" "tbl" "data.frame"3.4 Eksport File
Setelah kita melakukan analisa dan telah memperoleh hasil yang kita inginkan dan memperoleh data frame berupa hasil prediksi suatu model atau data yang telah dibersihakan, kita ingin melakukan pelaporan dalam bentuk file dengan format seperti EXCEL, CSV atau TXT. Untuk melakukannya kita perlu melakukan eksport data yang telah dihasilkan.
Pada bagian ini penulis akan menjelaskan bagaimana cara mengeksport data dari R kedalam format TXT, CSV, maupun EXCEL. Sebenarnya R memungkinkan untuk melakukan eksport dalam format lain seperti RDA maupun RDS yang tidak dibahas dalam buku ini karena berada diluar lingkup buku ini.
3.4.1 Eksport Data Menjadi Format TXT dan CSV
Terdapat dua cara untuk melakukan ekport data dari R menjadi format TXT atau CSV, yaitu melalui paket dasar R maupun menggunakan library readr. Kedua cara tersebut memiliki sejumlah kemiripan dari segi fungsi, namun berbeda dari segi kecepatan eksport.
Fungsi dasar yang digunakan pada R untuk melakukan eksport file kedalam format TXT dan CSv adalah write.tabel(). Format umum yang digunakan adalah sebagai berikut:
write.table(x, file, sep= " ", dec = ",",
row.names = TRUE, col.names = TRUE)Note:
- x: matriks atau data frame yang akan ditulis.
- file: karakter yang menentukan nama file yang dihasilkan.
- sep: string pemisah bidang atau kolom, mis., sep = “ t” (untuk nilai yang dipisahkan tab).
- dec: string yang akan digunakan sebagai pemisah desimal. Standarnya adalah “.”.
- row.names: nilai logik yang menunjukkan apakah nama baris x harus ditulis bersama dengan x, atau vektor karakter nama baris yang akan ditulis.
- col.names: baik nilai logik yang menunjukkan apakah nama kolom x harus ditulis bersama dengan x, atau vektor karakter nama kolom yang akan ditulis. Jika
col.names = NAdanrow.names = TRUEditambahkan nama kolom kosong, yang merupakan konvensi yang digunakan untuk file CSV untuk dibaca oleh spreadsheet.
Selain menggunakan fungsi tersebut, untuk eksport ke dalam format CSV juga dapa menggunakan fungsi write.csv() atau write.csv2(). Berikut adalah format yang digunakan:
write.csv(data, file="data.csv")
write.csv2(data, file="data.csv")Secara penampakan kedua fungsi tersebut pada dasarnya sama dengan fungsi write.table(), bedanya adalah kedua fungsi tersebut spesifik digunakan untuk eksport file kedalam format CSV.
Note:
- write.csv() menggunakan “.” sebagai titik desimal serta “,” sebagai pemisah antar kolom data.
- write.csv2() menggunakan “,” sebagai titik desimal serta “;” sebagai pemisah antar kolom data.
Misalkan kita ingin melakukan eksport data objek mtcars kedalam format CSV. Untuk melakukannya dapat dilakukan dengan sintaks berikut:
write.csv(mtcars, file="mtcars.csv", row.names = FALSE)Note: Hasil ekspoet ditampilkan pada working directory
Kita juga dapat menggunakan fungsi write_delim() dari library readr untuk melakukan eksport data kedalam format CSV atau TXT. Berdasarkan format file yang hendak dihasilkan kita juga dapat menggunakan fungsi write_csv() atau write_tsv(). Berikut adalah penjelasan terkait kedua fungsi tersebut:
- write_csv(): untuk mengeksport kedalam format CSV.
- write_tsv(): untuk mengeksport kedalam format TXT.
Format sederhana ketiga fungsi fungsi tersebut adalah sebagai berikut:
# Fungsi umum
write_delim(x, path, delim = " ")
# Write comma (",") separated value files
write_csv(file, path)
# Write tab ("\t") separated value files
write_tsv(file, path)Note:
- x: data frame yang akan ditulis
- path: path ke file hasil (dapat berupa nama file disertai ekstensi file yang akan dibuat)
- delim: Delimiter digunakan untuk memisahkan nilai. Harus karakter tunggal.
Berikut adalah contoh penerapan dari fungsi tersebut:
# memuat mtcars data
data(mtcars)
library(readr)
# eksport mtcars menjadi tsv atau txt
write_tsv(mtcars, path = "mtcars.txt")
# eksport mycars menjadi csv
write_csv(mtcars, path = "mtcars.csv")3.4.2 Eksport Data Menjadi Format Excel
Untuk mengeksport data menjadi format EXCEL (“.xls” atau “.xlsx”) kita dapat menggunakan fungsi write.xlsx() dan write.xlsx2() dari library xlsx. Berikut adalah format sederhana yanga digunakan:
write.xlsx(x, file, sheetName = "Sheet1",
col.names = TRUE, row.names = TRUE, append = FALSE)
write.xlsx2(x, file, sheetName = "Sheet1",
col.names = TRUE, row.names = TRUE, append = FALSE)Note:
- x: sebuah data frame untuk ditulis ke dalam worksheet.
- file: path ke file output.
- sheetName: string karakter yang digunakan untuk nama sheet.
- col.names, row.names: nilai logik yang menentukan apakah nama kolom / nama baris x akan ditulis ke file.
- append: nilai logis yang menunjukkan apakah x harus ditambahkan ke file yang ada.
Berikut adalah contoh penerapannya:
library("xlsx")
# Menuliskan dataset pertama pada workbook
write.xlsx(USArrests, file = "myworkbook.xlsx",
sheetName = "USA-ARRESTS", append = FALSE)
# Menambahkan dataset kedua pada workbook
write.xlsx(mtcars, file = "myworkbook.xlsx",
sheetName="MTCARS", append=TRUE)
# Menambahkan dataset kedua pada workbook
write.xlsx(iris, file = "myworkbook.xlsx",
sheetName="IRIS", append=TRUE)3.4.3 Eksport File Dalam Format SAS, SPSS, dan STATA
Untuk memgeksport file dalam format seperti .sas7bdat, .sav, atau .dta, kita dapat menggunakan library haven dari paket tidyverse. Berikut adalah contoh sintaks untuk melakukannya:
library(haven)
# SAS
write_sas(mtcars, "mtcars.sas7bdat")
# SPSS
write_sav(mtcars, "mtcars.sav")
# Stata
write_dta(mtcars, "mtcars.dta")3.5 Tibble Data Format
Tibble adalah data frame yang menyediakan metode print yang lebih bagus, berguna saat bekerja dengan kumpulan data besar. Pada bagian ini penulis akan menjelaskan penggunaan tibble sebagai alternatif kita dalam berinteraksi dengan data frame.
Untuk membuat tibble kita perlu menginstall dan memuat library tibble yang dikembangkan oleh Hadley Wichham. Berikut adalah sintaks yang digunakan:
# menginstall paket
install.packages("tibble")
# memuat paket
library(tibble)3.5.1 Membuat Tibble
Untuk dapat membuat tibble kita dapat melakukan konversi data frame yang sudah ada menjadi tibble menggunakan fungsi as_tibble(). Berikut adalah contoh bagaimana membuat tibble mengunakan data iris:
# memuat data mtcars
data("iris")
# print
head(iris, 10)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa# konversi mtcars menjadi tibble
iris_tbl <- as_tibble(iris)
# print
iris_tbl## # A tibble: 150 x 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <fct>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 140 more rowsNote: Kita dapat mengkonversi tibble menjadi data frame menggunakan fungsi
as.data.frame()
Secara default saya kita print tibble, maka akan dimunculkan 10 observasi pertama. Pada data frame biasa jika kita print data tersebut maka seluruh observasi akan ditampilkan.
Penggunaan tibble ini cenderung menguntungkan saat kita bekerja dengan jumlah data yang besar dan ingin mengecek observasi yang ada. Hal ini berbeda dengan data frame biasa dimana untuk mengecek observasi awal kita perlu menggunakan fungsi head() agar seluruh data tidak ditampilkan. Sehingga penggunaan tibble cenderung membuat proses analisa menjadi lebih rapi.
Kita juga dapat membuat tibble dari kumpulan sejumlah vektor menggunakan fungsi tibble(). tibble() akan secara otomatis mendaur ulang input dengan panjang 1 (variabel y), dan memungkinkan kita untuk merujuk ke variabel yang baru saja kita buat, seperti yang ditunjukkan pada sintaks berikut:
tibble(
x = 1:20,
y = 1,
z = 2*x+5*y
)## # A tibble: 20 x 3
## x y z
## <int> <dbl> <dbl>
## 1 1 1 7
## 2 2 1 9
## 3 3 1 11
## 4 4 1 13
## 5 5 1 15
## 6 6 1 17
## 7 7 1 19
## 8 8 1 21
## 9 9 1 23
## 10 10 1 25
## 11 11 1 27
## 12 12 1 29
## 13 13 1 31
## 14 14 1 33
## 15 15 1 35
## 16 16 1 37
## 17 17 1 39
## 18 18 1 41
## 19 19 1 43
## 20 20 1 45Jika pembaca telah mulai familiar dengan fungsi data.frame(), perlu diingat bahwa tibble() melakukan lebih sedikit: tidak pernah mengubah jenis input (mis., tidak pernah mengubah string menjadi faktor!), tidak pernah mengubah nama variabel, dan tidak pernah membuat nama baris seperti yang biasa terjadi saat kita menggunakan fungsi data.frame().
Cara lain yang dapat digunakan untuk membuat tibble adalah dengan menggunakan fungsi tribble() yang merupakan singkatan dari transposed tibble. tribble() dikustomisasi untuk entri data dalam kode: judul kolom didefinisikan oleh rumus (yaitu, mereka mulai dengan ~), dan entri dipisahkan oleh koma. Hal ini memungkinkan untuk menata sejumlah kecil data dalam bentuk yang mudah dibaca. Berikut adalah contoh penerapannya:
tribble(
~x, ~y, ~z,
#--/--/----
"a", 2, 5,
"b", 5, 7
)## # A tibble: 2 x 3
## x y z
## <chr> <dbl> <dbl>
## 1 a 2 5
## 2 b 5 7Penambahahan komen (#–/–/—-) dilakukan untuk memperjelas posisi dari header sehingga meminimalisir kesalahan dalam input data.
3.5.2 Tibble vs Data Frame
terdapat dua buah perbedaan utama antara tibble dan data frame , yaitu: printing dan subsetting.
- Printing
Tibbles memiliki metode print halus yang hanya menampilkan 10 baris pertama observasi, dan semua kolom yang sesuai dengan lebar layar. Ini membuatnya lebih mudah untuk bekerja dengan data besar. Selain namanya, setiap kolom melaporkan jenis datanya, fitur bagus yang dipinjam dari fungsi str(). Berikut adalah contohnya:
tribble(
~x, ~y, ~z,
#--/---/--------
"a", 2.1, FALSE,
"b", 5.5, TRUE
)## # A tibble: 2 x 3
## x y z
## <chr> <dbl> <lgl>
## 1 a 2.1 FALSE
## 2 b 5.5 TRUETibbles dirancang agar kita tidak secara sengaja menampilkan data yang sangat banyak saat melakukan perintah print(). Tetapi terkadang kita membutuhkan lebih banyak output daripada tampilan default. Ada beberapa opsi yang dapat membantu.
Pertama, kita dapat secara eksplisit melakukan print data frame dan mengontrol jumlah baris (n) dan lebar tampilan. width = Inf akan menampilkan semua kolom. Berikut adalah contoh penerapannya
print(iris_tbl, n=15, width=Inf)## # A tibble: 150 x 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <fct>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## 11 5.4 3.7 1.5 0.2 setosa
## 12 4.8 3.4 1.6 0.2 setosa
## 13 4.8 3 1.4 0.1 setosa
## 14 4.3 3 1.1 0.1 setosa
## 15 5.8 4 1.2 0.2 setosa
## # ... with 135 more rowsKita juga dapat mengontrol print default dengan melakukan pengaturan menggunakan fungsi options(). Berikut adalah contoh penerapannya:
- options(tibble.print_max= n, tibble.print_min= m): jika terdapat lebih dari “m” baris, print hanya sejumlah “n” baris.
