Daftar Isi
- Properti Umum dari Distribusi Probabilitas
- Distribusi Binomial dan Multinomial
- Distribusi Hipergeometris
- Distribusi Binomial Negatif dan Distribusi Geometris
- Distribusi Poisson
- Distribusi Uniform
- Distribusi Normal
- Distribusi Gamma dan Eksponensial
- Distribusi Chi-Square, Student’s t, dan Snedecor’s F
- Distribusi Kontinu Lainnya
Distribusi probabilitas merupakan sebuah fungsi yang menggambarkan kemungkinan memperoleh sejumlah nilai dalam suatu variabel acak. Dengan kata lain distribusi probabilitas menjelaskan bahwa nilai yang muncul pada sampel acak akan bervariasi berdasarkan distribusi probabilitas yang menyertainya.
Untuk memahaminya misalkan kita melakukan suatu sampling dengan cara survey terhadap sejumlah responden untuk mengetahui produksi sampah hariannya. Keseluruhan nilai timbulan yang diperoleh selajutnya disebut sebagai distribusi timbulan sampah. Distribusi tersebut berguna saat kita mengetahui hasil mana yang paling mungkin, sebaran nilai potensial serta kemungkinan hasil yang berbeda.
9.1 Properti Umum dari Distribusi Probabilitas
Distribusi probabilitas menjelaskan kemungkinan suatu peristiwa atau nilai muncul. Ahli statistika menjelaskan distribusi probabilitas kedalam Persamaan (1).
\[\begin{equation} P\left(x\right)=kemungkinan\ suatu\ variabel\ acak\ mengandung\ nilai\ x \tag{1} \end{equation}\]Jumlah seluruh probabilitas adalah 1. Selain itu retang nilai probabilitas berkisar antara 0 sampai 1, dimana hal ini telah penulis jelaskan pada Chapter sebelumnya.
Distribusi probabilitas menjelaskan sebaran nilai variabel acak. Akibatnya, jenis variabel menentukan jenis distribusi probabilitas. Untuk variabel acak tunggal, ahli statistik membagi distribusi menjadi dua jenis berikut:
- Distribusi probabilitas yang diskrit
Fungsi probabilitas diskrit dikenal sebagai fungsi massa probabilitas, dimana kita dapat mengasumsikan sejumlah nilai diskrit. Misalnya pelemparan dadu serta perhitungan sebuah peristiwa seperti flu di suatu daerah merupakan fungsi tersendiri. Kedua contoh tersebut merupakah contoh peristiwa diskrit karena tidak ada nilai antara, misalnya pada dadu tidak ada nilai antara 1 dan 2, dan seterunya. Pada perhitungan jumlah peristiwa flu juga tidak ada nilai antara orang terserang dlu dan tidak. Contoh lainnya adalah perhitungan jumlah buku diperpustakaan yang diperiksa tiap jam. Kita dapat menghitung jumlah buku perjam seperti 21 buku atau 22 buku, tetapi kita tidak dapat menghitung jumlah buku pada nilai antara kedua nilai tersebut. Distribusi probabilitas diskrit terdiri atas:
- Binomial
- Hypergeometric
- Poisson
- Geometric
- Multinomial
- Distribusi probabilitas yang bersifat kontinu
Fungsi probabilitas kontinu dikenal juga sebagai fungsi densitas probabilitas. Suatu distribusi dikatakan sebagai distribusi kontinu jika nilai yang terkandung dalam distribusi tersebut tidak terbatas serta skala yang digunakan dapat pula mengandung nilai desimal. Contoh suatu pengukuran yang menghasilkan distribusi kontinu adalah tinggi, berat, suhu, dll. Distribusi probabilitas kontinu terdiri atas:
- Normal
- Binomial
- Uniform
- Loh Normal
- Gamma, dll.
9.2 Distribusi Binomial dan Multinomial
Suatu percobaan sering dilakukan dengan proses yang berulang-ulang. Tiap proses percobaan yang dilakukan akan menghasilkan dua luaran yaitu sukses atau gagal. Untuk memahaminya misalkan pembaca melakukan pelemparan sebuah koin. Jika yang keluar adalah bagian kepala (head) maka proses tersebut dikatakan sukses, jika sebaliknya maka gagal. Proses penentuan sukses dan gagal tersebut tergantung pada sudut pandang kita melihatnya. Proses percobaan demikian disebut sebagai Bernoulli process (proses bernouli). Setiap percobaan yang dilakukan disebut sebagai Bernoulli trial.
