Daftar Isi
Pada bidang lingkungan kita sering kali menemui sebuah pernyataan “konsentrasi rata-rata TSS pada sungai tersebut adalah 30 mg/l” atau “kedalaman penampang saluran tersebut berkisar antara 1 sampai 2 meter”. Kedua pernyataan tersebut merupakan sebuah penyapaian informasi terkait karakteristik data yang ada. Pernyataan yang pertama menyatakan karakteristik nilai pemusatan data, sedangkan yang kedua menyatakan karakteristik sebaran suatu data.
Karakteristik lain yang sering digunakan untuk menjelaskan suatu data adalah bentuk distibusi suatu data dan estimasi nilai ekstrim seperti nilai masimum dan minimum suatu data. Seluruh karakteristik data tersebut perlu dihitung untuk memperoleh informasi numerik pada data.
Pada chapter ini kita akan membahas terkait metode untuk membuat ringkasan dan deksripsi data. Pembahasan akan terdiri dari ukuran nilai pemusatan data, ukuran sebaran atau variabilitas data dan bentuk distribusi data. Selain itu kita akan membahas nilai ekstrim yang ada pada sebuah data dan transformasi data.
6.1 Ukuran Pemusatan Data
Nilai rata-rata (mean) dan nilai tengah (median) merupakan dua nilai yang paling umum digunakan untuk menyatakan lokasi pemusatan data meskipun kedua nilai bukanlah satu atau dua ukuran yang tersedia. Apa sajakah properti dari kedua ukuran tersebut dan kapan salah satu atau keduanya dapat digunakan bersamaan?.
6.1.1 Pengukuran Klasik-Mean
Nilai mean (\(\overline{X}\)) diperoleh dengan menjumlahkan seluruh data dan membaginya dengan jumlah observasinya yang dapat dituliskan seperti Persamaan (1):
\[\begin{equation} \overline{X}=\text{}\sum_{_{i=1}}^n\frac{X_i}{n} \tag{1} \end{equation}\]Nilai mean yang disimbolkan dengan “X bar” merupakan nilai mean untuk sampel. Nilai mean untuk populasi disimbolkan oleh huruf Yunani “mu atau \(\mu\)”.
Pada Persamaan (1), jika data terdiri dari banyak grup maka nilai rata-rata dihitung berdasarkan jumlah nilai observasi dikali dengan bobotnya. Nilai mean tersebut disebut sebagai weighted mean yang dapat ditulis berdasarkan Persamaan Persamaan (2).
\[\begin{equation} \overline{X}\ =\text{}\sum_{_{i=1}}^n\overline{X_i}\cdot\frac{n_i}{n} \tag{2} \end{equation}\]dimana \(\overline{X_i}\) merupakan nilai rata-rata grup ke-i dan \(\frac{n_i}{n}\) merupakan bobot pengali yang berupa rasio antara observasi grup ke-i dengan keseluruhan observasi.
Kita biasanya akan berhadapan dengan nilai observasi yang baru sehingga nilai mean yang telah ada akan ikut berubah. Perubahan nilai mean tersebut disebabkan karena setiap observasi yang disertakan dalam perhitungan mean memiliki pengaruhnya masing-masing. Jika observasi tersebut cenderung ekstrim besar maka nilai mean akan bergeser menuju kearahnya begitu juga sebaliknya.
Pengaruh dari sebuah nilai observasi ke-j atau \(X_j\) dapat dilihat dengan menghitung seluruh observasi secara bersamaan kecuali observasi ke-j pada sebuah grup. Dapat dituliskan pada Persamaan (4)
\[\begin{equation} \overline{X} =\text{}\overline{X_{\left(j\right)}}\ \cdot\frac{\left(n-1\right)}{n}+X_j\cdot\frac{1}{n} \tag{3} \end{equation}\] \[\begin{equation} \overline{X} =\overline{X}_{\left(j\right)}+\left(X_j-\overline{X}_{\left(j\right)}\right)\cdot\frac{1}{n} \tag{4} \end{equation}\]dimana \(\overline{X}_{\left(j\right)}\) adalah nilai mean seluruh observasi kecuali \(X_j\). Setiap observasi yang mempengaruhi nilai mean keseluruhan (\(\overline{X}\)) didefinisikan oleh \(\left(X_j-\overline{X}_{\left(j\right)}\right)\) sebagai jarak antara observasi tersebut dengan nilai rata-rata yang tidak termasuk observasi tersebut di dalamnya. Sehingga seluruh nilai observasi tidak memiliki pengaruh yang sama terhadap nilai rata-rata seluruh observasi.
Outlier merupakan observasi yang memiliki nilai yang ekstrim tinggi atau rendah dibanding seluruh observasi yang ada sehingga memiliki pengaruh yang besar terhadap nilai mean keseluruhan (\(\overline{X}\)). Pengaruhnya yang sangat besar terhadap nilai rata-rata keseluruhan akan menyebabkan nilai rata-rata akan bergeser ke arah outlier tersebut. Selain itu penampilan dari distribusi frekuensi yang terbentuk akan terlihat memiliki ekor yang panjang.
Untuk lebih memahami pengaruh observasi terhadap nilai rata-rata, disajikan dua buah gambar yaitu: Gambar 1 dan Gambar 2
## Warning: package 'knitr' was built under R version 3.5.3
Figure 1: Nilai mean (segitiga) sebagai titik kesetimbangan pada data.
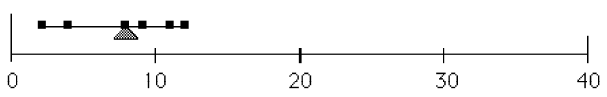
Figure 2: Pergeseran nilai mean (segitiga) ke kiri setelah penghilangan outlier.
Pada Gambar 1 disajikan 7 buah data konsentrasi TSS di suatu sungai. Nilai rata-rata TSS pada sungai tersebut adalah 11 mg/l. Jika kita amati sebagian besar data (6 observasi) berada pada rentang nilai konsentrasi TSS 2 sampai 12 mg/l. Observasi yang lain terletak jauh dari mayoritas observasi lainnya yaitu sebesar 37 mg/l. Observasi yang berbeda secara ekstrim dari nilai secara umum pada suatu data disebut sebagai outlier. Nilai outlier tersebut menyebabkan nilai rata-rata yang terbentuk tidak representatif terhadap keseluruhan data yang ada dan cenderung menggeser nilai rata-rata mendekati nilai outlier tersebut. Nilai observasi yang ekstrim biasanya muncul dari adanya kesalahan perlakuan terhadap sampel seperti botol sampel yang digunakan tidak bersih atau prosedur analisa yang dilakukan tidak standar sehingga memungkinkan adanya partikulat udara yang terukur pada proses penimbangan.
Salah satu cara untuk menangani adanya outlier tersebut adalah dengan menghapus observasi yang merupakan outlier. Pada Gambar 2 terlihat bahwa penghapusan outlier telah menggeser nilai rata-rata ke kiri. Nilai rata-rata yang baru tersebut jika diperhatikan dari Gambar 2 lebih menggambarkan keseluruhan data yang ada. Tidak terlihat adanya nilai yang berada jauh jaraknya dari nilai rata-rata yang baru.
Pada contoh tersebut dapat kita simpulkan bahwa nilai mean sangat sensitif terhadap adanya outlier. Pada prakteknya nilai mean tidaklah berdiri sendiri selama proses analisa. Nilai mean memerlukan nilai lain seperti median untuk menganalisa apakah data yang diperoleh tidak simetris yang dapat mengindikasikan adanya outlier.
Pada R untuk menghitung nilai rata-rata, kita dapat menggunakan fungsi mean(). Format fungsi yang digunakan dituliskan pada persamaan berikut:
mean(x, trim = 0, na.rm = FALSE)Note:
- x: objek atau vektor numerik.