- options(dplyr.print_min = Inf): untuk selalu menampilkan seluruh baris. Perlu diingat fungsi ini dapat digunakan saat kita telah memuat library
dplyr. - options(tibble.width = Inf): menampilkan seluruh kolom tanpa mempedulikan lebar tampilan layar.
Cara terakhir untuk menampilkan seluruh observasi adalh dengan fungsi view(). Berikut adalah contoh penerapannya pada data iris_tbl:
view(iris_tbl)- Subsetting
Sejauh ini semua alat yang kita pelajari telah bekerja dengan data frame yang lengkap. Jika kita ingin mengeluarkan variabel tunggal, kita memerlukan beberapa alat baru, dollar sign ($) dan [[. [[dapat mengekstraksi berdasarkan nama atau posisi; $ hanya mengekstraksi berdasarkan nama. Berikut adalah contoh penerapannya:
# print tibble
iris_tbl## # A tibble: 150 x 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <fct>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 140 more rows# subset berdasarkan nama kolom
iris_tbl$Sepal.Length## [1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7 5.4
## [18] 5.1 5.7 5.1 5.4 5.1 4.6 5.1 4.8 5.0 5.0 5.2 5.2 4.7 4.8 5.4 5.2 5.5
## [35] 4.9 5.0 5.5 4.9 4.4 5.1 5.0 4.5 4.4 5.0 5.1 4.8 5.1 4.6 5.3 5.0 7.0
## [52] 6.4 6.9 5.5 6.5 5.7 6.3 4.9 6.6 5.2 5.0 5.9 6.0 6.1 5.6 6.7 5.6 5.8
## [69] 6.2 5.6 5.9 6.1 6.3 6.1 6.4 6.6 6.8 6.7 6.0 5.7 5.5 5.5 5.8 6.0 5.4
## [86] 6.0 6.7 6.3 5.6 5.5 5.5 6.1 5.8 5.0 5.6 5.7 5.7 6.2 5.1 5.7 6.3 5.8
## [103] 7.1 6.3 6.5 7.6 4.9 7.3 6.7 7.2 6.5 6.4 6.8 5.7 5.8 6.4 6.5 7.7 7.7
## [120] 6.0 6.9 5.6 7.7 6.3 6.7 7.2 6.2 6.1 6.4 7.2 7.4 7.9 6.4 6.3 6.1 7.7
## [137] 6.3 6.4 6.0 6.9 6.7 6.9 5.8 6.8 6.7 6.7 6.3 6.5 6.2 5.9#subset berdasarkan posisi
iris_tbl[[1]]## [1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7 5.4
## [18] 5.1 5.7 5.1 5.4 5.1 4.6 5.1 4.8 5.0 5.0 5.2 5.2 4.7 4.8 5.4 5.2 5.5
## [35] 4.9 5.0 5.5 4.9 4.4 5.1 5.0 4.5 4.4 5.0 5.1 4.8 5.1 4.6 5.3 5.0 7.0
## [52] 6.4 6.9 5.5 6.5 5.7 6.3 4.9 6.6 5.2 5.0 5.9 6.0 6.1 5.6 6.7 5.6 5.8
## [69] 6.2 5.6 5.9 6.1 6.3 6.1 6.4 6.6 6.8 6.7 6.0 5.7 5.5 5.5 5.8 6.0 5.4
## [86] 6.0 6.7 6.3 5.6 5.5 5.5 6.1 5.8 5.0 5.6 5.7 5.7 6.2 5.1 5.7 6.3 5.8
## [103] 7.1 6.3 6.5 7.6 4.9 7.3 6.7 7.2 6.5 6.4 6.8 5.7 5.8 6.4 6.5 7.7 7.7
## [120] 6.0 6.9 5.6 7.7 6.3 6.7 7.2 6.2 6.1 6.4 7.2 7.4 7.9 6.4 6.3 6.1 7.7
## [137] 6.3 6.4 6.0 6.9 6.7 6.9 5.8 6.8 6.7 6.7 6.3 6.5 6.2 5.9Dibandingkan dengan data frame, tibble lebih ketat: tibble tidak pernah melakukan partial matching, dan mereka akan menghasilkan peringatan jika kolom yang kita coba akses tidak ada.
3.6 Merapikan Data
Sebelum memulai analisa terhadap data yang kita miliki, umumnya kita akan merapikan data yang akan kita gunakan. Tujuannya adalah agar data yang akan digunakan sudah siap untuk dilakukan analisa dengan software tertentu seperti R, dimana pada dataset perlu jelas antara variabel dan nilai (value), serta untuk mempermudah dalah memperoleh informasi pada data. Berikut adalah beberapa contoh dataset yang dapat pembaca cermati terkait manakah data yang telah rapi (tidy data) dan mana yang belum (messy data):
table1 ## # A tibble: 6 x 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583table2 ## # A tibble: 12 x 4
## country year type count
## <chr> <int> <chr> <int>
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583table3 ## # A tibble: 6 x 3
## country year rate
## * <chr> <int> <chr>
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583table4a ## # A tibble: 3 x 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766table4b ## # A tibble: 3 x 3
## country `1999` `2000`
## * <chr> <int> <int>
## 1 Afghanistan 19987071 20595360
## 2 Brazil 172006362 174504898
## 3 China 1272915272 1280428583table5 ## # A tibble: 6 x 4
## country century year rate
## * <chr> <chr> <chr> <chr>
## 1 Afghanistan 19 99 745/19987071
## 2 Afghanistan 20 00 2666/20595360
## 3 Brazil 19 99 37737/172006362
## 4 Brazil 20 00 80488/174504898
## 5 China 19 99 212258/1272915272
## 6 China 20 00 213766/1280428583Sebelum kita melakukan analisa di dataset tersebut, kita harus tahu terlebih dahulu apa saja syarat suatu dataset dikatakan rapi (tidy). Berikut adalah syaratnya:
- Setiap variabel harus memiliki kolomnya sendiri
- Setiap observasi harus memiliki barisnya sendiri
- Setiap nilai berada pada sel tersendiri
Ketiga syarat tersebut saling berhubungan sehingga jika salah satu syarat tersebut tidak terpenuhi, maka dataset belum bisa dikatakan tidy. Ketiga syarat tersebut dapat divisualisasikan melalui Gambar 1
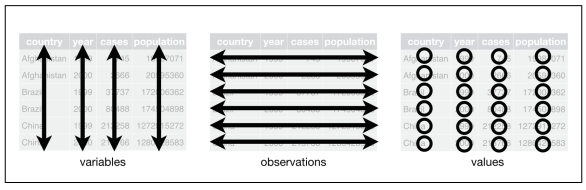
Figure 1: Visualisasi 3 rule tidy data
Dengan menggunakan prinsip data tidy kita akan menganalisa data tersebut satu persatu. Berikut adalah analisa terkait data-data tesebut:
table1merupakan data yang telah tidy. Ketiga prinsip data tidy telah terpenuhi.table2merupakan data yang belum tidy karena variabel tidak berada pada masing-masing kolomnya. Variabeltypedapat dipecah lagi menjadi 2 kolom baru yaitu kolomcasesdan kolompopulation.table3merupakan data yang belum tidy. Kolomrateberisikan rasio yang seharusnya berisi nilai hasil bagi kedua variabel. Dapat kita duga pembilang dari nilai rasio merupakan nilai variabelcases, sedangkan penyebutnya merupakan nilai dari variabelpopulation. Agar tidy kolomrateperlu dipecah menjadi 2 kolom baru (2 variabel) yaitucasesdanpopulationatau nilai yang ditampilkan pada kolomrateadalah hasil bagi kedua nilai (bukan pecahan).table4adantable4bmasih belum tidy. Dua kolom yaitu kolom1999dan2000perlu dijadikan satu kolom yaitu kolom variabelyear. Nilai dari kolom lama selanjutnya digabung menjadi satu kolom, untuktable4amenjadi kolomcases, sedangkantable4bsebagai kolompopulation.table5masih belum tidy. Agar data tersebut tidy maka kolomcenturydanyearperlu digabung menjadi satu kolom (variabel) yaitu kolomyear. Selain itu, kolom `rate juga perlu dijadikan satu atau 2 kolom seperti yang dilakukan pada poin 3.
Berdasarkan contoh-contoh tersebut pada pembahasan kali ini penulis akan menjelaskan bagaiman cara melakukan perapihan data menggunakan library tidyr dari paket tidyverse. Sebelum kita melakukannya berikut adalah sintaks untuk menginstall library tidyr secara terpisah dari paket tidyverse tersebut:
# memasang paket
install.packages("tidyr")# memuat paket
library(tidyr)3.6.1 Gather
gather() merupakan fungsi yang digunakan untuk menggabungkan beberapa kolom menjadi satu kolom kunci (disebut juga sebagai pivot long. Secara sederhana fungsi tersebut dapat dituliskan dengan format sebagai berikut:
gather(data, key, value, ...)Note:
- data: data frame
- key, value: nama kunci dan kolom nilai yang akan dibuat di output
- …: Spesifikasi kolom untuk dikumpulkan. Nilai yang diizinkan adalah:
- nama variabel
- jika kita ingin memilih semua variabel antara a dan e, gunakan a:e
- jika kita ingin mengecualikan nama kolom y gunakan -y
- untuk opsi lainnya, lihat:
dplyr::select()
Visualisasi dari fungsi gather ini disajikan pada Gambar 2
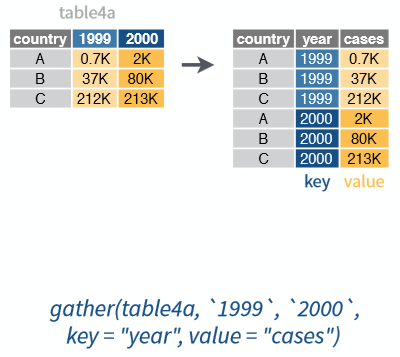
Figure 2: Visualisasi fungsi gather (Sumber: Rstudio,2017)
Berikut adalah contoh penerapannya pada dataset table4a dan table4b:
# Table4a
table4a_new <- gather(table4a,
# variabel kunci
key = "year",
# nilai variabel
value = "cases",
# kecualikan kolom country
-country)
table4a_new## # A tibble: 6 x 3
## country year cases
## <chr> <chr> <int>
## 1 Afghanistan 1999 745
## 2 Brazil 1999 37737
## 3 China 1999 212258
## 4 Afghanistan 2000 2666
## 5 Brazil 2000 80488
## 6 China 2000 213766# Table4a
table4b_new <- gather(table4b,
# variabel kunci
key = "year",
# nilai variabel
value = "population",
# kecualikan kolom country
-country)
table4b_new## # A tibble: 6 x 3
## country year population
## <chr> <chr> <int>
## 1 Afghanistan 1999 19987071
## 2 Brazil 1999 172006362
## 3 China 1999 1272915272
## 4 Afghanistan 2000 20595360
## 5 Brazil 2000 174504898
## 6 China 2000 1280428583Berdasarkan hasil yang diperoleh terlihat bahwa variabel year pada kedua dataset tersebut memiliki jenis data karakter. Jenis data ini masih belum sesuai sehingga perlu dikonversi agar menjadi jenis data numerik (int = integer). Untuk melakukannya jalankan sintaks berikut:
# table4a_new
table4a_new$year <- as.integer(table4a_new$year)
table4a_new## # A tibble: 6 x 3
## country year cases
## <chr> <int> <int>
## 1 Afghanistan 1999 745
## 2 Brazil 1999 37737
## 3 China 1999 212258
## 4 Afghanistan 2000 2666
## 5 Brazil 2000 80488
## 6 China 2000 213766# table4a_new
table4b_new$year <- as.integer(table4b_new$year)
table4b_new## # A tibble: 6 x 3
## country year population
## <chr> <int> <int>
## 1 Afghanistan 1999 19987071
## 2 Brazil 1999 172006362
## 3 China 1999 1272915272
## 4 Afghanistan 2000 20595360
## 5 Brazil 2000 174504898
## 6 China 2000 1280428583Data yang diperoleh sekaran telah rapi (tidy), sehingga sudah siap untuk dilakukan analisa data.