Bernoulli process memiliki ciri-ciri sebagai berikut:
- Eksperimen terdiri atas sejumlah perulangan percobaan.
- Setiap perulangan percobaan menghasilkan luaran yang diklasifikasikan sebagai sukses atau gagal.
- Probabilitas sukses (dinotasikan \(p\)) konstan dari setiap perulangan.
- Setiap perulangan percobaan bersifat independen.
Untuk memahami Bernoulli process kita akan menggunakan contoh pelemparan dadu. Misalkan kita akan melakukan percobaan pelemparan dadu sebanyak 3 kali. Probabilitas munculnya bagian angka 1 pada dadu adalah \(\frac{1}{6}\). Probabilitas ini konstan pada setiap perulangan. Jika kita menginginkan ketiga perulangan tersebut menghasilkan angka 1. Probabilitasnya merupakan hasil kali probabilitas pada tiap giliran pelemparan seperti berikut:
\[ P\left(111\right)=\frac{1}{6}\cdot\frac{1}{6}\cdot\frac{1}{6}=\frac{1}{216} \]
9.2.1 Distribusi Binomial
Jumlah \(X\) keberhasilan atau jumlah percobaan sukses dalam percobaan Bernoulli disebut variabel acak binomial. Distribusi probabilitas dari variabel acak diskrit ini disebut distribusi binomial, dan nilainya akan dinotasikan dengan \(b\left(x;n,p\right)\) karena mereka bergantung pada jumlah percobaan dan probabilitas keberhasilan pada percobaan yang diberikan.
Bernouli trial dapat menghasilkan percobaan yang sukses dengan probabilitas \(p\) dan percobaan gagal dengan probabilitas \(q=1-p\). Sehingga distribusi probabilitas binomial percobaan sukses untuk variabel acak \(X\) dengan jumlah \(n\) percobaan yang independen dinyatakan kedalam Persamaan (2).
\[\begin{equation} b\left(x;n,p\right)=\left(nC_x\right)p^xq^{n-x},\ x=0,1,2,...,n. \tag{2} \end{equation}\]dimana
\[\begin{equation} nC_x=\frac{n!}{x!\left(n-x\right)!} \tag{3} \end{equation}\]Dengan menggunakan contoh sebelumnya kita dapat menghitung probabilitas keluarnya angka 1 pada dadu untuk 3 kali percobaan (\(n\)) atau seluruh percobaan menghasilkan angka 1 (\(n=x=3\)) adalah:
\[ b\left(3;3,\frac{1}{6}\right)=\left(\frac{3!}{3!\left(3-3\right)!}\right)\left(\frac{1}{6}\right)^3\left(\frac{5}{6}\right)^{\left(3-3\right)} \] \[ b\left(3;3,\frac{1}{6}\right)=\left(1\right)\cdot\left(\frac{1}{6}\right)^3\cdot\left(1\right)=\frac{1}{216} \]
Kita juga dapat melakukan perhitungan tersebut menggunakan R untuk mengetahui probabilitas munculnya angka 1 pada dadu untuk 3 kali percobaan. Sintak yang digunakan adalah sebagai berikut:
dbinom(x=3, # jumlah kejadian sukses
size=3, # jumlah percobaan
prob=1/6) # probabilitas kejadian## [1] 0.00462963Probabilitas Kumulatif Binomial
Pada kondisi lain kita tidak hanya tertarik dengan probabilitas munculnya suatu peristiwa. Kita terkadang tertarik untuk menghitung probabilitas kumulatif dari suatu peristiwa. Misalnya probabilitas munculnya nomor dadu \(<4\) atau pada perhitungan kendaraan per jam yang melalui suatu jalan kita tertarik menghitung peluang kendaraan yang melintas tiap jam \(<50\) kendaraan. Untuk menghitung probabilitas yang demikian kita perlu melakukan akumulasi probabilitas yang memenuhi kriteria yang telah kita tentukan sebelumnya. Probabilitas kumulatif distribusi binomial berdasarkan kondisi tertentu dinyatakan pada Persamaan (4).
\[\begin{equation} B\left(r,n,p\right)=\sum_{x=0}^rb\left(x;n,p\right) \tag{4} \end{equation}\]dimana \(r\) adalah kondisi probabilitas yang kita inginkan yang dapat dituliskan sebagai \(P\left(X<r\right)\) atau \(P\left(X>r\right)\). Kondisi lain yang dapat kita gunakan adalah \(P\left(a\le X\le b\right)\).