- trim: menyatakan fraksi data (berkisar antara 0 sampai 0,5) yang perlu dilakukan pemotongan (trim) pada observasi awal dan akhir x (yang telah diurutkan) sebelum nilai mean dihitung. na.rm: nilai logis yang menyatakan apakah missing value perlu disertakan dalam perhitungan atau tidak. Jika disertakan maka output yang akan dihasilkan adalah NA.
Analisa Nilai Mean Grup Data Tunggal (Single Group)
Untuk lebih memahami penerapannya pada R, pada Tabel 1 berikut disajikan data terkait debit air suatu sungai.
## Warning: package 'tibble' was built under R version 3.5.3| observasi | debit |
|---|---|
| 1 | 457 |
| 2 | 185 |
| 3 | 133 |
| 4 | 160 |
| 5 | 119 |
| 6 | 115 |
| 7 | 101 |
| 8 | 58 |
| 9 | 68 |
| 10 | 50 |
| 11 | 65 |
| 12 | 128 |
Data pada Tabel 1 dapat divisualisasikan seperti pada Gambar 3:

Figure 3: Visualisasi debit sungai pada sampel
Berdasarkan Gambar 3, terdapat outlier yang ditunjukkan pada debit sungai yang lebih besar dari 400 m3/detik. Hasil tersebut dapat terjadi salah satunya karena adanya kondisi ekstrim seperti banjir yang menyebabkan sungai meluap atau terjadi kesalahan pengukuran dari alat ukur yang ada di lapangan.
Untuk menghitung nilai rata-rata debit pada data tersebut, masukkan variabel debit yang telah penulis simpan sebagai objek sungai kedalam fungsi mean() seperti berikut:
mean(sungai$debit)## [1] 136.5833Berdasarkan hasil yang diperoleh, dapat dilihat bahwa nilai rata-rata debit pada sungai tersebut adalah 136.5833333 \(m^3/detik\).
Kita dapat menghitung nilai mean dengan terlebih dahulu menghilangkan outlier pada data. Untuk melakukannya kita perlu melakukan subset terhadap data tanpa outlier di dalamnya sebelum data tersebut dimasukkan kedalam fungsi mean(). Berikut sintaks yang digunakan untuk melakukan hal tersebut:
# memuat paket
library(dplyr)
# melakukan filter terhadap data
sungai_subset<-sungai%>%
filter(debit<=400)
# menghitung mean
mean(sungai_subset$debit)## [1] 107.4545Berdasarkan hasil yang diperoleh terlihat bahwa nilai rata-rata yang baru lebih kecil dari yang sebelumnya (bergeser ke kiri) dengan nilai mean debit sungai yang baru sebesar 107.4545455 \(m^3/detik\). Hal ini terjadi karena pengaruh dari data outlier yang telah dihilangkan.
Analisa Nilai Rata-Rata Berdarsarkan Grup Data
Pada contoh sebelumnya kita telah melakukan perhitungan nilai mean untuk studi kasus grup tunggal. Pada contoh ini akan disajikan contoh kasus perhitungan nilai mean untuk data berkelompok.
Dataset pada contoh kasus ini diambil dari buku Statistical Methods in Water Resources. Data yang digunakan adalah data konsentrasi TDS dan Uranium di airtanah dengan perbedaan konsentrasi bikarbonate dalam air tanah yaitu \(\leq 50\)% (0) dan \(>50\)% (1). Dataset yang digunakan disajikan pada Tabel 2.