3.6.2 Spread
Fungsi spread() berkebalikan dengan gather(). Fungsi gather() menggabungkan beberapa kolom menjadi 2 buah kolom kolom kunci sedangkan spread() merubah dua kolom menjadi beberapa kolom. Format sederhanya adalah sebagai berikut:
Note:
- data: data frame
- key: nama kolom yang akan dijadikan heading pada kolom baru
- value: nama kolom yang nilainya akan mengisi setiap sel
Visualisasi dari fungsi spread() ini disajikan pada Gambar 3
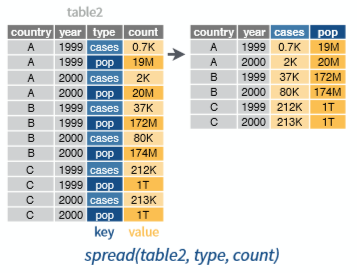
Figure 3: Visualisasi fungsi spread (Sumber: Rstudio,2017)
Pada contoh kasus pada data table2, kita dapat memisahkan kolom type menjadi kolom baru yaitu kolom cases dan population. Untuk melakukannya jalankan sintaks berikut:
# spread
table2_new <- spread(table2,
key = type,
value = count)
#print
table2_new## # A tibble: 6 x 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Terlihat bahwa data table2_new tampak memenuhi syarat kerapihan data (tidy).
3.6.3 Separate
Fungsi separate() merupakan fungsi yang digunakan untuk memisahkan sejumlah nilai pada sebuah kolom menjadi beberapa kolom berdasarkan karakter pemisah yang ada di dalam nilai suatu kolom. Fungsi ini berbeda dengan fungsi sebelumnya seperti gather() dan spread() yang menggabung atau memisahkan 2 atau beberapa kolom. Visualisasi dari fungsi separate() ini disajikan pada Gambar 4
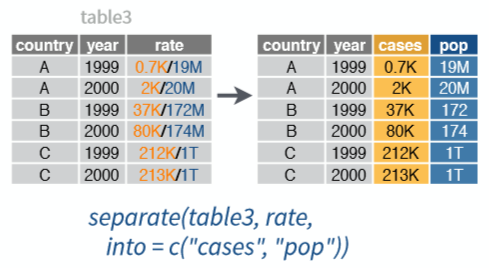
Figure 4: Visualisasi fungsi separate (Sumber: Rstudio,2017)
Jika fungsi separate() memisahkan sejumlah nilai menajdi beberapa kolom sesuai dengan karakter pemisah, fungsi separate_rows() memisahkan nilai menjadi beberapa baris berdasarkan karakter pemisah. Visualisasi dari fungsi separate_rows() ini disajikan pada Gambar 5
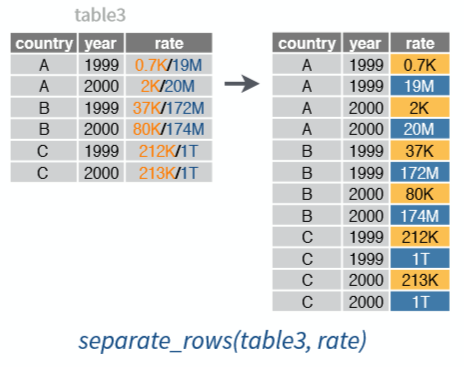
Figure 5: Visualisasi fungsi separate rows
Format sederhana fungsi separate() dan separate_rows() adalah sebagai berikut:
separate(data, col, into, sep = "[^[:alnum:]]+", convert= FALSE)
separate(data,...., sep = "[^[:alnum:]]+", convert= FALSE)Note:
- data: data frame.
- col: Nama kolom yang tidak dikutip.
- into: Vektor karakter menentukan nama variabel baru yang akan dibuat.
- sep: Pemisah antar kolom:
- Jika karakter, diartikan sebagai ekspresi reguler. Jika numerik, diartikan sebagai posisi untuk dibelah. Nilai-nilai positif mulai dari 1 di ujung kiri string; nilai negatif mulai dari -1 di ujung kanan string.
- convert: nilai logik. Jika bernilai TRUE maka kolom baru yang akan diperoleh akan dikonversi berdasarkan jenis data yang seharusnya.
Pada table3 dan table5 kita akan mencoba memisahkan kolom rate menjadi 2 kolom yaitu kolom cases dan kolom population. Berikut adalah sintaks yang digunakan:
# table3
table3_new <- separate(table3, col=rate,
into=c("cases", "population"),
sep="/", convert=TRUE)
table3_new## # A tibble: 6 x 4
## country year cases population
## <chr> <int> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583# table5
table5_new <- separate(table5, col=rate,
into=c("cases", "population"),
sep="/", convert=TRUE)
table5_new## # A tibble: 6 x 5
## country century year cases population
## <chr> <chr> <chr> <int> <int>
## 1 Afghanistan 19 99 745 19987071
## 2 Afghanistan 20 00 2666 20595360
## 3 Brazil 19 99 37737 172006362
## 4 Brazil 20 00 80488 174504898
## 5 China 19 99 212258 1272915272
## 6 China 20 00 213766 1280428583Berdasarkan hasil yang diperoleh terlihat bahwa table3 telah tidy, sedangkan table5 belum tidy sebab kolom century dan kolom year perlu digabungkan menjadi kolom year.
Kita dapat juga memisahkan kolom rate pada table3 menjadi baris baru menggunakan fungsi separate_rows(). Berikut adalah sintaks yang digunakan:
separate_rows(table3, col=rate, sep="/")## # A tibble: 12 x 3
## country year rate
## <chr> <int> <chr>
## 1 Afghanistan 1999 745
## 2 Afghanistan 1999 19987071
## 3 Afghanistan 2000 2666
## 4 Afghanistan 2000 20595360
## 5 Brazil 1999 37737
## 6 Brazil 1999 172006362
## 7 Brazil 2000 80488
## 8 Brazil 2000 174504898
## 9 China 1999 212258
## 10 China 1999 1272915272
## 11 China 2000 213766
## 12 China 2000 12804285833.6.4 Unite
Fungsi unite() merupakan kebalikan dari fungsi separate(), dimana fungsi ini menggabungkan sejumlah kolom menjadi 1 kolom. Format sederhana untuk melakukanya disajikan sebagai berikut:
unite(data, col, ..., sep = "_")Note:
- data: data frame.
- col: nama kolom baru (tanpa tanda kutip) untuk ditambahkan.
- sep: pemisah yang akan digunakan pada antar nilai.
Visualisasi dari fungsi unite() ini disajikan pada Gambar 3

Figure 6: Visualisasi fungsi unite (Sumber: Rstudio,2017)
Pada dataset table5_new kita akan menggabungkan kolom century dan kolom year menjadi kolom year tanpa pemisah. Berikut adalah sintaks untuk melakukannya:
table5_new2 <- unite(table5_new, century,
year, col="year", sep="")
table5_new2## # A tibble: 6 x 4
## country year cases population
## <chr> <chr> <int> <int>
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583Berdasarkan hasil yang diperoleh dapat dilihat bahwa table5_new2 telah memenuhi syarat data yang tidy atau rapi. Data tersebut telah siap untuk dilakukan analisa lebih lanjut.
3.7 Transformasi Data
Data frame merupakan struktur data utama dalam statistik dan dalam R. Struktur dasar data frame ialah ada satu observasi tiap baris dan setiap kolom mewakili variabel, ukuran, fitur, atau karakteristik pengamatan itu yang telah dijelaskan pada bagian sebelumya. R memiliki implementasi internal data frame yang kemungkinan besar akan kita gunakan paling sering. Namun, ada paket di CRAN yang mengimplementasikan data frame layaknya basis data relasional yang memungkinkan kita untuk beroperasi pada data frame yang sangat besar.
Mengingat pentingnya mengelola dat frame, penting bagi kita untuk memiliki alat yang baik untuk melakukannya. R memiliki beberapa paket seperti fungsi subset() dan penggunaan operator “[” dan “$” untuk mengekstrak himpunan bagian dari frame data. Namun, operasi lain, seperti pemfilteran, pengurutan, dan pengelompokan data, seringkali dapat menjadi operasi yang membosankan di R yang sintaksisnya tidak terlalu intuitif. Paket dplyr dirancang untuk mengurangi banyak masalah ini dan menyediakan serangkaian rutinitas yang dioptimalkan secara khusus untuk menangani data frame.
3.7.1 Paket dplyr
Paket dplyr dikembangkan oleh Hadley Wickham dari RStudio dan merupakan versi yang dioptimalkan dari paket plyr-nya. Paket dplyr tidak menyediakan fungsionalitas baru untuk R sendiri, dalam arti bahwa semua yang dilakukan dplyr sudah dapat dilakukan dengan fungsi basis R, tetapi sangat menyederhanakan fungsi yang ada di R.
Salah satu kontribusi penting dari paket dplyr adalah ia menyediakan “grammar” (khususnya, kata kerja) untuk manipulasi data dan untuk beroperasi pada data frame. Melalui grammar ini, kita dapat berkomunikasi dengan masuk akal apa yang telah kita lakukan terhadap data frame dapat pula dipahami orang lain (dengan asumsi mereka juga tahu grammar-nya). Hal ini berguna karena memberikan abstraksi untuk manipulasi data yang sebelumnya tidak ada. Kontribusi lain yang bermanfaat adalah bahwa fungsi dplyr sangat cepat, karena banyak operasi utama dikodekan dalam C++.
Pada bagian ini pembaca akan belajar 6 fungsi utama yang ada pada paket dplyr. Fungsi tersebut antara lain:
- Mengambil sejumlah observasi berdasarkan nilainya (
filter()). - Mengurutkan kembali baris data frame berdasarkan nilai pada sebuah atau beberapa variabel (
arrange()). - Mengambil atau subset terhadap sebuah atau beberapa variabel berdasarkan nama variabel/kolom (
select()). - Membuat variabel baru atau menambahkan kolom baru (
mutate()). - Membuat ringkasan terhadap data frame (
summarize()) - Mengelompokkan operasi berdasarkan grup data (
group_by()).
Keseluruhan fungsi tersebut format fungsi yang seragam, yaitu:
- Argumen pertama adalah data frame.
- Argumen selanjutnya adalah deskripsi yang akan dilakukan terhadap data frame (filter, pengurutan kembali, membuat ringkasan, dll) menggunakan nama variabel (tanpa tanda kutip).
- Hasil operasi yang diperoleh adalah data frame baru.