Untuk memahaminya kita akan membuat sebuah contoh kasus. Misalkan kita diminta untuk melakukan analisis kerusakan diffused aerator pada suatu instalasi air limbah. Jumlah aerator total pada instalasi tersebut adalah 10 buah. Probabilitas sebuah aerator rusak sebesar \(\frac{1}{10}\). Tentukan berapa probabilitas jika (a) setidaknya 3 aerator tersebut tidak rusak? (b) 4 sampai 5 buah aerator rusak? serta (c) sebanyak 5 aerator rusak?.
- jika setidaknya 3 aerator tidak rusak
\[ P\left(X\le 3\right)=\sum _{x=0}^3b\left(x;10,0.1\right) \]
\[ P\left(X\le3\right)=b\left(0;10,0.1\right)+b\left(1;10,0.1\right)+b\left(2;10,0.1\right)+b\left(3;10,0.1\right) \]
\[ P\left(X\le3\right)=0,987 \]
Kita juga dapat memperoleh nilai tersebut dengan melihat tabel statistika yang dapat pembaca lihat pada tautan berikut
- jika 4 sampai 5 aerator rusak
\[ P\left(4\le X\le5\right)=\sum_{x=4}^5b\left(x;10,0.1\right)=\sum_{x=0}^5b\left(x;10,0.1\right)-\sum_{x=0}^3\left(x;10,0.1\right) \]
\[ P\left(4\le X\le5\right)=1-0,987=0,013 \]
- jika tepat 5 aerator rusak
\[ P\left(X=5\right)=b\left(5;10,0.1\right)=\sum_{x=0}^5b\left(x;10,0.1\right)-\sum_{x=0}^4b\left(x;10,0.1\right) \]
\[ P\left(X=5\right)=1-0,998=0,002 \]
Untuk melakukan perhitungannya pada R kita dapat menggunakan fungsi pbinom(). Fungsi tersebut akan menghitung probabilitas bedasarkan nilai kondisi yang telah kita masukkan. Berikut adalah sintaks yang digunakan:
# a) jika setidaknya 3 aerator tidak rusak
pbinom(q=3,
size=10, # jumlah percobaan
prob=0.1) # probabilitas sukses## [1] 0.9872048# b) jika setidaknya 4 sampai 5 aerator rusak
pbinom(q=5,size=10,prob=0.1)-pbinom(q=3,size=10,prob=0.1) ## [1] 0.0126483# c) jika tepat 5 aerator rusak
dbinom(x=5, # jumlah kejadian sukses
size=10, # jumlah percobaan
prob=0.1) # probabilitas sukses## [1] 0.001488035Menghitung Nilai Rata-Rata dan Varians Distribusi Binomial
Kita sudah mengetahui bahwa distribusi probabilitas binomial hanya bergantung pada nilai \(n\), \(p\), dan \(q\). Berdasarkan tersebut nilai mean, dan varians dari distribusi probabilitasnya juga bergantung pada ketiga nilai tersebut. Nilai mean dituliskan pada Persamaan (5), sedangkan varians dari distribusi probababilitas distuliskan pada Persamaan (6).
\[\begin{equation} \mu=np \tag{5} \end{equation}\] \[\begin{equation} \sigma^2=npq \tag{6} \end{equation}\]9.2.1 Multinomial Eksperimen dan Distribusi Multinomial
Eksperimen Binomial (Binomial process) dapat menjadi eksperimen multinomial jika kita menginginkan luaran dari percobaan yang dilakukan memiliki lebih dari satu hasil. Contoh dari eksperimen multinomial ini misalnya adalah penarikan kartu dari seperangkan kartu. Kita dapat mengaggap penarikan kartu dengan pengembalian sebagai eksperimen multinomial jika luaran yang diinginkan adalah 4 jenis kartu dalam set kartu tersebut.