Note: data yang digunakan dapat diunduh pada link berikut google.drive. Simpan dataset tersebut pada working directory pembaca agar mudah dalam proses membaca data.
# memuat library
library(readxl)## Warning: package 'readxl' was built under R version 3.5.3# memuat data excel
data_gw <- read_excel("hhappc.xls", sheet="appc16")
# membuang kolom ke-4
data_gw<-data_gw %>%
select(TDS, Uranium, Bicarbonate) %>%
mutate(Bicarbonate=as.factor(Bicarbonate))| TDS | Uranium | Bicarbonate |
|---|---|---|
| 682.65 | 0.9315 | 0 |
| 819.12 | 1.9380 | 0 |
| 303.76 | 0.2919 | 0 |
| 1151.40 | 11.9042 | 0 |
| 582.42 | 1.5674 | 0 |
| 1043.39 | 2.0623 | 0 |
| 634.84 | 3.8858 | 0 |
| 1087.25 | 0.9772 | 0 |
| 1123.51 | 1.9354 | 0 |
| 688.09 | 0.4367 | 0 |
| 1174.54 | 10.1142 | 0 |
| 599.50 | 0.7551 | 0 |
| 1240.81 | 6.8559 | 0 |
| 538.35 | 0.4806 | 0 |
| 607.75 | 1.1452 | 0 |
| 705.89 | 6.0876 | 0 |
| 1290.57 | 10.8823 | 0 |
| 526.09 | 0.1473 | 0 |
| 784.68 | 2.6741 | 0 |
| 953.14 | 3.0918 | 0 |
| 1149.31 | 0.7592 | 0 |
| 1074.22 | 3.7101 | 0 |
| 1116.59 | 7.2446 | 0 |
| 301.20 | 5.7129 | 1 |
| 265.45 | 4.7366 | 1 |
| 295.88 | 2.8057 | 1 |
| 442.36 | 5.6290 | 1 |
| 342.71 | 3.0950 | 1 |
| 361.30 | 3.5774 | 1 |
| 262.07 | 1.7711 | 1 |
| 546.22 | 11.2724 | 1 |
| 273.89 | 4.9807 | 1 |
| 281.38 | 4.0833 | 1 |
| 588.86 | 14.6342 | 1 |
| 574.11 | 12.3835 | 1 |
| 307.09 | 1.5291 | 1 |
| 409.37 | 4.4647 | 1 |
| 327.07 | 2.4574 | 1 |
| 425.69 | 6.3042 | 1 |
| 310.05 | 4.5441 | 1 |
| 289.75 | 0.9672 | 1 |
| 408.18 | 2.1568 | 1 |
| 383.04 | 8.3810 | 1 |
| 255.19 | 2.7957 | 1 |
Visualisasi data Tabel 2, disajikan pada Gambar 4 dan Gambar 5:
## Warning: package 'ggthemes' was built under R version 3.5.3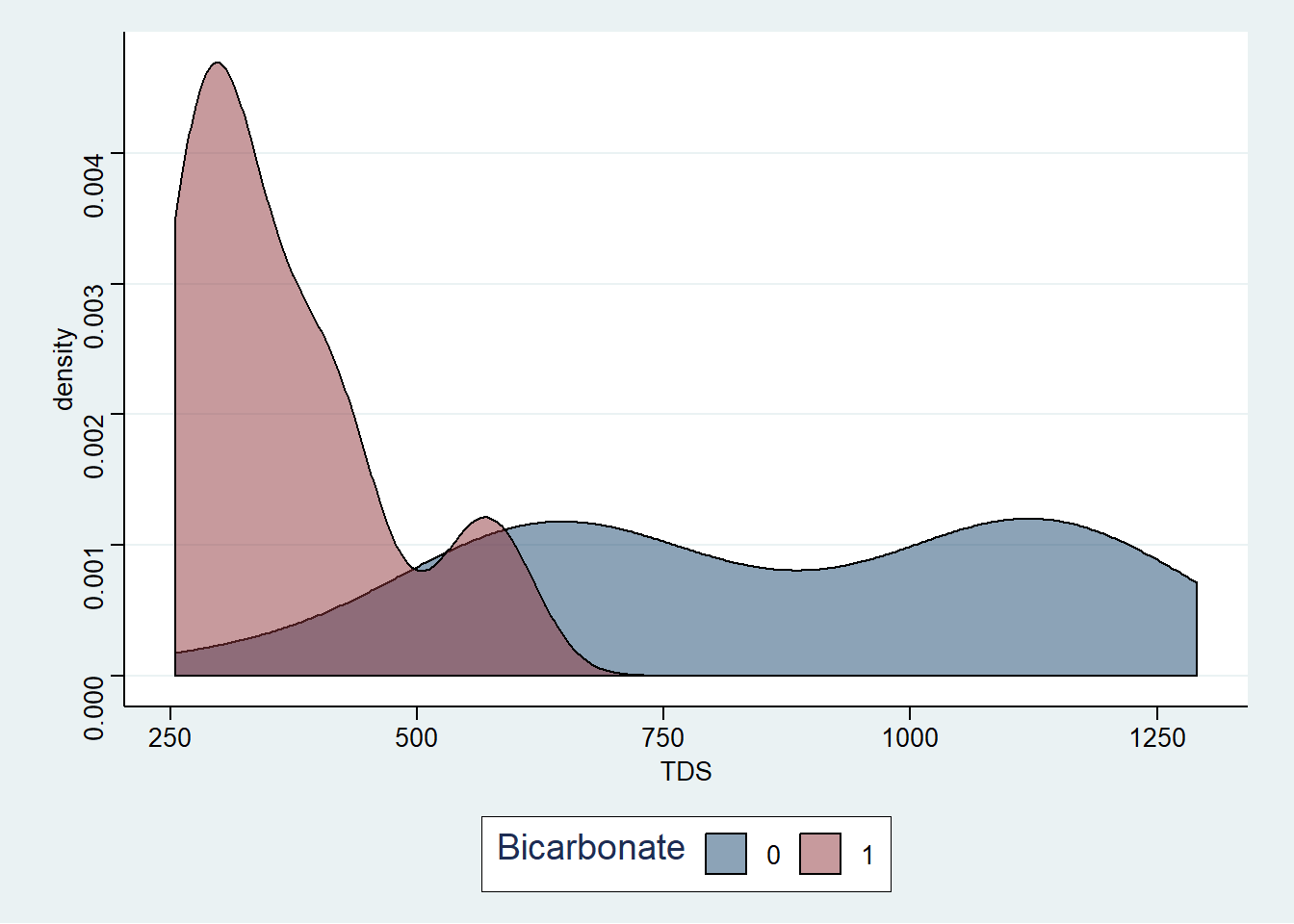
Figure 4: Visualisasi konsentrasi TDS pada air tanah
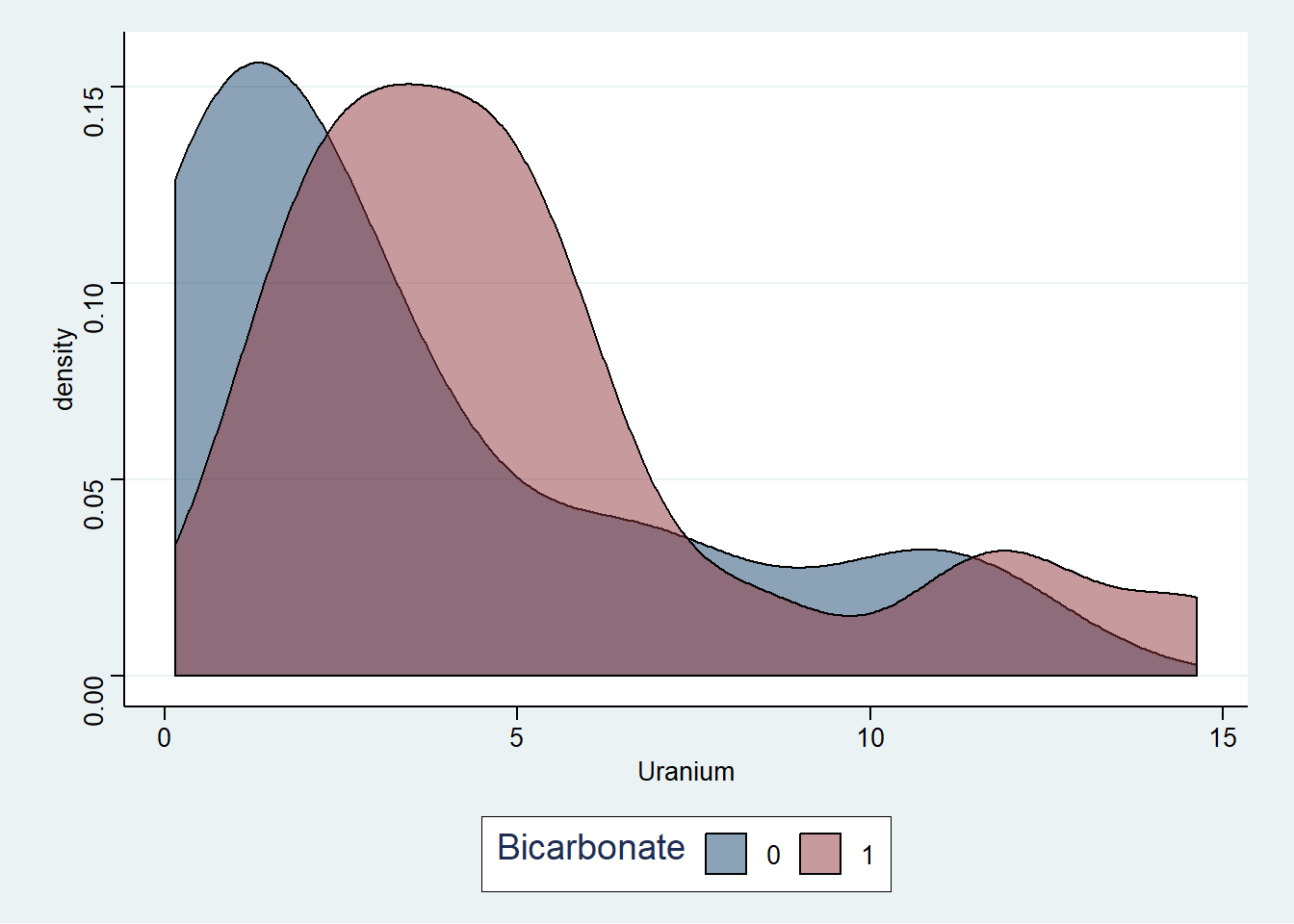
Figure 5: Visualisasi konsentrasi Uranium pada air tanah
Pada dataset tersebut kita ingin melihat apakah terdapat perbedaan antara konsentrasi TDS dan uranium pada kondisi kesadahan bikarbonat \(\leq 50\)% dan \(> 50\)%. Untuk melakukannya pada R kita perlu mengelompokkan data tersebut terlebih dahulu berdasarkan variabel bikarbonat. Setelah itu nilai rata-rata dapat dihitung. Berikut sintaks yang digunakan:
data_gw %>%
group_by(Bicarbonate) %>%
summarize(TDS = mean(TDS), Uranium = mean(Uranium))## # A tibble: 2 x 3
## Bicarbonate TDS Uranium
## <fct> <dbl> <dbl>
## 1 0 864. 3.47
## 2 1 364. 5.16Berdasarkan hasil yang diperoleh konsentrasi TDS dan Uranium dipengaruhi oleh kesadahan airtanah. Pada konsentrasi Bikarbonate > 50% konsentrasi TDS akan lebih rendah sedangkan konsentrasi Uranium sebaliknya. Untuk menguji apakah nilai tersebut berbeda signifikan, kita perlu melakukan uji hipotesis yang akan dibahas pada Chapter selanjutnya.