Untuk menginstall dan memuat paket dplyr jalankan sintaks berikut:
# Memasang paket
install.packages("dplyr")# memuat paket
library(dplyr)Pada contoh kali ini penulis akan menggunakan dataset flights dari library nycflights13. Berikut adalah sintaks untuk memuat dataset tersebut:
library(nycflights13)
#print
flights## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># cek variabel
colnames(flights)## [1] "year" "month" "day" "dep_time"
## [5] "sched_dep_time" "dep_delay" "arr_time" "sched_arr_time"
## [9] "arr_delay" "carrier" "flight" "tailnum"
## [13] "origin" "dest" "air_time" "distance"
## [17] "hour" "minute" "time_hour"# ringkasan data
summary(flights)## year month day dep_time
## Min. :2013 Min. : 1.000 Min. : 1.00 Min. : 1
## 1st Qu.:2013 1st Qu.: 4.000 1st Qu.: 8.00 1st Qu.: 907
## Median :2013 Median : 7.000 Median :16.00 Median :1401
## Mean :2013 Mean : 6.549 Mean :15.71 Mean :1349
## 3rd Qu.:2013 3rd Qu.:10.000 3rd Qu.:23.00 3rd Qu.:1744
## Max. :2013 Max. :12.000 Max. :31.00 Max. :2400
## NA's :8255
## sched_dep_time dep_delay arr_time sched_arr_time
## Min. : 106 Min. : -43.00 Min. : 1 Min. : 1
## 1st Qu.: 906 1st Qu.: -5.00 1st Qu.:1104 1st Qu.:1124
## Median :1359 Median : -2.00 Median :1535 Median :1556
## Mean :1344 Mean : 12.64 Mean :1502 Mean :1536
## 3rd Qu.:1729 3rd Qu.: 11.00 3rd Qu.:1940 3rd Qu.:1945
## Max. :2359 Max. :1301.00 Max. :2400 Max. :2359
## NA's :8255 NA's :8713
## arr_delay carrier flight tailnum
## Min. : -86.000 Length:336776 Min. : 1 Length:336776
## 1st Qu.: -17.000 Class :character 1st Qu.: 553 Class :character
## Median : -5.000 Mode :character Median :1496 Mode :character
## Mean : 6.895 Mean :1972
## 3rd Qu.: 14.000 3rd Qu.:3465
## Max. :1272.000 Max. :8500
## NA's :9430
## origin dest air_time distance
## Length:336776 Length:336776 Min. : 20.0 Min. : 17
## Class :character Class :character 1st Qu.: 82.0 1st Qu.: 502
## Mode :character Mode :character Median :129.0 Median : 872
## Mean :150.7 Mean :1040
## 3rd Qu.:192.0 3rd Qu.:1389
## Max. :695.0 Max. :4983
## NA's :9430
## hour minute time_hour
## Min. : 1.00 Min. : 0.00 Min. :2013-01-01 05:00:00
## 1st Qu.: 9.00 1st Qu.: 8.00 1st Qu.:2013-04-04 13:00:00
## Median :13.00 Median :29.00 Median :2013-07-03 10:00:00
## Mean :13.18 Mean :26.23 Mean :2013-07-03 05:22:54
## 3rd Qu.:17.00 3rd Qu.:44.00 3rd Qu.:2013-10-01 07:00:00
## Max. :23.00 Max. :59.00 Max. :2013-12-31 23:00:00
## dataset tersebut berisi 336.776 penerbangan yang berangkat dari New York pada tahun 2013. Data tersebut berasal dari US Bureau of Transportation Statistics.
3.7.2 filter()
Fungsi filter() digunakan untuk mengekstrak himpunan bagian (subset) baris dari data frame. Fungsi ini mirip dengan fungsi subset() yang ada di R. Secara sederhana format fungsi filter() dapat dituliskan sebagai berikut:
filter(data, ....)Note:
- data : data frame
- …. : Predikat logis didefinisikan dalam istilah variabel dalam data. Beberapa kondisi digabungkan dengan & (lihat Chapter 2 opeator relasi dan operator logika. Hanya baris tempat kondisi bernilai TRUE disimpan.
Visualisasi dari fungsi filter()disajikan pada Gambar 7
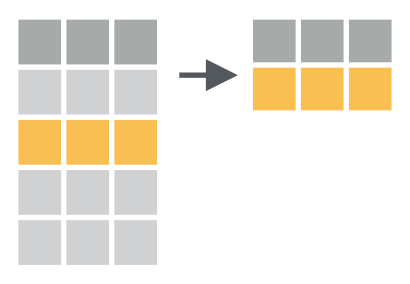
Figure 7: Visualisasi fungsi filter (Sumber: Rstudio,2017)
MIsalkan menggunakan dataset flights kita ingin mentehaui penerbangan apa saja yang berlangsung pada month==1 dan day==1 (1 Januari). Berikut adalah sintaks untuk memfilter datanya:
filter(flights, month == 1 & day == 1)## # A tibble: 842 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 832 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>Jika menggunakan paket dasar R:
jan1 <- subset(flights, month == 1 & day == 1)
head(jan1, 10)## # A tibble: 10 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 12 more variables: sched_arr_time <int>, arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour <dttm>Operator “>” merupakan operator relasi (lihat chapter 2: operator relasi). Operator tersebut banyak digunakan untuk melakukan filter terhadap variabel/kolom yang mengandung nilai numerik.
Operator “==” merupakan operator logika (lihat chapter 2: operator logika). Operator tersebut digunakan untuk melakukan filter terhadap sejumlah syarat atau kondisi yang kita tetapkan. Jika nilai yang dihasilkan TRUE, maka hanya observasi tersebut yang akan ditampilkan. Untuk lebih memahami penerapan masing-masing operator logika pada proses filter perhatikan Figure 8 berikut:
Figure 8: Diagram operasi Boolean
Note: Bagian yang di arsir adalah observasi yang akan ditampilkan pada output.
Salah satu bagian terpenting dan paling sering penulis gunakan pada fungsi ini memfilter missing value (melihat observasi yang mengandung missing value atau tidak melibatkan missing value). Berikut adalah contoh filter terhadap data pada pollution_tbl yang tidak mengandung missing value dan nilai amount>0.
flight_clean <- filter(flights,
!(is.na(air_time)|is.na(arr_time)|
is.na(arr_delay)|
is.na(dep_time)|
is.na(dep_delay)))
summary(flight_clean)Berdasarkan hasil yang diperoleh seluruh data tidak ada yang di drop sehingga dapat disimpulkan bahwa data tersebut tidak mengandung missing value dan nol.
Cara lain yang dapat digunakan adalah dengan mengunakan fungsi drop_na() dari library tidyr. Berikut adalah contoh sintaks yang digunakan:
flight_clean <- drop_na(flights)
summary(flight_clean)## year month day dep_time
## Min. :2013 Min. : 1.000 Min. : 1.00 Min. : 1
## 1st Qu.:2013 1st Qu.: 4.000 1st Qu.: 8.00 1st Qu.: 907
## Median :2013 Median : 7.000 Median :16.00 Median :1400
## Mean :2013 Mean : 6.565 Mean :15.74 Mean :1349
## 3rd Qu.:2013 3rd Qu.:10.000 3rd Qu.:23.00 3rd Qu.:1744
## Max. :2013 Max. :12.000 Max. :31.00 Max. :2400
## sched_dep_time dep_delay arr_time sched_arr_time
## Min. : 500 Min. : -43.00 Min. : 1 Min. : 1
## 1st Qu.: 905 1st Qu.: -5.00 1st Qu.:1104 1st Qu.:1122
## Median :1355 Median : -2.00 Median :1535 Median :1554
## Mean :1340 Mean : 12.56 Mean :1502 Mean :1533
## 3rd Qu.:1729 3rd Qu.: 11.00 3rd Qu.:1940 3rd Qu.:1944
## Max. :2359 Max. :1301.00 Max. :2400 Max. :2359
## arr_delay carrier flight tailnum
## Min. : -86.000 Length:327346 Min. : 1 Length:327346
## 1st Qu.: -17.000 Class :character 1st Qu.: 544 Class :character
## Median : -5.000 Mode :character Median :1467 Mode :character
## Mean : 6.895 Mean :1943
## 3rd Qu.: 14.000 3rd Qu.:3412
## Max. :1272.000 Max. :8500
## origin dest air_time distance
## Length:327346 Length:327346 Min. : 20.0 Min. : 80
## Class :character Class :character 1st Qu.: 82.0 1st Qu.: 509
## Mode :character Mode :character Median :129.0 Median : 888
## Mean :150.7 Mean :1048
## 3rd Qu.:192.0 3rd Qu.:1389
## Max. :695.0 Max. :4983
## hour minute time_hour
## Min. : 5.00 Min. : 0.00 Min. :2013-01-01 05:00:00
## 1st Qu.: 9.00 1st Qu.: 8.00 1st Qu.:2013-04-05 06:00:00
## Median :13.00 Median :29.00 Median :2013-07-04 09:00:00
## Mean :13.14 Mean :26.23 Mean :2013-07-03 17:56:45
## 3rd Qu.:17.00 3rd Qu.:44.00 3rd Qu.:2013-10-01 18:00:00
## Max. :23.00 Max. :59.00 Max. :2013-12-31 23:00:003.7.2.1 Scope Filtering
Scope filtering menerapkan ekspresi predikat pada sejumlah variabel. Ekspresi predikat harus dikutip dengan all_vars() atau any_vars() dan harus menyebutkan kata ganti . untuk merujuk ke variabel. Fungsi-fungsi yang ada pada scope filtering dan formatnya disajikan pada sintaks berikut:
filter_all(.tbl, .vars_predicate, .preserve = FALSE)
filter_if(.tbl, .predicate, .vars_predicate, .preserve = FALSE)
filter_at(.tbl, .vars, .vars_predicate, .preserve = FALSE)Note:
- .tbl: tibble atau dataframe.
- .vars_predicate: Ekspresi predikat yang dikutip seperti yang dikembalikan oleh
all_vars()atauany_vars().all_vars()melakukan filter seperti pada efek intersect (irisan himpunan), sedangkanany_vars()melakukan filter seperti efek union (himpunan gabungan).- .preserve: ketika
FALSE(default), struktur pengelompokan dihitung ulang berdasarkan data yang dihasilkan.- .predicate: fungsi predikat yang diaplikasikan pada kolom atau vektor logikal.
- .vars: daftar kolom yang dihasilkan oleh
vars(), vektor karakter dari nama kolom, vektor numerik dari posisi kolom, atauNULL.
Berikut adalahcontoh sintaks penerapan fungsi-fungsi tersebut:
# filter seluruh kolom dan baris yang memiliki nilai sesuai
# mengambil irisan data
filter_all(flights, all_vars(. > 150))## # A tibble: 0 x 19
## # ... with 19 variables: year <int>, month <int>, day <int>,
## # dep_time <int>, sched_dep_time <int>, dep_delay <dbl>, arr_time <int>,
## # sched_arr_time <int>, arr_delay <dbl>, carrier <chr>, flight <int>,
## # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
## # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm># mengambil himpunan gabungan data
filter_all(flights, any_vars(. > 150))## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># filter pada kolom tertentu berdasarkan spesifikasi
# predikat var()
# filter kolom dengan awalan h atau
# yang terdapat baris dengan nilai ganjil
# pada variabel tersebut
filter_at(flights,
vars(starts_with("a")),
any_vars((. %% 2) == 1))## # A tibble: 286,363 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 555 600 -5 913
## 7 2013 1 1 557 600 -3 709
## 8 2013 1 1 558 600 -2 753
## 9 2013 1 1 558 600 -2 849
## 10 2013 1 1 558 600 -2 853
## # ... with 286,353 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># filter pada kolom hp dan vs dimana nilai kolom genap
filter_at(flights, vars(arr_time, arr_delay), ~.%%2==0)## # A tibble: 82,790 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 533 529 4 850
## 2 2013 1 1 544 545 -1 1004
## 3 2013 1 1 554 558 -4 740
## 4 2013 1 1 557 600 -3 838
## 5 2013 1 1 559 559 0 702
## 6 2013 1 1 559 600 -1 854
## 7 2013 1 1 601 600 1 844
## 8 2013 1 1 602 610 -8 812
## 9 2013 1 1 606 610 -4 858
## 10 2013 1 1 624 630 -6 840
## # ... with 82,780 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># filter dengan menerapkan kondisi tertentu
# filter seluruh variabel dengan observasi mengandung
# bilangan bulat dan tidak memiliki nilai 0
filter_if(flights[,16:17], ~ all(floor(.) == .), all_vars(. != 0))## # A tibble: 336,776 x 2
## distance hour
## <dbl> <dbl>
## 1 1400 5
## 2 1416 5
## 3 1089 5
## 4 1576 5
## 5 762 6
## 6 719 5
## 7 1065 6
## 8 229 6
## 9 944 6
## 10 733 6
## # ... with 336,766 more rowsNote: filter_at() dan filter_if() menghilangkan kolom yang tidak sesuai kriteria. Sedangkan filter_all() digunakan untuk memfilter baris.