Secara umum, jika percobaan yang diberikan dapat menghasilkan salah satu \(k\) dari hasil yang mungkin \(E_1,E_2,...,E_k\) dengan probabilitas yang dihasilkan sebesar \(p_1,p_2,...,p_k\), maka distribusi multinomial akan memberikan nilai probabilitas yang dinyatakan \(E_1\) terjadi sebanyak \(x_1\) kali, \(E_2\) terjadi sebanyak \(x_2\) kali, sampai dengan \(E_k\) terjadi sebanyak \(x_k\) kali dalam \(n\) percobaan yang independent, dimana
\[ x_1+x_2+...+x_k=n \]
Selanjutnya fungsi probabilitas dituliskan sebagai berikut:
\[ f\left(x_1,x_2,...,x_k;\ p_1,p_2,...,p_k\right) \]
Seperti yang telah kita ketahui bersama bahwa nilai \(p_1+p_2+...+p_k=1\). Sejak percobaan yang dilakukan independen, maka setiap percobaan yang menghasilkan \(x_1\) yang merupakan luaran dari \(E_1\), \(x_2\) yang merupakan luaran dari \(E_2\) sampai dengan \(x_k\) yang merupakan luaran dari \(E_k\) akan terjadi dengan probabilitas \(p^{x_1}p^{x_2}...p^{x_k}\). Jumlah urutan yang menghasilkan hasil yang serupa untuk percobaan \(n\) adalah sama dengan jumlah partisi \(n\) item ke dalam \(k\) grup dengan \(x_1\) di grup pertama, \(x_2\) di grup kedua, sampai dengan \(x_k\) di grup \(k\). Kondisi ini dapat dituliskan seperti berikut:
\[ \binom{n}{x_1,x_2,...,x_k}=\frac{n!}{x_1!x_2!...x_k!} \]
Sejak seluruh partisi bersifat mutually exlusive dan terjadi dengan probabilitas yang setara, kita dapat memperoleh distribusi multinomial dengan mengalikan probabilitas tiap luaran spesifik dengan jumlah total partisinya. Persamaan distribusi multinomial yang diperoleh dituliskan kedalam Persamaan (7).
\[\begin{equation} f\left(x_1,x_2,...,x_k;\ p_1,p_2,...,p_k\right)=\binom{n}{x_1,x_2,...,x_k}p^{x_1}p^{x_2}...p^{x_k} \tag{7} \end{equation}\]dimana
\[\begin{equation} \sum_{i=1}^kx_i=n\ dan\ \sum_{i=1}^kp_i=1 \tag{8} \end{equation}\]Untuk memahami penerapan distribusi multinomial, penulis akan memberikan sebuah studi kasus. Probabilitas sejenis pompa memiliki umur ekonomis 2 tahun sebesar 0,30, antara 2-4 tahun adalah 0,50, dan 4-5 tahun adalah 0,20. Hitunglah probabilitas 8 buah pompa dimana pompa dengan umur ekonomis 2 tahun sebanyak 2 buah, 2-4 tahun sebanyak 5 buah, dan antara 4-5 sebanyak 1 buah.
Untuk menyelesaikannya kita perlu mendata jumlah kemunculan disertai dengan probabilitas kejadia pada tiap grup seperti berikut:
\[ n=8;\ x_1=2\ dengan\ p_1=0,30;\ x_2=5\ dengan\ p_2=0,50,\ dan\ x_3=1\ dengan\ p_1=0,20\ \]
dengan menggunakan Persamaan (7), maka probabilitasnya dapat dihitung seperti berikut:
\[ f\left(2,5,1;0.30,0.50,0.20\right)=\binom{8}{2,5,1}\left(0,3\right)^2\left(0,5\right)^5\left(0,2\right)^1 \]
\[ f\left(2,5,1;0.30,0.50,0.20\right)=0,0945 \]
Pada R kita dapat menggunakan fungsi dmultinom() untuk menghitung probabilitas distribusi multinomial. Komponen dari fungsi tersebut adalah sebagai berikut:
dmultinom(x, size, prob)Note:
- x: vektor numerik
- size: jumlah percobaan atau perulangan
- prob: vektor numerik probabilitas tiap grup hasil.