6.1.2 Median Sebagai Ukuran Pemusatan Data yang Resistan
Median atau persentil 50 (\(P_{50}\)) merupakan nilai pusat dari distribusi suatu data yang telah dirangkin berdasarkan besar nilai orbservasinya. Untuk data dengan jumlah observasi ganjil median adalah titik tengah yang memiliki jumlah observasi yang sama baik di atas nilai media maupun di bawahnya. Untuk data dengan jumlah observasi genap, media merupakan rata-rata dari dua titik observasi pusat. Untuk memperoleh median dari suatu distribusi data, langkah pertama yang perlu dilakukan adalah mengurutkan data dari observasi dengan nilai terkecil sampai dengan yang besar sehingga \(x_1\) merupakan observasi terkecil hingga \(x_n\) merupakan observasi terbesar. Persamaan (5) (untuk data ganjil) dan Persamaan (6) (untuk data genap) merupakan persamaan untuk menghitung median berdasarkan jumlah observasi yang ada.
\[\begin{equation} Median (P_{0.5}) =\frac{X_{\left(n+1\right)}}{2} \tag{5} \end{equation}\] \[\begin{equation} Median (P_{0.5}) =\frac{1}{2}\cdot\left(X_{\left(\frac{n}{2}\right)}+X_{\left(\frac{n}{2}\right)+1}\right) \tag{6} \end{equation}\]Median hanya dipengaruhi minimal oleh besarnya nilai observasi tunggal, yang ditentukan semata-mata oleh urutan relatif observasi. Resitensi terhadap efek dari perubahan nilai atau kehadiran pengamatan terpencil (outlier) sering merupakan sifat yang diinginkan. Meski demikian median memiliki kelemahan utama yaitu kurang representatif dalam mendeskripsikan rata-rata dari data dibandingkan mean. Hal ini disebabkan karena median tidak menggunakan seluruh nilai yang ada pada data.
Analisa Nilai Median Grup Data Tunggal (Single Group)
Kita akan menggunakan kembali data pada Tabel 1 untuk menghitung median data tersebut. Pada R median dihitung menggunakan fungsi median(). Fotmat yang digunakan adalah sebagai berikut:
median(x, na.rm = FALSE)Note:
- x: objek atau vektor numerik.
- na.rm: nilai logis yang menyatakan apakah missing value perlu disertakan dalam komputasi atau tidak.
Untuk data pada Tabel 1, median dapat dihitung menggunakan sintaks berikut:
median(sungai$debit)## [1] 117Berdasarkan hasil komputasi diperoleh median debit sungai sebesar 117 \(m^3/detik\). Nilai tersebut tidak berbeda juah dengan nilai mean tanpa outlier data sungai sebesar 107.4545455 \(m^3/detik\).
Jika kita melakukan perhitungan menggunakan menggunakan data sungai_subset (tanpa outlier), maka diperoleh 115 \(m^3/detik\) yang nilainya juga tidak bergeser jauh dengan median sebelumnya yang membuktikan bahwa median resisten terhadap outlier.
Analisa Nilai Median Berdarsarkan Grup Data
Paca contoh ini kita akan menggunakan kembali data pada Tabel 2. Sintaks berikut adalah cara menghitung median untuk data berkelompok:
data_gw %>%
group_by(Bicarbonate) %>%
summarize(TDS=median(TDS), Uranium=median(Uranium))## # A tibble: 2 x 3
## Bicarbonate TDS Uranium
## <fct> <dbl> <dbl>
## 1 0 819. 1.94
## 2 1 327. 4.46Pada median TDS kita tidak menemui perbedaan dengan nilai rata-ratanya. Hal ini disebabkan karena bentuk distribusinya yang relatif simetris. Sedangkan pada Uranium distribusi yang terbentuk memiliki kemencengan (skewness) positif. Hal ini menyebabkan nilai mean yang terbentuk akan sangat dipengaruhi oleh observasi dengan nilai ekstrim yang dimiliki.
6.1.3 Ukuran Pemusatan Data Lainnya
Ukuran pemusatan data lainnya yang kurang sering digunakan adalah modus, rata-rata geometrik (geometric mean), dan trimmed mean. Modus merupakan nilai observasi yang sering muncul. Jika kita visualisasikan menggunakan histogram maka modus merupakan bar tertinggi pada histogram. Modus lebih dapat diaplikasikan pada data berkelompok yang nilai observasinya merupakan integer (finite number) dibanding data dengan nilai kontinyu. Modus sangat mudah diperoleh, namun sangat buruk sebagai ukuran pemusatan data untuk jenis data kontinyu karena sering bergantung pengelompokan data yang sewenang-wenang atu semaunya.
Geometric mean sering digunakan untuk distribusi data memiliki bentuk kemencengan positif. Geometric mean merupakan rata-rata logaritmik yang diubah kembali ke unit asalnya. Untuk menghitungnya digunakan Persamaan (7).
\[\begin{equation} GM = \exp\left(\overline{Y}\right) \tag{7} \end{equation}\]dimana
\[\begin{equation} Y_i = \ln\left(X_i\right) \tag{8} \end{equation}\]Untuk data yang memiliki kemencengan positif, geometric mean biasanya cukup dekat dengan median. Bahkan, ketika logaritma data simetris, geometric mean adalah estimasi median. Ini karena median dan geometric mean sama. Ketika ditransformasikan kembali ke satuan asli, rerata geometris terus menjadi estimasi untuk median, tetapi bukan merupakan estimasi untuk rerata.
Pada R geometric mean dapat kita hitung menggunakan sintaks fungsi yang kita buat sendiri:
geomean <- function(x){
y = log(x)
GM = exp(mean(y))
return(GM)
}Data pada Tabel 1 merupakan data dengan kemencengan positif. Nilai geometric mean data tersebut dihitung menggunakan sintaks berikut:
geomean(sungai$debit)## [1] 112.4315Berdasarkan hasil komputasi diperoleh nilai geometric mean debit sungai sebesar 112.431498 \(m^3/detik\). Nilai yang diperoleh tidak berbeda dengan nilai median sebesar 117 \(m^3/detik\).
Kompromi antara median dan mean tersedia dengan memotong beberapa observasi terendah dan tertinggi, dan menghitung mean dari apa yang tersisa. Perkiraan pemusatan data seperti itu tidak dipengaruhi oleh observasi yang paling ekstrem (dan mungkin anomali), seperti mean. Namun mereka memungkinkan besarnya sebagian besar nilai untuk mempengaruhi estimasi, tidak seperti median. Estimator ini disebut “trimmed mean”, dan persentase data yang diinginkan dapat dipangkas. Pemangkasan yang paling umum adalah menghapus 25 persen dari data di setiap ujung - rata-rata yang dihasilkan dari 50 persen pusat data biasanya disebut “trimmed mean”, tetapi lebih tepatnya 25 persen trimmed mean. “trimmed mean 0%” adalah mean sampel itu sendiri, sementara memangkas semua kecuali 1 atau 2 nilai pusat menghasilkan median. Persentase pemangkasan harus secara eksplisit dinyatakan saat digunakan. Trimmed mean adalah estimator yang resistan, karena tidak sangat dipengaruhi oleh outlier, dan bekerja dengan baik untuk berbagai macam bentuk distribusi (normal, lognormal, dll). Ini dapat dianggap sebagai rata-rata tertimbang (weighted mean), di mana data di luar ‘jendela’ cutoff diberi bobot 0, dan mereka yang berada di dalam jendela bobot 1,0 (lihat Gambar 6).
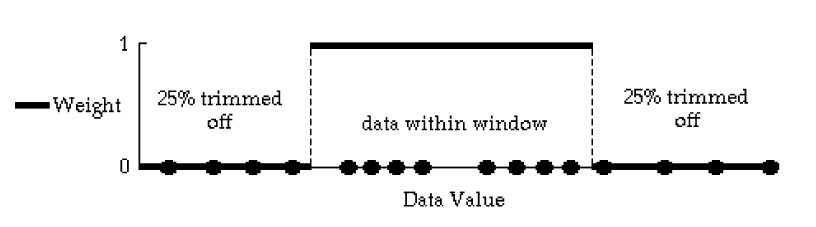
Figure 6: Jendela diagram trimmed mean.
Pada R trimmed mean dapat dihitung dengan spesifikasi argumen trim pada fungsi mean(). Pada data debit sungai (Tabel 1) dihitung trimmed mean dengan data yang dipangkas adalah 5% di kedua ujung observasi atau trim=0.1.
mean(sungai$debit, trim=0.1)## [1] 113.2Nilai yang diperoleh sekarang mendekati nilai median dan geometric mean yaitu sebesar 113.2 \(m^3/detik\).