3.7.2.2 Fungsi Lain Untuk Mengekstrak Observasi
Selain fungsi filter() terdapat fungsi lain yang berguna dalam melakukan ekstrak data. Fungsi-fungsi tersebut antara lain:
distinct(): menghilangkan baris dengan nilai yang sama (duplicate observation).sample_frac(): melakukan sampling sejumlah fraksi baris pada data. Fungsi ini berguna saat pembaca ingin melakukan sampling data yang cukup besar menggunakan besaran fraksi data.sample_n(): sama dengansample_frac(). Bedanya adalah kita perlu menyatakan berapa baris yang hendak kita sampling.slice(): membuat irisan data. Berguna jika ingin membuat dataset baru berrdasarkan grup data atau membuat dataset dari sejumlah baris pada data.top_n(): memilih data teratas (nilai tertinggi) yang telah diurutkan.
Berikut adalah contoh sintaks penerapan fungsi-fungsi tersebut:
# menghilangkan baris dengan nilai
distinct(flights, tailnum)## # A tibble: 4,044 x 1
## tailnum
## <chr>
## 1 N14228
## 2 N24211
## 3 N619AA
## 4 N804JB
## 5 N668DN
## 6 N39463
## 7 N516JB
## 8 N829AS
## 9 N593JB
## 10 N3ALAA
## # ... with 4,034 more rows# Sampling dengan pengembalian secara acak 50% data
sample_frac(flights, 0.1, replace=TRUE)## # A tibble: 33,678 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 11 17 1843 1845 -2 2127
## 2 2013 5 20 626 630 -4 759
## 3 2013 4 28 1523 1530 -7 1831
## 4 2013 7 2 2027 2030 -3 2231
## 5 2013 9 6 1750 1755 -5 2004
## 6 2013 6 19 904 909 -5 1016
## 7 2013 7 12 2001 1734 147 2222
## 8 2013 3 28 1713 1720 -7 1839
## 9 2013 12 26 655 700 -5 957
## 10 2013 11 14 1628 1630 -2 1920
## # ... with 33,668 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># sampling dengan pengembalian secara acak 10 observasi
sample_n(flights, 10, replace=TRUE)## # A tibble: 10 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 11 30 656 701 -5 836
## 2 2013 12 23 557 600 -3 736
## 3 2013 11 10 1152 1130 22 1356
## 4 2013 3 29 1516 1459 17 1820
## 5 2013 10 16 1651 1700 -9 1944
## 6 2013 12 4 926 929 -3 1215
## 7 2013 11 22 1355 1359 -4 1720
## 8 2013 6 8 1317 1325 -8 1422
## 9 2013 11 26 2356 2359 -3 438
## 10 2013 9 18 1652 1651 1 1921
## # ... with 12 more variables: sched_arr_time <int>, arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour <dttm># Pilih data dari baris ke 25 sampai 35
slice(flights, 25:35)## # A tibble: 11 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 607 607 0 858
## 2 2013 1 1 608 600 8 807
## 3 2013 1 1 611 600 11 945
## 4 2013 1 1 613 610 3 925
## 5 2013 1 1 615 615 0 1039
## 6 2013 1 1 615 615 0 833
## 7 2013 1 1 622 630 -8 1017
## 8 2013 1 1 623 610 13 920
## 9 2013 1 1 623 627 -4 933
## 10 2013 1 1 624 630 -6 909
## 11 2013 1 1 624 630 -6 840
## # ... with 12 more variables: sched_arr_time <int>, arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour <dttm># 10 observasi dengan variabel Sepal.Width tertinggi
top_n(flights, 10, arr_time)## # A tibble: 150 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 2209 2155 14 2400
## 2 2013 1 5 2116 2130 -14 2400
## 3 2013 1 13 2243 2129 74 2400
## 4 2013 1 16 2138 2107 31 2400
## 5 2013 1 17 2256 2249 7 2400
## 6 2013 1 22 2212 2055 77 2400
## 7 2013 1 22 2249 2125 84 2400
## 8 2013 1 25 2055 1725 210 2400
## 9 2013 1 28 2303 2250 13 2400
## 10 2013 1 30 2155 1915 160 2400
## # ... with 140 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>Untuk informasi lebih lanjut pembaca dapat mengakses menu bantuan dengan mengetikkan sintaks berikut:
?<nama fungsi>3.7.3 arrange()
Fungsi arrange() bekerja mirip dengan fungsi filter() kecuali bahwa alih-alih memilih baris, fungsi ini mengubah urutan observasinya (mengurutkan dari yang terbesar atau sebaliknya). Dibutuhkan data frame dan sekumpulan nama kolom (atau ekspresi yang lebih rumit) untuk dipesan. Jika kita memberikan lebih dari satu nama kolom pada fungsi, setiap kolom tambahan akan digunakan untuk menentukan urutan nilai yang sama berdasarkan nilai kolom sebelumnya.
Fungsi arrange() mirip dengan fungsi order() pada paket dasar R. Format sederhana fungsi ini adalah sebagai berikut:
arrange(data, ....)Note:
- data : data frame
- …. : daftar nama variabel yang tidak dikutip yang dipisahkan tanda koma, atau ekspresi yang melibatkan nama variabel. Gunakan
desc()untuk mengurutkan variabel dalam urutan menurun.
Visualisasi dari fungsi arrange()disajikan pada Gambar 9
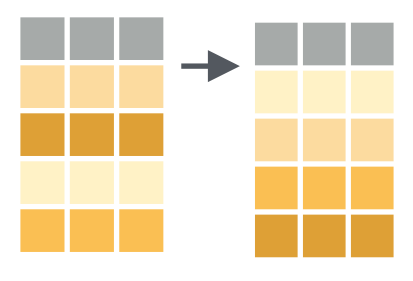
Figure 9: Visualisasi fungsi arrange (Sumber: Rstudio,2017)
Misalkan kita ingin mengurutkan penerbangan berdasarkan variabel year, month, dan day. R akan melakukan pengurutan berdasarkan year terlebih dahulu. Jika ditemukan nilai yang seimbang, maka pengurutan dilakukan oleh variabel berikutnya. Berikut adalah sintaks yang digunakan:
arrange(flights, year, month, day)## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>Jika ingin urutan yang digunakan adalah dari yang terbesar ke terkecil untuk ketiga variabel tersebut jalankan sintaks berikut:
arrange(flights, desc(year, month, day))## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>Jika menggunakan fungsi order():
attach(flights)
# urutan dari kecil ke besar
flights[order(year, month, day), ]## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># urutan dari besar ke kecil
flights[order(-year, -month, -day), ]## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 12 31 13 2359 14 439
## 2 2013 12 31 18 2359 19 449
## 3 2013 12 31 26 2245 101 129
## 4 2013 12 31 459 500 -1 655
## 5 2013 12 31 514 515 -1 814
## 6 2013 12 31 549 551 -2 925
## 7 2013 12 31 550 600 -10 725
## 8 2013 12 31 552 600 -8 811
## 9 2013 12 31 553 600 -7 741
## 10 2013 12 31 554 550 4 1024
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>Note: missing value akan selalu diurutkan pada observasi terakhir baik menggunakan urutan dari terbesar ke terkecil maupun sebaliknya.
3.7.4 select()
Fungsi select() dapat digunakan untuk memilih kolom dari data frame yang ingin kita fokuskan. Seringkali kita memiliki data frame yang besar yang berisi semua data, tetapi setiap analisis yang diberikan hanya menggunakan subset variabel atau pengamatan. Fungsi select() memungkinkan kita untuk mendapatkan beberapa kolom yang mungkin kita butuhkan.
Fungsi select() memiliki kesamaan dengan subset menggunakan tanda “[” dan “$”. Perbedaanya adalah kita dapat melakukan hal lebih melalui fungsi ini seperti memilih berdasarkan kriteria tertentu menggunakan fungsi bantuan sebagai berikut:
starts_with("abcd"), pilih kolom yang memiliki awalan “abcd”.end_with("abcd"), pilih kolom yang memiliki akhiran “abcd”.contains("abcd"), pilih kolom yang mengandung nama “abcd”matches("(.)\\1"), pilih variabel yang mengandung regular expression. Fungsi ini memilih variabel yang mengandung perulangan karakter.num_range("x", 1:3), cocokkan berdasarkan kolom dengan nama x1,x2,x3.
Berdasarkan fungsi bantuan tersebut, fungsi select() lebih powerfull dibandingkan dengan cara subset biasa serta lebih mudah dalam melakukannya. Berikut adalah format dari fungsi select():
select(data, ....)Note:
- data : data frame
- …. : Satu atau lebih ekspresi kutip yang dipisahkan oleh koma. kita dapat memperlakukan nama variabel seperti posisi, sehingga kita dapat menggunakan ekspresi seperti x: y untuk memilih rentang variabel.Nilai positif pilih variabel; nilai negatif drop variabel. Jika ekspresi pertama negatif,
select()akan secara otomatis dimulai dengan semua variabel. Gunakan argumen bernama, mis.new_name = old_name, untuk mengganti nama variabel yang dipilih.
Berikut adalah contoh penerapan selct() pada data frame flights.
# memasang paket
# install.packages("nycflights13")
# memuat data frame
library(nycflights13)
# data
flights## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># pilih kolom berdasarkan nama kolom
select(flights, year, month, day)## # A tibble: 336,776 x 3
## year month day
## <int> <int> <int>
## 1 2013 1 1
## 2 2013 1 1
## 3 2013 1 1
## 4 2013 1 1
## 5 2013 1 1
## 6 2013 1 1
## 7 2013 1 1
## 8 2013 1 1
## 9 2013 1 1
## 10 2013 1 1
## # ... with 336,766 more rows# pilih seluruh kolom dari year sampai day
select(flights, year:day)## # A tibble: 336,776 x 3
## year month day
## <int> <int> <int>
## 1 2013 1 1
## 2 2013 1 1
## 3 2013 1 1
## 4 2013 1 1
## 5 2013 1 1
## 6 2013 1 1
## 7 2013 1 1
## 8 2013 1 1
## 9 2013 1 1
## 10 2013 1 1
## # ... with 336,766 more rows# drop kolom dari year sampai day
select(flights, -(year:day))## # A tibble: 336,776 x 16
## dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay
## <int> <int> <dbl> <int> <int> <dbl>
## 1 517 515 2 830 819 11
## 2 533 529 4 850 830 20
## 3 542 540 2 923 850 33
## 4 544 545 -1 1004 1022 -18
## 5 554 600 -6 812 837 -25
## 6 554 558 -4 740 728 12
## 7 555 600 -5 913 854 19
## 8 557 600 -3 709 723 -14
## 9 557 600 -3 838 846 -8
## 10 558 600 -2 753 745 8
## # ... with 336,766 more rows, and 10 more variables: carrier <chr>,
## # flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
## # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm># pilih kolom dengan akhiran time
select(flights, ends_with("time"))## # A tibble: 336,776 x 5
## dep_time sched_dep_time arr_time sched_arr_time air_time
## <int> <int> <int> <int> <dbl>
## 1 517 515 830 819 227
## 2 533 529 850 830 227
## 3 542 540 923 850 160
## 4 544 545 1004 1022 183
## 5 554 600 812 837 116
## 6 554 558 740 728 150
## 7 555 600 913 854 158
## 8 557 600 709 723 53
## 9 557 600 838 846 140
## 10 558 600 753 745 138
## # ... with 336,766 more rows# pilih kolom yang mengandung karakter "arr"
select(flights, contains("arr"))## # A tibble: 336,776 x 4
## arr_time sched_arr_time arr_delay carrier
## <int> <int> <dbl> <chr>
## 1 830 819 11 UA
## 2 850 830 20 UA
## 3 923 850 33 AA
## 4 1004 1022 -18 B6
## 5 812 837 -25 DL
## 6 740 728 12 UA
## 7 913 854 19 B6
## 8 709 723 -14 EV
## 9 838 846 -8 B6
## 10 753 745 8 AA
## # ... with 336,766 more rowsKita juga dapat menggunakan fungsi tambahan everithing() yang berguna jika kita ingin memindahkan variabel yang menjadi fokus kita ke awal data frame tanpa melakukan drop variabel. Berikut adalah contoh sintaksnya:
# pindahkan kolom yang mengandung time di awal
select(flights, contains("time"), everything())## # A tibble: 336,776 x 19
## dep_time sched_dep_time arr_time sched_arr_time air_time
## <int> <int> <int> <int> <dbl>
## 1 517 515 830 819 227
## 2 533 529 850 830 227
## 3 542 540 923 850 160
## 4 544 545 1004 1022 183
## 5 554 600 812 837 116
## 6 554 558 740 728 150
## 7 555 600 913 854 158
## 8 557 600 709 723 53
## 9 557 600 838 846 140
## 10 558 600 753 745 138
## # ... with 336,766 more rows, and 14 more variables: time_hour <dttm>,
## # year <int>, month <int>, day <int>, dep_delay <dbl>, arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # distance <dbl>, hour <dbl>, minute <dbl>3.7.4.1 Scope Varian dari Fungsi Select
Terdapat 3 fungsi scope varian yang digunakan pada select, yaitu:
select_all(): memilih seluruh kolom dan mengaplikasikan fungsi pada nama kolom (merubah nama, merubah besar kecil huruf, dll).select_if(): memilih kolom sesuai kondisi yang diinginkan serta dapat mengaplikasikan fungsi pada nama kolom.select_at(): memilih kolom sesuai nama kolom atau index yang diinputkan padavar()dan dapat mengaplikasikan fungsi pada nama kolom.