Berikut adalah sintaks untuk menghitung probabilitas multinomial pada contoh kasus di atas:
dmultinom(c(2,5,1), # jumlah kejadian tiap grup
size=8, # jumlah percobaan
prob=c(0.3,0.5,0.2)) # probabilitas masing-masing luaran## [1] 0.09459.3 Distribusi Hipergeometris
Distribusi hipergeometris didasarkan pada eksperimen hipergeometris yang memiliki asumsi sebagai berikut:
- Sampel dengan ukuran \(n\) diambil secara acak tanpa pengembalian (sampel without replacement) dari populasi berukuran \(N\).
- Pada populasi, \(k\) didefinisikan sebagai observasi yang sukses, sedangkan \(N-k\) didefiniskan sebagai observasi yang gagal.
Melalui asusmsi tersebut, kita dapat menemukan perbedaan antara distribusi hipergeometris dengan distribusi binomial. Perbedaan yang paling mendasar adalah metode sampling yang digunakan, dimana distribusi binomial mengasumsikan sampel dengan pengembalian (sample with replacement), sedangkan distribusi hipergeometris mengasumsikan sebaliknya.
Distribusi probabilitas hipergeometris untuk variabel acak \(X\) dengan jumlah sampel \(n\) dari populasi terpilih dengan ukuran populasi \(N\), dimana \(k\) merupakan observasi sukses dan \(N-k\) merupakan observasi yang gagal dapat dituliskan berdasarkan Persamaan (9).
\[\begin{equation} h\left(x;N,n,k\right)=\frac{\binom{k}{x}\binom{N-k}{n-x}}{\binom{N}{n}},\ \max\left\{0,n-\left(N-k\right)\right\}\le x\le\min\left\{n,k\right\} \tag{9} \end{equation}\]Range dari \(x\) dapat ditentukan dari 3 koefisien binomial, dimana \(x\) dan \(n-x\) tidak lagi lebih besar dari \(k\) dan \(N-k\) dan nilai keduanya tidak boleh lebih kecil dari 0. Biasanya ketika kedua nilai \(k\) dan \(N-k\) lebih besar dari ukuran sampel \(n\), range dari variabel acak hipergeometris akan menjadi \(x=0,1,...,n\).
Untuk memahami penerapan distribusi hipergeometris, kita dapat menerapkannya dalam sebuah contoh kasus. Misalkan pembaca ditugaskan untuk melakukan sortir terhadap 40 sak kompos yang akan dijual dengan berat rata-rata 2 kg. Pembaca diberi tahu bahwa 3 dari seluruh kompos tersebut memiliki berat kurang dari 2 kg sehingga tidak dapat dijual. Tugas pembaca adalah menemukan ketiga sak kompos tersebut. Untuk mempermudah proses tersebut pembaca melakukan sampling secara acak dengan jumlah sampling 5 buah kompos tanpa pengembalian. Hitunglah berapa peluang pada tiap sampling tersebut pembaca menemukan 1 kompos yang memiliki berat lebih kecil dari 2 kg tersebut?.
Berdasarkan studi kasus tersebut kita dapat menyimpulkan bahwa proses sampling yang dilakukan adalah dengan menggunakan prosedur sampling tanpa pengembalian, sehingga distribusi hipergeometris dapat diterapkan dengan nilai \(n=5\), \(N=40\), \(k=3\), dan \(x=1\). Dengan menggunakan Persamaan (9), peluang ditemukan 1 sak kompos yang tidak sesuai adalah sebagai berikut:
\[ h\left(1;40,5,3\right)=\frac{\binom{3}{1}\binom{40-3}{5-1}}{\binom{40}{5}}=0,3011 \]
Berdasarkan hasil perhitungan diketahui bahwa peluang untuk menemukan 1 sak kompos dari 3 sak kompos yang tidak sesuai sebesar 30% pada tiap kali sampling.