6.2 Ukuran Sebaran Data
Saat kita mengetahui kedalaman rata-rata sungai, kita pasti ingin mengetahui berapa rentang atau variasi dari kedalamannya. Kita tidak cukup hanya dengan mengetahui nilai pemusatan datanya saja, kita juga perlu mengetahui seberapa besar variasi atau variabilitas datanya.
Variabilitas suatu data diukur dengan melihat sebaran data dari nilai rata-ratanya (mean). Semakin besar sebaran suatu data, semakin tidak berarti nilai rata-ratanya karena nilai rata-ratanya bisa sangat berbeda dari sejumlah nilai pada datanya.
6.2.1 Pengukuran Klasik (Varian dan Simpangan Baku)
Varian sampel dan nilai akar dari varian sampel (Simpangan Baku) merupakan ukuran penyebaran data klasik. Sama dengan mean varian dan simpangan baku dipengaruhi oleh outlier. Semakin besar nilai keduanya, semakin besar variabilitas datanya. Kedua ukuran tersebut dinyatakan pada Persamaan (9) dan Persamaan (10).
Varian Sampel
\[\begin{equation} s^2=\sum_{i=1}^n\frac{\left(X_i-\overline{X}\right)^2}{\left(n-1\right)} \tag{9} \end{equation}\]simpangan baku
\[\begin{equation} s=\sqrt{s^2} \tag{10} \end{equation}\]Kedua nilai tersebut di hitung berdasarkan kuadrat deviasi nilai observasi dari rata-ratanya, sehingga jika pada data terdapat outlier maka nilai outlier akan memperbesar deviasi data dari nilai mean. Ketika outlier hadir, pengukuran menjadi tidak stabil. Hal ini akan memberi kesan sebaran data menjadi jauh lebih besar daripada yang ditunjukkan oleh mayoritas nilai pada data.
Varian dan simpangan baku pada R dihitung menggunakan fungsi var() (varian) dan sd(). Format yang digunakan adalah sebagai berikut:
var(x, na.rm = FALSE)
sd(x, na.rm = FALSE)Note:
- x: objek atau vektor numerik.
- na.rm: nilai logis yang menyatakan apakah missing value perlu disertakan dalam komputasi atau tidak.
Analisa Varian dan simpangan baku Grup Tunggal
Kita akan menggunakan kembali data pada Tabel 1 untuk menghitung varian dan simpangan baku data tersebut. Berikut adalah sintaks untuk melakukannya:
# varian data sungai
var(sungai$debit)## [1] 11926.08# simpangan baku data sungai
sd(sungai$debit)## [1] 109.2066Sekarang mari kita bandingkan dengan data yang tidak menyertakan outlier.
# varian data sungai
var(sungai_subset$debit)## [1] 1918.673# simpangan baku data sungai
sd(sungai_subset$debit)## [1] 43.80266Berdasarkan hasil yang diperoleh terlihat bahwa nilai varian dan simpangan baku data dengan outlier jauh lebih besar dibanding data tanpa outlier.
Analisa Varian dan simpangan baku Multi Grup
Paca contoh ini kita akan menggunakan kembali data pada Tabel 2. Sintaks berikut adalah cara menghitung varian dan simpangan baku untuk data berkelompok:
data_gw %>%
group_by(Bicarbonate) %>%
summarize(var_TDS=var(TDS), var_Uranium=var(Uranium),
sd_TDS=sd(TDS), sd_Uranium=sd(Uranium))## # A tibble: 2 x 5
## Bicarbonate var_TDS var_Uranium sd_TDS sd_Uranium
## <fct> <dbl> <dbl> <dbl> <dbl>
## 1 0 79471. 13.0 282. 3.61
## 2 1 10559. 13.5 103. 3.68Jika kita perhatikan nilai varian dan simpangan baku Uranium pada dua kondisi kesadahan memiliki nilai yang nyaris sama. Hal sebaliknya terjadi pada variabel TDS yang menunjukkan perbedaan pada dua ukuran sebaran datanya. TDS pada kesadahan >50% memiliki varian dan simpangan baku yang lebih kecil dibanding kondisi kesadahan satunya, yang menunjukkan data pada kondisi kesadahan >50% lebih tidak tersebar dibanding kesadahan satunya.
6.2.2 Ukuran Sebaran Data yang Resisten Terhadap Outlier
Simpangan kuartil atau interquartile range (IQR) merupakan ukuran sebaran data yang resisten dan paling sering digunakan. IQR mengukur kisaran 50% pusat data sehingga pengukuran tidak dipengaruhi oleh adanya outlier pada 25% pada data pada setiap ujungnya. Untuk visualisasinya kita dapat melihat kembali pada ambar 6.
IQR didefinisikan sebagai persentil ke-75 dikurangi dengan persentil ke-25. Persentil ke-75, ke-50 (median) dan ke-25 membagi data menjadi empat tempat berukuran sama. Persentil ke-75 (\(P_{.75}\)), juga disebut kuartil atas, adalah nilai yang melebihi tidak lebih dari 75% data dan dilampaui oleh tidak lebih dari 25 persen data. Persentil ke-25 (\(P_{.25}\)) atau kuartil lebih rendah adalah nilai yang melebihi tidak lebih dari 25% dari data dan dilampaui oleh tidak lebih dari 75%. Dengan mempertimbangkan data yang telah diurutkan dari yang terkecil ke yang terbesar: \(X_{i}\), \(i=1,...n\). Persentil (\(P_j\)) dihitung berdasarkan Persamaan (11).
\[\begin{equation} P_j=X_{\left(n+1\right)\cdot j} \tag{11} \end{equation}\]dimana \(n\) merupakan ukuran sampel \(X_j\), dan \(j\) merupakan fraksi data yang kurang dari atau sama dengan nilai persentil (untuk persentil ke-25, 50, dan 75, \(j=.25, .50., dan .75\)).
Pada R, IQR dapat dihitung secara langsung menggunakan fungsi IQR() atau secara tidak langsung menggunakan fungsi quantile(). Penggunaan fungsi quantile() digunakan untuk mencari persentil dari data. Telah dijelaskan sebelumnya bahwa IQR merupakan selisih dari persentil 75 dan persentil 25. Format yang digunakan untuk menghitung IQR adalah sebagai berikut:
# secara langsung
IQR(x, na.rm=FALSE)
# secara tidak langsung
quantile(x, 3/4)-quantile(x, 1/4)
# atau
quantile(x, .75)-quantile(x, .25)Note:
- x: objek atau vektor numerik.
- na.rm: nilai logis yang menyatakan apakah missing value perlu disertakan dalam komputasi atau tidak.
Pada Tabel 1, kita dapat menghitung IQR dari data. Berikut adalah contoh sintaks yang digunakan:
IQR(sungai$debit)## [1] 72.5Salah satu penaksir penyebaran yang resisten selain IQR adalah Median Absolute Deviation, atau MAD. MAD dihitung dengan pertama-tama mendaftar nilai absolut dari semua selisih \(|d|\) antara masing-masing pengamatan dan median. Median dari nilai absolut ini adalah MAD yang ditulis berdasarkan Persamaan (12).
\[\begin{equation} MAD\ \left(X_i\right)=median\left|d\right| \tag{12} \end{equation}\]dimana
\[\begin{equation} d_i=X_i-median\left(X_i\right) \tag{13} \end{equation}\]Pada R, MAD tidak dapat dihitung secara langsung. Kita perlu membuat user defined function untuk dapat digunakan sewaktu-waktu. Berikut adalah fungsi yang dibuat:
MAD <- function(x){
# median data
m = median(x)
# MAD
d = abs(x-m)
mad = mean(d)
# print
return (mad)
}Pada Tabel 1, kita dapat menghitung MAD dari data menggunakan fungsi yang telah dibuat. Berikut adalah contoh sintaks yang digunakan:
MAD(sungai$debit)## [1] 60.416676.3 Ringkasan Data Menggunakan Fungsi summary dan stat.des
Ringkasan data menggunakan fungsi summary() akan memberikan ringkasan data seperti nilai mean, kuartil, nilai minimum dan maksimum, serta missing value. Jika data berupa variabel tunggal maka output yang dihasilkan berupa nilai-nilai yang telah penulis sebutkan sebelumnya. Berikut adalah contoh sintaks yang digunakan:
summary(sungai$debit)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 50.00 67.25 117.00 136.58 139.75 457.00Jika objek yang diinputkan kedalam fungsi tersebut adalah data frame, maka ringkasan data akan diberikan pada setiap kolom dengan ketentuan berikut:
- jika kolom berupa variabel numerik maka output yang diperoleh berupa mean, median, min, max dan kuartil.