Berikut adalah format dari fungsi-fungsi tersebut:
select_all(.tbl, .funs = list(), ...)
select_if(.tbl, .predicate, .funs = list(), ...)
select_at(.tbl, .vars, .funs = list(), ...)Note:
- .tbl: tibble atau dataframe
- .funs: fungsi yang akan diaplikasikan.
- …: argumen tambahan fungsi.
- .predicate: fungsi predikat yang akan diaplikasikan pada kolom.
- .vars: daftar kolom yang dibuat oleh fungsi
vars().
Berikut adalah contoh sintaks fungsi-fungsi tersebut:
# pilih seluruh kolom dan ubah huruf kolom
# menjadi huruf kapital
select_all(flights, toupper)## # A tibble: 336,776 x 19
## YEAR MONTH DAY DEP_TIME SCHED_DEP_TIME DEP_DELAY ARR_TIME
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 336,766 more rows, and 12 more variables: SCHED_ARR_TIME <int>,
## # ARR_DELAY <dbl>, CARRIER <chr>, FLIGHT <int>, TAILNUM <chr>,
## # ORIGIN <chr>, DEST <chr>, AIR_TIME <dbl>, DISTANCE <dbl>, HOUR <dbl>,
## # MINUTE <dbl>, TIME_HOUR <dttm># pilih kolom berdasarkan if then condition
# dan ubah nama kolom terpilih menjadi huruf kapital
select_if(flights, ~is_character(.), toupper)## # A tibble: 336,776 x 4
## CARRIER TAILNUM ORIGIN DEST
## <chr> <chr> <chr> <chr>
## 1 UA N14228 EWR IAH
## 2 UA N24211 LGA IAH
## 3 AA N619AA JFK MIA
## 4 B6 N804JB JFK BQN
## 5 DL N668DN LGA ATL
## 6 UA N39463 EWR ORD
## 7 B6 N516JB EWR FLL
## 8 EV N829AS LGA IAD
## 9 B6 N593JB JFK MCO
## 10 AA N3ALAA LGA ORD
## # ... with 336,766 more rows# pilih beberapa kolom dan ubah nama kolom menjadi huruf besar.
select_at(flights, vars(contains("time")), toupper)## # A tibble: 336,776 x 6
## DEP_TIME SCHED_DEP_TIME ARR_TIME SCHED_ARR_TIME AIR_TIME
## <int> <int> <int> <int> <dbl>
## 1 517 515 830 819 227
## 2 533 529 850 830 227
## 3 542 540 923 850 160
## 4 544 545 1004 1022 183
## 5 554 600 812 837 116
## 6 554 558 740 728 150
## 7 555 600 913 854 158
## 8 557 600 709 723 53
## 9 557 600 838 846 140
## 10 558 600 753 745 138
## # ... with 336,766 more rows, and 1 more variable: TIME_HOUR <dttm>3.7.4.2 Fungsi Pull Untuk Mengambil Nilai Pada Kolom
Fungsi pull() digunakan untuk mengambil nilai pada variabel. Output yang dihasilkan berupa vektor. Fungsi ini mirip dengan subseting menggunakan “$” (dolar sign) atau “[[” (double square brackets). Berikut adalah format fungsi tersebut:
pull(.data, var = -1)Note :
- .data: tibble atau dataframe.
- var: nama variabel atau indeks. Untuk indeks positif, tabel akan dibaca dari kanan. Jika negatif akan dibaca dari kiri.
Visualisasi dari fungsi pull()disajikan pada Gambar 10
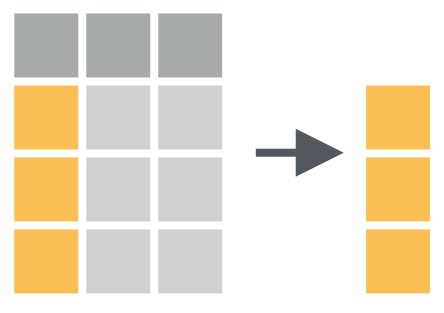
Figure 10: Visualisasi fungsi pull (Sumber: Rstudio,2017)
Berikut adalah contoh sintaks menggunakan fungsi pull():
# menggunakan fungsi pull
pull(mtcars, mpg)## [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2
## [15] 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4
## [29] 15.8 19.7 15.0 21.4# menggunakan fungsi dasar
mtcars[["mpg"]]## [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2
## [15] 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4
## [29] 15.8 19.7 15.0 21.43.7.5 mutate()
Fungsi mutate() ada untuk menghitung transformasi variabel dalam data frame. Seringkali, kita ingin membuat variabel baru yang berasal dari variabel yang ada dan fungsi mutate() menyediakan antarmuka yang bersih untuk melakukan itu. Format yang digunakan adalah sebagai berikut:
mutate(data, ....)Note:
- data : data frame
- …. : Pasangan nama-nilai ekspresi, masing-masing dengan panjang 1 atau panjang yang sama dengan jumlah baris dalam grup (jika menggunakan group_by ()) atau di seluruh input (jika tidak menggunakan grup). Nama setiap argumen akan menjadi nama variabel baru, dan nilainya akan menjadi nilai yang sesuai. Gunakan nilai NULL dalam mutasi untuk menjatuhkan drop variabel lama, sehingga variabel baru menimpa variabel yang ada dengan nama yang sama.
# subset data frame
flights_sml <- select(flights,
year:day,
ends_with("delay"),
distance,
air_time
)
# mutate()
mutate(flights_sml,
gain = arr_delay - dep_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)## # A tibble: 336,776 x 10
## year month day dep_delay arr_delay distance air_time gain hours
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 2 11 1400 227 9 3.78
## 2 2013 1 1 4 20 1416 227 16 3.78
## 3 2013 1 1 2 33 1089 160 31 2.67
## 4 2013 1 1 -1 -18 1576 183 -17 3.05
## 5 2013 1 1 -6 -25 762 116 -19 1.93
## 6 2013 1 1 -4 12 719 150 16 2.5
## 7 2013 1 1 -5 19 1065 158 24 2.63
## 8 2013 1 1 -3 -14 229 53 -11 0.883
## 9 2013 1 1 -3 -8 944 140 -5 2.33
## 10 2013 1 1 -2 8 733 138 10 2.3
## # ... with 336,766 more rows, and 1 more variable: gain_per_hour <dbl>Jika hanya ingin menyisakan variabel output fungsi mutate() pada data frame (variabel lain di drop), kita dapat menggunakan fungsi transmute(). Berikut adalah contoh sintaks yang digunakan:
transmute(flights,
gain = arr_delay - dep_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)## # A tibble: 336,776 x 3
## gain hours gain_per_hour
## <dbl> <dbl> <dbl>
## 1 9 3.78 2.38
## 2 16 3.78 4.23
## 3 31 2.67 11.6
## 4 -17 3.05 -5.57
## 5 -19 1.93 -9.83
## 6 16 2.5 6.4
## 7 24 2.63 9.11
## 8 -11 0.883 -12.5
## 9 -5 2.33 -2.14
## 10 10 2.3 4.35
## # ... with 336,766 more rowsAdapaun fungsi-fungsi dan operator yang dapat digunakan pada mutate() untuk membuat variabel baru adalah sebagai berikut:
- Operator aritmatik (+,-,*,/,^, %/%, %%). operator aritmetik seperti %/% dan %% sangat berguna dalam memecah integer menjadi beberapa bagian seperti hasil bagi tanpa sisa (%/%) dan sisa hasil bagi (%%). Berikut adalah contoh penerapannya:
transmute(flights,
dep_time,
hour = dep_time %/% 100,
minute = dep_time %% 100
)## # A tibble: 336,776 x 3
## dep_time hour minute
## <int> <dbl> <dbl>
## 1 517 5 17
## 2 533 5 33
## 3 542 5 42
## 4 544 5 44
## 5 554 5 54
## 6 554 5 54
## 7 555 5 55
## 8 557 5 57
## 9 557 5 57
## 10 558 5 58
## # ... with 336,766 more rows- Fungsi aritmetik (
log(),sin(),cos(),dll) - Fungsi Offsets (
lead()danlag()). memungkinkan kita untuk merujuk pada nilai-nilai memimpin atau tertinggal. Berikut adalah contoh penerapannya:
(x <- 1:10)## [1] 1 2 3 4 5 6 7 8 9 10lag(x)## [1] NA 1 2 3 4 5 6 7 8 9lead(x)## [1] 2 3 4 5 6 7 8 9 10 NA- Fungsi kumulatif (
cumsum(),cumprod(),cummin(),cummax(), dancummean()). Jika kita membutuhkan agregat bergulir (mis., Jumlah yang dihitung di atas jendela bergulir). Berikut adalah contoh penerapannya:
x## [1] 1 2 3 4 5 6 7 8 9 10cumsum(x)## [1] 1 3 6 10 15 21 28 36 45 55cummean(x)## [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5Operator logik (<, <=, >, >=, !=). Jika kita melakukan urutan operasi logis yang kompleks, seringkali ide yang baik untuk menyimpan nilai sementara dalam variabel baru sehingga kita dapat memeriksa bahwa setiap langkah berfungsi seperti yang diharapkan.
Rangking (
min_rank(),row_number(),dense_rank(),percent_rank(),cume_dist()danntile()).
3.7.5.1 Scope Variant Fungsi Mutate dan Transmute
Scope variants dari fungsi mutate() dan transmute berfungsi melakukan transformasi yang sama terhadap beberapa variabel. Terdapat tiga varaian umum dari fungsi-fungsinya, antara lain:
_all:bekerja pada seluruh variabel._at: bekerja pada variabel terpilih melalui vektor numerik atau string._if: berkeja pada variabel terpilih melalui fungsi predikat.
Berikut adalah format fungsi-fungsi tersebut:
mutate_all(.tbl, .funs, ...)
mutate_if(.tbl, .predicate, .funs, ...)
mutate_at(.tbl, .vars, .funs, ...)
transmute_all(.tbl, .funs, ...)
transmute_if(.tbl, .predicate, .funs, ...)
transmute_at(.tbl, .vars, .funs, ...)Note:
- .tbl: tibble atau dataframe.
- .funs: fungsi yang diaplikasikan.