- jika kolom berupa factor maka output yang dihasilkan berupa rekapan jumlah observasi pada masing-masing grup.
Berikut adalah contoh sintaks penerapannya:
summary(data_gw)## TDS Uranium Bicarbonate
## Min. : 255.2 Min. : 0.1473 0:23
## 1st Qu.: 322.8 1st Qu.: 1.5578 1:21
## Median : 560.2 Median : 3.0934
## Mean : 625.7 Mean : 4.2764
## 3rd Qu.: 852.6 3rd Qu.: 5.8066
## Max. :1290.6 Max. :14.6342Ringkasan data lain dapat dilakukan dengan menggunakan fungsi stat.desc() dari library pastecs. Kelebihan dari ringkasan data menggunakan fungsi ini adalah kita tidak hanya memperoleh ringkasan data dengan ouput seperti diatas, namun kita juga memperoleh output berupa nilai standadr error (SE), confidence interval (CI), dan koefisien variasi (coef.var) yang merupakan hasil bagi dari simpangan baku dibagi dengan nilai rata-rata.
Berikut adalah sintak yang digunakan untuk menghasilkan ringkasan data menggunakan fungsi stat.desc():
# memasang paket
install.packages("pastecs")# memuat paket
library(pastecs)## Warning: package 'pastecs' was built under R version 3.5.3# ringkasan data
stat.desc(data_gw)## TDS Uranium Bicarbonate
## nbr.val 4.400000e+01 44.0000000 NA
## nbr.null 0.000000e+00 0.0000000 NA
## nbr.na 0.000000e+00 0.0000000 NA
## min 2.551900e+02 0.1473000 NA
## max 1.290570e+03 14.6342000 NA
## range 1.035380e+03 14.4869000 NA
## sum 2.752873e+04 188.1604000 NA
## median 5.601650e+02 3.0934000 NA
## mean 6.256530e+02 4.2763727 NA
## SE.mean 4.985747e+01 0.5572310 NA
## CI.mean.0.95 1.005472e+02 1.1237633 NA
## var 1.093738e+05 13.6622791 NA
## std.dev 3.307171e+02 3.6962520 NA
## coef.var 5.285951e-01 0.8643428 NA6.4 Ukuran Kemencengan Data
Ketika data memiliki kemencengan, nilai mean tidak sama dengan median, tetapi bergeser ke arah ekor distribusi. Jadi untuk kemencengan positif, nilai mean melebihi lebih dari 50% dari data, seperti pada Gambar 7 dan Gambar 8. Simpangan baku juga meningkat dengan data di bagian ekor. Data yang menceng juga mempertanyakan penerapan tes hipotesis yang didasarkan pada asumsi bahwa data memiliki distribusi normal. Tes-tes ini, yang disebut tes parametrik, mungkin bernilai dipertanyakan ketika diterapkan pada data seperti data sumber daya air, karena data seringkali tidak normal atau bahkan simetris.
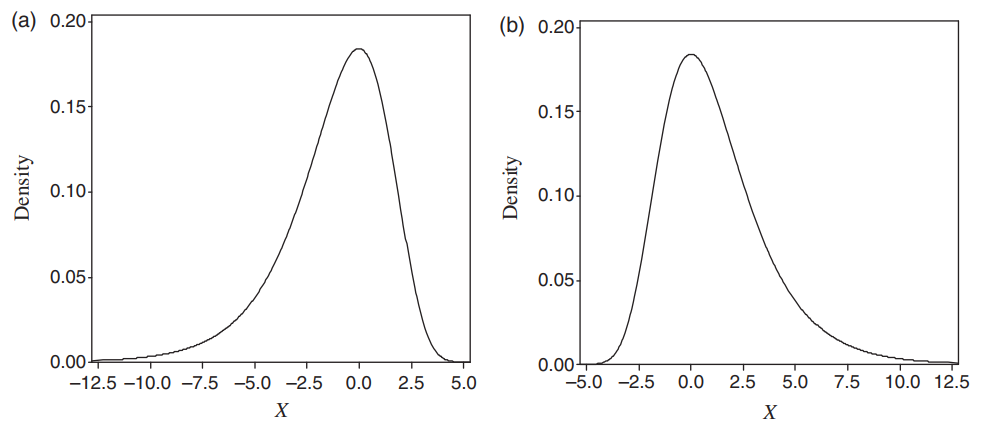
Figure 7: a) Kemencengan negatif, b) Kemencengan positif.
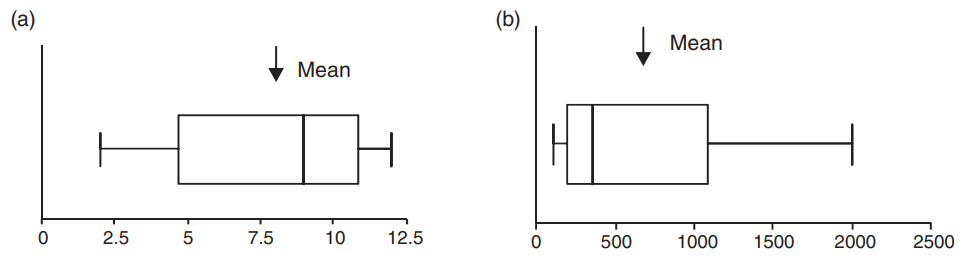
Figure 8: Box plot untuk data dengan a) Kemencengan negatif, b) Kemencengan positif.
6.4.1 Ukuran Kemencengan Klasik
Koefisien kemencengan (\(g\)) merupakan ukuran kemencengan yang sering digunakan. Koefisien kemencengan dituliskan pada Persamaan (14).
\[\begin{equation} g=\frac{n}{\left(n-1\right)\left(n-2\right)}\sum_{i=1}^n\frac{\left(x_i-\overline{X}\right)^3}{s^3} \tag{14} \end{equation}\]Kemencengan positif (ekor panjang kekanan) memiliki nilai \(g\) positif sedangkan kemencengan negatif (ekor panjang kekiri) memiliki nilai \(g\) negatif. Sekali lagi, Pengaruh beberapa outlier adalah penting - suatu distribusi simetris yang memiliki satu outlier akan menghasilkan ukuran kemencengan (\(g\)) yang besar (dan mungkin menyesatkan).
Pada R Kita dapat menghitung sendiri koefisien kemencengan (\(g\)) menggunakan user define function. Berikut adalah contoh sintaks fungsi yang dibuat:
skew <- function(x){
ave = mean(x)
n = length(x)
sd = sd(x)
g=(n/((n-1)*(n-2)))*sum(((x-ave)^3)/(sd^3))
return(g)
}Pada contoh sebelumnya dengan menggunakan fungsi yang telah dibuat diperoleh koefisien kemencengan sebagai berikut:
skew(data_gw$Uranium)## [1] 1.1844176.4.2 Ukuran Kemencengan yang Resisten
Ukuran kemencengan yang lebih resisten adalah *quartile skew coefficient8 (\(qs\)). Merupakan ukuran kemencengan didasarkan pada ketiga nilai kuartil data seperti yang ditunjukkan pada Persamaan (15) yang menyatakan perbedaan pada jarak kuartil atas dan bawah terhadap median dibagi dengan IQR.
\[\begin{equation} qs=\frac{\left(P_{.75}-P_{.50}\right)-\left(P_{.75}-P_{.25}\right)}{P_{.75}-P_{.25}} \tag{15} \end{equation}\]Kemencengan positif akan memiliki nilai \(qs\) positif dan begitupun sebaliknya. Pada R kita dapat menghitung nilai \(qs\) menggunakan user define function. Berikut adalah contoh sintaks fungsi yang dibuat:
qs <- function(x){
p75 = quantile(x, 3/4)
p50 = median(x)
p25 = quantile(x, 1/4)
skew = ((p75-p50)-(p50-p25))/(p75-p25)
return(skew)
}Pada contoh sebelumnya dengan menggunakan fungsi yang telah dibuat diperoleh koefisien kemencengan sebagai berikut:
qs(data_gw$Uranium)## 75%
## 0.27716396.5 Outlier
Outlier merupakan pengamatan yang nilainya sangat berbeda dari yang lain dalam kumpulan data, sering menimbulkan kekhawatiran atau alarm. Meskipun sebenarnya kita tidak perlu khawatir dengan adanya outlier . Outlier sering ditangani dengan membuangnya sebelum mendeskripsikan data, atau sebelum beberapa prosedur uji hipotesis chapter-chapter selanjutnya. Sekali lagi, mereka seharusnya tidak perlu dikhawatirkan. Outlier mungkin merupakan poin paling penting dalam kumpulan data dan harus diselidiki lebih lanjut.