- …: argumen tambahan pada fungsi.
- .predicate: fungsi predikat yang diaplikasikan pada kolom.
- .vars: daftra kolom yang dibuat menggunakan fungsi
vars().
Berikut adalah contoh sintaks dari fungsi-fungsi tersebut:
# melakukan standarisasi variabel numerik
# fungsi standarisasi
scale2 <- function(x, na.rm = FALSE) (x - mean(x, na.rm = na.rm)) / sd(x, na.rm)
# standarisasi variabel dataset mtcars
mutate_all(mtcars, scale2)## mpg cyl disp hp drat wt
## 1 0.15088482 -0.1049878 -0.57061982 -0.53509284 0.56751369 -0.610399567
## 2 0.15088482 -0.1049878 -0.57061982 -0.53509284 0.56751369 -0.349785269
## 3 0.44954345 -1.2248578 -0.99018209 -0.78304046 0.47399959 -0.917004624
## 4 0.21725341 -0.1049878 0.22009369 -0.53509284 -0.96611753 -0.002299538
## 5 -0.23073453 1.0148821 1.04308123 0.41294217 -0.83519779 0.227654255
## 6 -0.33028740 -0.1049878 -0.04616698 -0.60801861 -1.56460776 0.248094592
## 7 -0.96078893 1.0148821 1.04308123 1.43390296 -0.72298087 0.360516446
## 8 0.71501778 -1.2248578 -0.67793094 -1.23518023 0.17475447 -0.027849959
## 9 0.44954345 -1.2248578 -0.72553512 -0.75387015 0.60491932 -0.068730634
## 10 -0.14777380 -0.1049878 -0.50929918 -0.34548584 0.60491932 0.227654255
## 11 -0.38006384 -0.1049878 -0.50929918 -0.34548584 0.60491932 0.227654255
## 12 -0.61235388 1.0148821 0.36371309 0.48586794 -0.98482035 0.871524874
## 13 -0.46302456 1.0148821 0.36371309 0.48586794 -0.98482035 0.524039143
## 14 -0.81145962 1.0148821 0.36371309 0.48586794 -0.98482035 0.575139986
## 15 -1.60788262 1.0148821 1.94675381 0.85049680 -1.24665983 2.077504765
## 16 -1.60788262 1.0148821 1.84993175 0.99634834 -1.11574009 2.255335698
## 17 -0.89442035 1.0148821 1.68856165 1.21512565 -0.68557523 2.174596366
## 18 2.04238943 -1.2248578 -1.22658929 -1.17683962 0.90416444 -1.039646647
## 19 1.71054652 -1.2248578 -1.25079481 -1.38103178 2.49390411 -1.637526508
## 20 2.29127162 -1.2248578 -1.28790993 -1.19142477 1.16600392 -1.412682800
## 21 0.23384555 -1.2248578 -0.89255318 -0.72469984 0.19345729 -0.768812180
## 22 -0.76168319 1.0148821 0.70420401 0.04831332 -1.56460776 0.309415603
## 23 -0.81145962 1.0148821 0.59124494 0.04831332 -0.83519779 0.222544170
## 24 -1.12671039 1.0148821 0.96239618 1.43390296 0.24956575 0.636460997
## 25 -0.14777380 1.0148821 1.36582144 0.41294217 -0.96611753 0.641571082
## 26 1.19619000 -1.2248578 -1.22416874 -1.17683962 0.90416444 -1.310481114
## 27 0.98049211 -1.2248578 -0.89093948 -0.81221077 1.55876313 -1.100967659
## 28 1.71054652 -1.2248578 -1.09426581 -0.49133738 0.32437703 -1.741772228
## 29 -0.71190675 1.0148821 0.97046468 1.71102089 1.16600392 -0.048290296
## 30 -0.06481307 -0.1049878 -0.69164740 0.41294217 0.04383473 -0.457097039
## 31 -0.84464392 1.0148821 0.56703942 2.74656682 -0.10578782 0.360516446
## 32 0.21725341 -1.2248578 -0.88529152 -0.54967799 0.96027290 -0.446876870
## qsec vs am gear carb
## 1 -0.77716515 -0.8680278 1.1899014 0.4235542 0.7352031
## 2 -0.46378082 -0.8680278 1.1899014 0.4235542 0.7352031
## 3 0.42600682 1.1160357 1.1899014 0.4235542 -1.1221521
## 4 0.89048716 1.1160357 -0.8141431 -0.9318192 -1.1221521
## 5 -0.46378082 -0.8680278 -0.8141431 -0.9318192 -0.5030337
## 6 1.32698675 1.1160357 -0.8141431 -0.9318192 -1.1221521
## 7 -1.12412636 -0.8680278 -0.8141431 -0.9318192 0.7352031
## 8 1.20387148 1.1160357 -0.8141431 0.4235542 -0.5030337
## 9 2.82675459 1.1160357 -0.8141431 0.4235542 -0.5030337
## 10 0.25252621 1.1160357 -0.8141431 0.4235542 0.7352031
## 11 0.58829513 1.1160357 -0.8141431 0.4235542 0.7352031
## 12 -0.25112717 -0.8680278 -0.8141431 -0.9318192 0.1160847
## 13 -0.13920420 -0.8680278 -0.8141431 -0.9318192 0.1160847
## 14 0.08464175 -0.8680278 -0.8141431 -0.9318192 0.1160847
## 15 0.07344945 -0.8680278 -0.8141431 -0.9318192 0.7352031
## 16 -0.01608893 -0.8680278 -0.8141431 -0.9318192 0.7352031
## 17 -0.23993487 -0.8680278 -0.8141431 -0.9318192 0.7352031
## 18 0.90727560 1.1160357 1.1899014 0.4235542 -1.1221521
## 19 0.37564148 1.1160357 1.1899014 0.4235542 -0.5030337
## 20 1.14790999 1.1160357 1.1899014 0.4235542 -1.1221521
## 21 1.20946763 1.1160357 -0.8141431 -0.9318192 -1.1221521
## 22 -0.54772305 -0.8680278 -0.8141431 -0.9318192 -0.5030337
## 23 -0.30708866 -0.8680278 -0.8141431 -0.9318192 -0.5030337
## 24 -1.36476075 -0.8680278 -0.8141431 -0.9318192 0.7352031
## 25 -0.44699237 -0.8680278 -0.8141431 -0.9318192 -0.5030337
## 26 0.58829513 1.1160357 1.1899014 0.4235542 -1.1221521
## 27 -0.64285758 -0.8680278 1.1899014 1.7789276 -0.5030337
## 28 -0.53093460 1.1160357 1.1899014 1.7789276 -0.5030337
## 29 -1.87401028 -0.8680278 1.1899014 1.7789276 0.7352031
## 30 -1.31439542 -0.8680278 1.1899014 1.7789276 1.9734398
## 31 -1.81804880 -0.8680278 1.1899014 1.7789276 3.2116766
## 32 0.42041067 1.1160357 1.1899014 0.4235542 -0.5030337# standarisasi variabel mpg dan hp
mutate_at(mtcars, vars(mpg,hp), scale2)## mpg cyl disp hp drat wt qsec vs am gear carb
## 1 0.15088482 6 160.0 -0.53509284 3.90 2.620 16.46 0 1 4 4
## 2 0.15088482 6 160.0 -0.53509284 3.90 2.875 17.02 0 1 4 4
## 3 0.44954345 4 108.0 -0.78304046 3.85 2.320 18.61 1 1 4 1
## 4 0.21725341 6 258.0 -0.53509284 3.08 3.215 19.44 1 0 3 1
## 5 -0.23073453 8 360.0 0.41294217 3.15 3.440 17.02 0 0 3 2
## 6 -0.33028740 6 225.0 -0.60801861 2.76 3.460 20.22 1 0 3 1
## 7 -0.96078893 8 360.0 1.43390296 3.21 3.570 15.84 0 0 3 4
## 8 0.71501778 4 146.7 -1.23518023 3.69 3.190 20.00 1 0 4 2
## 9 0.44954345 4 140.8 -0.75387015 3.92 3.150 22.90 1 0 4 2
## 10 -0.14777380 6 167.6 -0.34548584 3.92 3.440 18.30 1 0 4 4
## 11 -0.38006384 6 167.6 -0.34548584 3.92 3.440 18.90 1 0 4 4
## 12 -0.61235388 8 275.8 0.48586794 3.07 4.070 17.40 0 0 3 3
## 13 -0.46302456 8 275.8 0.48586794 3.07 3.730 17.60 0 0 3 3
## 14 -0.81145962 8 275.8 0.48586794 3.07 3.780 18.00 0 0 3 3
## 15 -1.60788262 8 472.0 0.85049680 2.93 5.250 17.98 0 0 3 4
## 16 -1.60788262 8 460.0 0.99634834 3.00 5.424 17.82 0 0 3 4
## 17 -0.89442035 8 440.0 1.21512565 3.23 5.345 17.42 0 0 3 4
## 18 2.04238943 4 78.7 -1.17683962 4.08 2.200 19.47 1 1 4 1
## 19 1.71054652 4 75.7 -1.38103178 4.93 1.615 18.52 1 1 4 2
## 20 2.29127162 4 71.1 -1.19142477 4.22 1.835 19.90 1 1 4 1
## 21 0.23384555 4 120.1 -0.72469984 3.70 2.465 20.01 1 0 3 1
## 22 -0.76168319 8 318.0 0.04831332 2.76 3.520 16.87 0 0 3 2
## 23 -0.81145962 8 304.0 0.04831332 3.15 3.435 17.30 0 0 3 2
## 24 -1.12671039 8 350.0 1.43390296 3.73 3.840 15.41 0 0 3 4
## 25 -0.14777380 8 400.0 0.41294217 3.08 3.845 17.05 0 0 3 2
## 26 1.19619000 4 79.0 -1.17683962 4.08 1.935 18.90 1 1 4 1
## 27 0.98049211 4 120.3 -0.81221077 4.43 2.140 16.70 0 1 5 2
## 28 1.71054652 4 95.1 -0.49133738 3.77 1.513 16.90 1 1 5 2
## 29 -0.71190675 8 351.0 1.71102089 4.22 3.170 14.50 0 1 5 4
## 30 -0.06481307 6 145.0 0.41294217 3.62 2.770 15.50 0 1 5 6
## 31 -0.84464392 8 301.0 2.74656682 3.54 3.570 14.60 0 1 5 8
## 32 0.21725341 4 121.0 -0.54967799 4.11 2.780 18.60 1 1 4 2# standarisasi hanya pada variabel numerik
mutate_if(mtcars, is_numeric, scale2)## mpg cyl disp hp drat wt
## 1 0.15088482 -0.1049878 -0.57061982 -0.53509284 0.56751369 -0.610399567
## 2 0.15088482 -0.1049878 -0.57061982 -0.53509284 0.56751369 -0.349785269
## 3 0.44954345 -1.2248578 -0.99018209 -0.78304046 0.47399959 -0.917004624
## 4 0.21725341 -0.1049878 0.22009369 -0.53509284 -0.96611753 -0.002299538
## 5 -0.23073453 1.0148821 1.04308123 0.41294217 -0.83519779 0.227654255
## 6 -0.33028740 -0.1049878 -0.04616698 -0.60801861 -1.56460776 0.248094592
## 7 -0.96078893 1.0148821 1.04308123 1.43390296 -0.72298087 0.360516446
## 8 0.71501778 -1.2248578 -0.67793094 -1.23518023 0.17475447 -0.027849959
## 9 0.44954345 -1.2248578 -0.72553512 -0.75387015 0.60491932 -0.068730634
## 10 -0.14777380 -0.1049878 -0.50929918 -0.34548584 0.60491932 0.227654255
## 11 -0.38006384 -0.1049878 -0.50929918 -0.34548584 0.60491932 0.227654255
## 12 -0.61235388 1.0148821 0.36371309 0.48586794 -0.98482035 0.871524874
## 13 -0.46302456 1.0148821 0.36371309 0.48586794 -0.98482035 0.524039143
## 14 -0.81145962 1.0148821 0.36371309 0.48586794 -0.98482035 0.575139986
## 15 -1.60788262 1.0148821 1.94675381 0.85049680 -1.24665983 2.077504765
## 16 -1.60788262 1.0148821 1.84993175 0.99634834 -1.11574009 2.255335698
## 17 -0.89442035 1.0148821 1.68856165 1.21512565 -0.68557523 2.174596366
## 18 2.04238943 -1.2248578 -1.22658929 -1.17683962 0.90416444 -1.039646647
## 19 1.71054652 -1.2248578 -1.25079481 -1.38103178 2.49390411 -1.637526508
## 20 2.29127162 -1.2248578 -1.28790993 -1.19142477 1.16600392 -1.412682800
## 21 0.23384555 -1.2248578 -0.89255318 -0.72469984 0.19345729 -0.768812180
## 22 -0.76168319 1.0148821 0.70420401 0.04831332 -1.56460776 0.309415603
## 23 -0.81145962 1.0148821 0.59124494 0.04831332 -0.83519779 0.222544170
## 24 -1.12671039 1.0148821 0.96239618 1.43390296 0.24956575 0.636460997
## 25 -0.14777380 1.0148821 1.36582144 0.41294217 -0.96611753 0.641571082
## 26 1.19619000 -1.2248578 -1.22416874 -1.17683962 0.90416444 -1.310481114
## 27 0.98049211 -1.2248578 -0.89093948 -0.81221077 1.55876313 -1.100967659
## 28 1.71054652 -1.2248578 -1.09426581 -0.49133738 0.32437703 -1.741772228
## 29 -0.71190675 1.0148821 0.97046468 1.71102089 1.16600392 -0.048290296
## 30 -0.06481307 -0.1049878 -0.69164740 0.41294217 0.04383473 -0.457097039
## 31 -0.84464392 1.0148821 0.56703942 2.74656682 -0.10578782 0.360516446
## 32 0.21725341 -1.2248578 -0.88529152 -0.54967799 0.96027290 -0.446876870
## qsec vs am gear carb
## 1 -0.77716515 -0.8680278 1.1899014 0.4235542 0.7352031
## 2 -0.46378082 -0.8680278 1.1899014 0.4235542 0.7352031
## 3 0.42600682 1.1160357 1.1899014 0.4235542 -1.1221521
## 4 0.89048716 1.1160357 -0.8141431 -0.9318192 -1.1221521
## 5 -0.46378082 -0.8680278 -0.8141431 -0.9318192 -0.5030337
## 6 1.32698675 1.1160357 -0.8141431 -0.9318192 -1.1221521
## 7 -1.12412636 -0.8680278 -0.8141431 -0.9318192 0.7352031
## 8 1.20387148 1.1160357 -0.8141431 0.4235542 -0.5030337
## 9 2.82675459 1.1160357 -0.8141431 0.4235542 -0.5030337
## 10 0.25252621 1.1160357 -0.8141431 0.4235542 0.7352031
## 11 0.58829513 1.1160357 -0.8141431 0.4235542 0.7352031
## 12 -0.25112717 -0.8680278 -0.8141431 -0.9318192 0.1160847
## 13 -0.13920420 -0.8680278 -0.8141431 -0.9318192 0.1160847
## 14 0.08464175 -0.8680278 -0.8141431 -0.9318192 0.1160847
## 15 0.07344945 -0.8680278 -0.8141431 -0.9318192 0.7352031
## 16 -0.01608893 -0.8680278 -0.8141431 -0.9318192 0.7352031
## 17 -0.23993487 -0.8680278 -0.8141431 -0.9318192 0.7352031
## 18 0.90727560 1.1160357 1.1899014 0.4235542 -1.1221521
## 19 0.37564148 1.1160357 1.1899014 0.4235542 -0.5030337
## 20 1.14790999 1.1160357 1.1899014 0.4235542 -1.1221521
## 21 1.20946763 1.1160357 -0.8141431 -0.9318192 -1.1221521
## 22 -0.54772305 -0.8680278 -0.8141431 -0.9318192 -0.5030337
## 23 -0.30708866 -0.8680278 -0.8141431 -0.9318192 -0.5030337
## 24 -1.36476075 -0.8680278 -0.8141431 -0.9318192 0.7352031
## 25 -0.44699237 -0.8680278 -0.8141431 -0.9318192 -0.5030337
## 26 0.58829513 1.1160357 1.1899014 0.4235542 -1.1221521
## 27 -0.64285758 -0.8680278 1.1899014 1.7789276 -0.5030337
## 28 -0.53093460 1.1160357 1.1899014 1.7789276 -0.5030337
## 29 -1.87401028 -0.8680278 1.1899014 1.7789276 0.7352031
## 30 -1.31439542 -0.8680278 1.1899014 1.7789276 1.9734398
## 31 -1.81804880 -0.8680278 1.1899014 1.7789276 3.2116766
## 32 0.42041067 1.1160357 1.1899014 0.4235542 -0.50303373.7.5.2 Kustomisasi Nama Kolom dan Nama Baris
Tidy data tidak menggunakan nama variabel yang di simpan pada variabel diluar kolom. Untuk bekerja dengan nama kolom kita perlu memindahkan nama baris menjadi kolom baru. Terdapat dua fungsi untuk bekerja dengan nama baris, antara lain:
rownames_to_column(): merubah nama baris menjadi kolom baru.column_to_rownames(): merubah kolom menjadi nama baris.
rownames_to_column(.data, var = "rowname")
column_to_rownames(.data, var = "rowname")Note:
- .data: dataframe.
- var: nama kolom yang akan digunakan atau dibuat.
Berikut adalah contoh sintaks pada fungsi tersebut:
# membuat kolom nama mobil
mtcars2 <- rownames_to_column(mtcars, var="nama_mobil")
head(mtcars2)## nama_mobil mpg cyl disp hp drat wt qsec vs am gear carb
## 1 Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## 2 Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## 3 Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## 4 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## 5 Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## 6 Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1# membuat kolom nama mobil menajdi nama baris
mtcars3 <- column_to_rownames(mtcars2, var="nama_mobil")
head(mtcars3)## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1Sering kali nama variabel atau kolom yang kita miliki tidak sesuai dengan deskripsi data yang kita dimiliki. Kita dapat mengubah nama kolom tersebut menggunakan fungsi rename(). Format fungsi tersebut adalah sebagai berikut:
rename(.data, ...).data: dataframe....: Argumen tambahan pada yan berisi nam kolom baru disertai nama kolom lama.
Berikut adalah contoh sintaks untuk mengubah nama kolom:
rename(mtcars, horse_power=hp)## mpg cyl disp horse_power drat wt qsec vs am gear
## Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4
## Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4
## Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4
## Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3
## Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3
## Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3
## Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3
## Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4
## Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4
## Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4
## Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4
## Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3
## Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3
## Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3
## Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3
## Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3
## Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3
## Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4
## Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4
## Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4
## Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3
## Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3
## AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3
## Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3
## Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3
## Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4
## Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5
## Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5
## Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5
## Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5
## Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5
## Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4
## carb
## Mazda RX4 4
## Mazda RX4 Wag 4
## Datsun 710 1
## Hornet 4 Drive 1
## Hornet Sportabout 2
## Valiant 1
## Duster 360 4
## Merc 240D 2
## Merc 230 2
## Merc 280 4
## Merc 280C 4
## Merc 450SE 3
## Merc 450SL 3
## Merc 450SLC 3
## Cadillac Fleetwood 4
## Lincoln Continental 4
## Chrysler Imperial 4
## Fiat 128 1
## Honda Civic 2
## Toyota Corolla 1
## Toyota Corona 1
## Dodge Challenger 2
## AMC Javelin 2
## Camaro Z28 4
## Pontiac Firebird 2
## Fiat X1-9 1
## Porsche 914-2 2
## Lotus Europa 2
## Ford Pantera L 4
## Ferrari Dino 6
## Maserati Bora 8
## Volvo 142E 23.7.6 summarize() dan group_by()
Kita dapat membuat ringkasan data menggunakan fungsi summarize(). Fungsi tersebut akan merubah data frame menjadi sebuah baris berisi ringkasan data yang kita inginkan. Berikut adalh contoh penerapannya:
summarize(flights, delay = mean(dep_delay, na.rm = TRUE))## # A tibble: 1 x 1
## delay
## <dbl>
## 1 12.6FUngsi ini akan lebih berguna saat digunakan dengan fungsi group_by() sehingga dapat diperoleh ringkasan data pada setiap grup. berikut adalah contoh penerapannya:
by_day <- group_by(flights, year, month, day)
summarize(by_day, delay = mean(dep_delay, na.rm = TRUE))## # A tibble: 365 x 4
## # Groups: year, month [12]
## year month day delay
## <int> <int> <int> <dbl>
## 1 2013 1 1 11.5
## 2 2013 1 2 13.9
## 3 2013 1 3 11.0
## 4 2013 1 4 8.95
## 5 2013 1 5 5.73
## 6 2013 1 6 7.15
## 7 2013 1 7 5.42
## 8 2013 1 8 2.55
## 9 2013 1 9 2.28
## 10 2013 1 10 2.84
## # ... with 355 more rows3.7.7 Mengkombinasikan Beberapa Operasi Menggunakan Operator Pipe (%>%)
Operator pipa (%>%) sangat berguna untuk merangkai bersama beberapa fungsi dplyr dalam suatu urutan operasi. Perhatikan contoh sebelumnya dimana setiap kali kita ingin menerapkan lebih dari satu fungsi, urutannya akan dimulai dalam urutan panggilan fungsi bersarang yang sulit dibaca. Secara ringkas dapat kita tulis sebagai berikut:
third(second(first(x)))Jika dituliskan menggunakan operator pipa akan menghasilkan sintak berikut:
x %>%
first() %>%
second() %>%
third()Dengan menuliskannya melalui cara tersebut kita dapat membacanya lebih mudah.
Misal kita ingin mengetahui hubungan antara variabel jarak (dist) terhadap rata-rata delay (arr_delay). Langkah-langkah untuk melakukannya dengan menggunakan operator pipa adalah sebagai berikut:
- Kelompokkan penerbangan berdasarkan destinasinya (
group_by()). - Hitung ringkasan data berdasarkan jarak, rata-rata delay, dan jumlah penerbangan.
- Lakukan filter untuk membuang noisy point (jika diperlukan). Dalam hal ini jumlah penerbangan > 20 dan tujuan penerbangan Honolulu (“HNL”) adalah outlier atau noisy point.
Berikut adalah sintaks untuk melakukannya:
## # A tibble: 96 x 4
## dest count dist delay
## <chr> <int> <dbl> <dbl>
## 1 ABQ 254 1826 4.38
## 2 ACK 265 199 4.85
## 3 ALB 439 143 14.4
## 4 ATL 17215 757. 11.3
## 5 AUS 2439 1514. 6.02
## 6 AVL 275 584. 8.00
## 7 BDL 443 116 7.05
## 8 BGR 375 378 8.03
## 9 BHM 297 866. 16.9
## 10 BNA 6333 758. 11.8
## # ... with 86 more rows## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
Figure 11: Jarak vs rata-rata delay
Berdasarkan Figure 11, rata-rata delay meningkat seiring dengan pertambahan jarak penerbangan.
Referensi
- Wickham, H. Grolemund G. 2016. R For Data Science: Import, Tidy, Transform, Visualize, And Model Data. O’Reilly Media, Inc.
- Peng, R.D. 2015. Exploratory Data Analysis with R. Leanpub book.
- Dplyr Documentation. https://dplyr.tidyverse.org/
- Quick-R. Data Input. https://www.statmethods.net/input/index.html
- Quick-R. Data Management. https://www.statmethods.net/management/index.html
- STHDA. Importing Data Into R . http://www.sthda.com/english/wiki/importing-data-into-r
- STHDA. Exporting Data From R. http://www.sthda.com/english/wiki/exporting-data-from-r