Untuk lebih memahami kenapa outlier begitu penting pada data kita berikut merupakan contoh kasus dari asal kata outlier. Misalkan bahwa data pada “lubang” ozon Antartika, suatu daerah dengan konsentrasi ozon yang sangat rendah, telah dikumpulkan selama kurang lebih 10 tahun sebelum penemuan aktualnya. Namun, rutinitas pengecekan data otomatis selama pemrosesan data menyertakan instruksi untuk menghapus “outlier”. Definisi outlier didasarkan pada konsentrasi ozon yang ditemukan pada pertengahan garis lintang. Dengan demikian semua data yang tidak biasa ini tidak pernah dilihat atau dipelajari selama beberapa waktu. Jika outlier dihapus, risiko diambil hanya dengan melihat apa yang diharapkan dilihat. Jika hal tersebut dilakukan maka anomali yang terjadi pada atmosfer dapat luput kita pelajari.
Berdasarkan kasus tersebut kita perlu dengan baik mempertimbangkan apakah outlier pada data perlu dihapus atau tidak. Jika berkaitan dengan pembuatan model, penghapusan outlier merupakan sesuatu yang dapat memperbaiki akurasi dari model. Namun, pada sebuah penelitian terkadang diperlukan informasi lebih lanjut mengapa terdapat outlier pada data sehingga kita dapat memperoleh pengetahuan baru dari proses pencarian tersebut.
Outlier dapat terjadi karena tiga hal, yaitu:
- Kesalahan pengukuran atau perekaman data.
- Observasi dari populasi tidak sama dengan sebagian besar data seperti misalnya data debit banji akibat jebolnya sebuah bendungan akan berbeda dengan debit banjir akibat presipitasi.
- Kejadian langka pada sebuah populasi yang sedikit memiliki kemencengan pada distribusinya.
Metode grafis seperti box plot sangat membantu dalam mengidentifikasi outlier. Setiap kali outlier terjadi, pertama-tama verifikasi bahwa tidak ada penyalinan, titik desimal, atau kesalahan nyata lainnya yang telah dibuat. Jika tidak, tidak mungkin untuk menentukan apakah titik itu valid. Upaya yang dilakukan untuk verifikasi, seperti menjalankan kembali sampel di laboratorium, akan tergantung pada manfaat yang diperoleh versus biaya verifikasi. Kejadian masa lalu mungkin tidak dapat diduplikasi. Jika tidak ada kesalahan yang dapat dideteksi dan diperbaiki, ** outlier tidak boleh dibuang hanya berdasarkan fakta bahwa mereka tampak tidak biasa**. Outlier sering dibuang untuk membuat data cocok dengan distribusi teoretis yang sudah terbentuk sebelumnya seperti distribusi normal. Tidak ada alasan untuk menganggap bahwa mereka seharusnya dibuang! Seluruh rangkaian data dapat muncul dari distribusi yang memiliki kemencengan, dan mengambil logaritma atau transformasi lain dapat menghasilkan data yang cukup simetris. Bahkan jika tidak ada transformasi yang mencapai simetri, outlier tidak perlu dibuang. Daripada menghilangkan data aktual (dan mungkin sangat penting) untuk menggunakan prosedur analisis yang membutuhkan simetri atau normalitas, prosedur yang tahan terhadap outlier harus digunakan. Jika menghitung rata-rata tampak bernilai kecil karena outlier, median telah terbukti menjadi ukuran lokasi yang lebih tepat untuk data yang memiliki kemencengan. Jika melakukan uji-t (dijelaskan pada chapter selanjutnya) tampaknya tidak valid karena set data yang tidak normal, gunakan rank-sum test sebagai gantinya.
Singkatnya, biarkan panduan data prosedur analisis yang digunakan, daripada mengubah data untuk menggunakan beberapa prosedur yang memiliki persyaratan terlalu ketat untuk situasi yang dihadapi.
6.6 Transformasi Data
Transformasi data dilakukan untuk memenuhi tiga tujuan, antara lain:
- membuat data lebih simetris,
- membuat data lebih linier, dan
- membuat data memiliki varian yang konsisten.
Beberapa ilmuwan lingkungan takut bahwa dengan mentransformasikan data, hasilnya diperoleh yang sesuai dengan gagasan yang telah terbentuk sebelumnya. Oleh karena itu, transformasi adalah metode untuk melihat apa yang ingin kita lihat dari data. Namun dalam kenyataannya, masalah serius dapat terjadi ketika prosedur dengan asumsi simetri, linieritas, atau homoseksualitas (varians konstan) digunakan pada data yang tidak memiliki karakteristik yang diperlukan ini. Transformasi dapat menghasilkan karakteristik ini, dan dengan demikian penggunaan variabel yang diubah memenuhi tujuan.
Satu unit pengukuran tidak lebih valid secara apriori daripada yang lainnya. Sebagai contoh, logaritma negatif konsentrasi ion hidrogen (pH), sama validnya dengan sistem pengukuran dengan konsentrasi ion hidrogen itu sendiri. Transformasi seperti akar kuadrat kedalaman air pada sumur sumur, atau akar kubik volume curah hujan, seharusnya tidak mengandung stigma lebih daripada pH. Skala pengukuran ini mungkin lebih sesuai untuk analisis data daripada unit aslinya. Hoaglin (1988) telah menulis artikel yang bagus tentang transformasi tersembunyi, secara konsisten diterima begitu saja, yang umum digunakan oleh semua orang. Oktaf dalam musik adalah transformasi frekuensi logaritmik. Setiap kali piano dimainkan, transformasi logaritmik digunakan! Begitu pula dengan skala Richter untukgempa bumi, mil per galon untuk konsumsi bensin, f-stop untuk eksposur kamera, dll. semua menggunakan transformasi. Dalam ilmu analisis data, keputusan yang menggunakan skala pengukuran harus ditentukan oleh data, bukan dengan kriteria yang ditentukan sebelumnya. Tujuan penggunaan transformasi adalah untuk kesimetrian, linieritas, dan homoskedastisitas. Selain itu, penggunaan banyak teknik tahan seperti persentil dan prosedur uji nonparametrik (akan dibahas kemudian) tidak berbeda dengan skala pengukuran. Hasil rank-sum test, setara nonparametrik dari uji-t, akan persis sama apakah unit asli atau logaritma dari unit tersebut digunakan.
Untuk membuat distribusi asimetris menjadi lebih simetris, data dapat diubah atau diekspresikan kembali menjadi unit baru. Unit-unit baru ini mengubah jarak antara pengamatan pada plot garis. Efeknya adalah memperluas atau mengecilkan jarak ke pengamatan ekstrem di satu sisi median, membuatnya lebih pada setiap sisinya. Transformasi yang paling umum digunakan dalam bidang lingkungan adalah logaritma, seperti Log debit air, konduktivitas hidrolik, atau konsentrasi sering diambil sebelum analisis statistik dilakukan.
Transformasi data biasanya melibatkan fungsi power seperti pada fungsi \(y=x^\theta\), dimana x merupakan data yang belum ditransformasi, y adalah data yang telah ditransformasi, dan \(\theta\) merupakan power eksponensial. Pada Gambar 9 nilai \(\theta\) di-list kedalam “ladder of powers” (Velleman dan Hoaglin, 1981 dalam helsel dan Hirsch, 2002), sebuah struktur yang berguna untuk menentukan nilai \(\theta\) yang tepat.
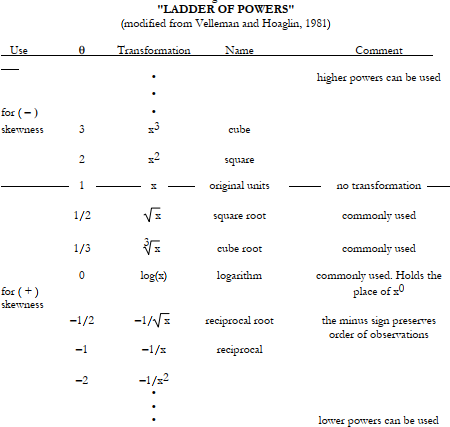
Figure 9: Ladder of power
Seperti yang dapat dilihat dari ladder of powers, setiap transformasi dengan \(\theta\) kurang dari 1 dapat digunakan untuk membuat data dengan kemencengan positif lebih simetris. Dengan membuat box plot atau plot Q-Q dari data yang diubah kita dapat mengetahui apakah transformasi yang telah dilakukan sesuai. Jika transformasi logaritmik memberikan kompensasi yang berlebihan untuk kemiringan yang tepat dan menghasilkan distribusi yang sedikit kiri (kemencengan negatif), transformasi ‘lebih ringan’ dengan \(\theta\) lebih dekat ke 1, seperti transformasi kuadrat atau akar kubik, harus digunakan. Transformasi dengan \(\theta\)> 1 akan membantu membuat data yang condong ke kiri lebih simetris.
Namun, kecenderungan untuk mencari transformasi ‘terbaik’ harus dihindari. Misalnya, ketika berhadapan dengan beberapa set data yang serupa, mungkin lebih baik untuk menemukan satu transformasi yang bekerja cukup baik untuk semua, daripada menggunakan yang sedikit berbeda untuk masing-masingnya. Harus diingat bahwa setiap set data adalah sampel dari populasi yang lebih besar, dan sampel lain dari populasi yang sama kemungkinan akan menunjukkan transformasi ‘terbaik’ yang sedikit berbeda. Penentuan ‘terbaik’ dalam ketelitian tinggi adalah pendekatan yang jarang sepadan dengan usaha.
Pada Gambar 5 kosentrasi distribusi Uranium pada tiap grup memiliki kemencengan positif. Untuk membuatnya simetris kita perlu melakukan transformasi yang sesuai jenis transformasi yang dilakukan dapat dimulai dari akar kuadrat sampai invers akar kuadrat (berdasarkan Gambar 9). Pada contoh ini kita akan mencoba melakukan trasnformasi logaritmik. Berikut adalah contoh visualisasi hasil transformasinya (lihat Gambar 10:
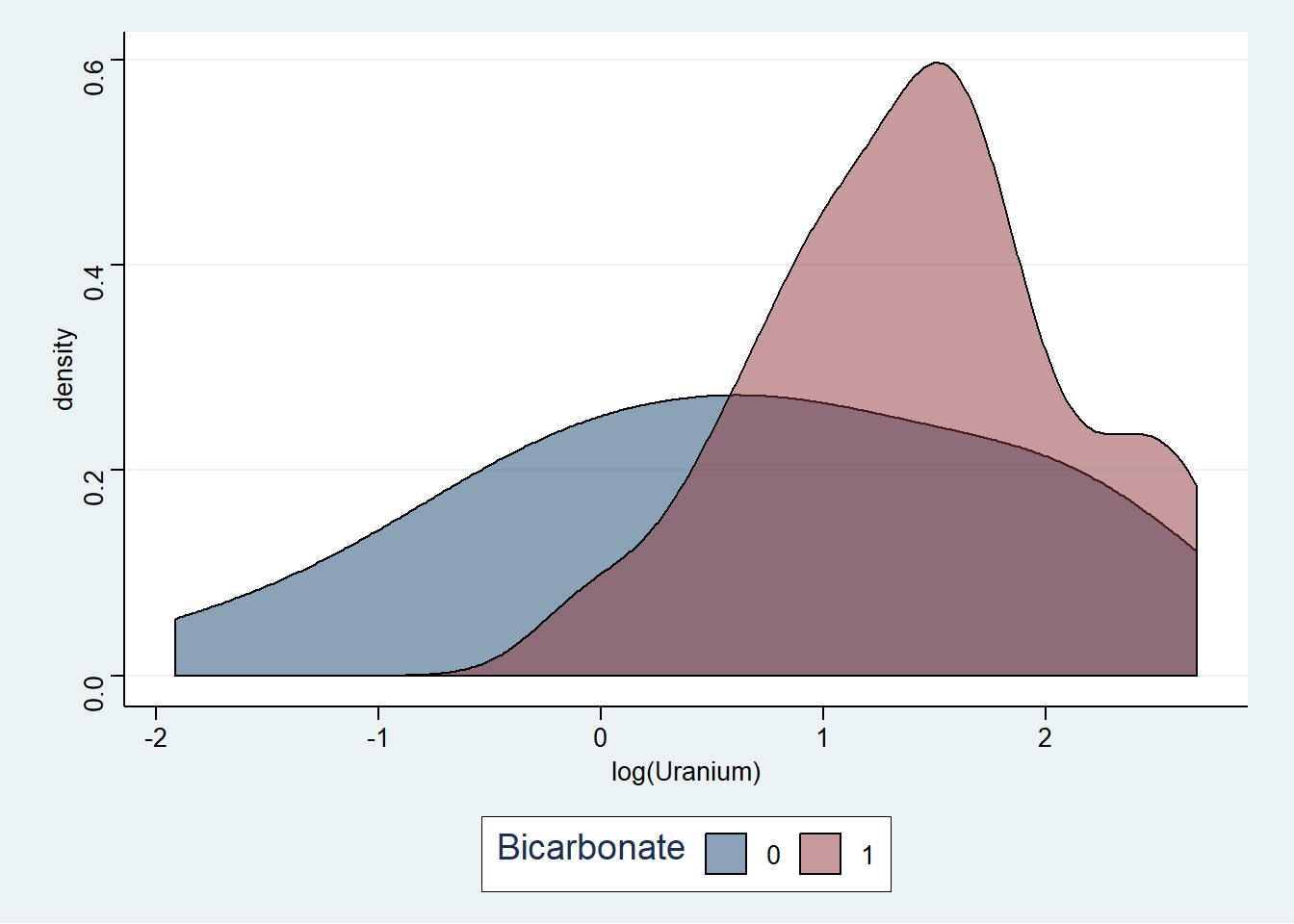
Figure 10: Visualisasi konsentrasi Uranium hasil tansformasi pada air tanah
Berdasarkan hasil transformasi, kita telah memperoleh ditribusi yang cukup simetris untuk kedua grup data tersebut. Pembaca dapat mencobanya menggunakan transformasi lainnya sendiri.
Referensi
- Damanhuri, E. 2011. Statitika Lingkunga. Penerbit ITB.
- Helsel, D.R., Hirsch, R.M. 2002. statistical Methods in Water Resources. USGS.
- Ofungwu, J. 2014. Statistical Applications For Environmental Analysis and Risk Assessment. John Wiley & Sons, Inc.
- Rosadi, D. 2015. Analisis Statistika dengan R. Gadjah Mada University Press.
- STHDA. Descriptive Statistics and Graphics. http://www.sthda.com/english/wiki/descriptive-statistics-and-graphics.