Pada R distribusi probabilitas hipergeometris dapat dihitung menggunakan fungsi dhyper(). Format yang digunakan pada fungsi tersebut adalah sebagai berikut:
dhyper(x, m, n, k)Note:
- x: vektor numerik yang menyatakan observasi sukses pada tiap sampling
- m: jumlah observasi sukses
- n: jumlah observasi gagal
- k: ukuran sampel
Berikut adalah sintaks untuk menghitung probabilitas hipergeometris contoh kasus di atas:
dhyper(x=1, # observasi sukses tiap sampling
m=3, # observasi sukses (k)
n=37, # observasi gagal (N-k)
k=5) # sampel## [1] 0.3011134Probabilitas Kumulatif Hipergeometris
Pada contoh kasus sebelumnya, sak kompos yang tidak memenuhi kriteria bisa saja saat sampling tidak hanya ditemukan 1 sak yang tidak memenuhi, bisa dua , tiga atau sama sekali tidak ada yang ditemukan sak yang tidak memenuhi kriteria. Kondisi tersebut mengharuskan kita menghitung probabilitas kumulatif dari suatu kondisi seperti \(P\left(X<r\right),\ P\left(X>r\right),\ atau\ P\left(a<X<b\right)\) yang dapat dituliskan pada Persamaan (10).
\[\begin{equation} H\left(r;N,n,k\right)=\sum_{x=0}^rh\left(x;N,n,k\right) \tag{10} \end{equation}\]Pada contoh sebelumnya, hitunglah probabilitas jika paling banyak 2 sak kompos yang tidak memenuhi kriteria ditemukan pada sampel?.
Untuk melakukannya kita perlu menghitung probabilitas hipergeometris untuk kondisi saat \(x=0,1,2\). Dengan menggunakan Persamaan (10), nilai probabilitas yang dihasilkan adalah sebagai berikut:
\[ P\left(X\le2\right)=b\left(0;40,5,3\right)+b\left(1;40,5,3\right)+b\left(2;40,5,3\right)=0,999 \]
Pada R probabilitas kumulatif dapat dihitung menggunakan fungsi phyper(). Format fungsi yang digunakan adalah sebagai berikut:
phyper(q, m, n, k, lower.tail=TRUE)Note:
- q: vektor numerik yang menyatakan observasi maksimum yang sukses saat sampling
- m: jumlah observasi sukses
- n: jumlah observasi gagal
- k: ukuran sampel
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE
Dengan menggunakan sintaks tersebut, probabilitas kumulatif dapat dihitung sebagai berikut:
phyper(q=2, # probabilitas <=2
m=3, # observasi sukses
n=37, # jumlah gagal
k=5) # jumlah sampel## [1] 0.9989879# atau
dhyper(0,3,37,5)+dhyper(1,3,37,5)+dhyper(2,3,37,5)## [1] 0.9989879Menghitung Nilai Rata-Rata dan Varians Distribusi Hipergeometris
Nilai rata-rata dan varians distribusi hipergeometris dituliskan kedalam Persamaan (11):
\[\begin{equation} \mu=\frac{nk}{N}\ dan\ \sigma^2=\frac{N-n}{N-1}\cdot n\cdot\frac{k}{N}\left(1-\frac{k}{N}\right) \tag{11} \end{equation}\]Bila nilai \(n<<<N\), maka pendekatan distribusi binomial dapat dilakukan dengan pendekatan \(n\) dan \(p=\frac{k}{N}\). Pendekatan yang dilakukan akan cukup baik bila \(n\le0,1N\).
9.4 Distribusi Binomial Negatif dan Distribusi Geometris
Mari kita bayangkan percobaan di mana sifat-sifatnya (propertinya) sama dengan percobaan binomial, dengan pengecualian bahwa uji coba akan diulangi sampai sejumlah keberhasilan terjadi. Oleh karena itu, alih-alih probabilitas \(x\) keberhasilan dalam \(n\) percobaan, di mana \(n\) tetap, kita sekarang tertarik pada probabilitas bahwa keberhasilan \(k\) terjadi pada percobaan ke-\(x\). Eksperimen semacam ini disebut eksperimen binomial negatif.
Sifat-sifat dari percobaan binomial negatif adalah sebagai berikut:
- Percobaan terdiri atas sejumlah \(x\) perulangan.
- Setiap percobaan memiliki dua hasil (sukses dan gagal).
- Probabilitas sukses dinotasikan dengan \(p\) yang sama pada setiap percobaan.
- Setiap percobaan bersifat independen yang berarti hasil dari sebuah percobaan tidak akan mempengaruhi hasil percobaan lainnya.
- Percobaan dilakukan secara terus-menerus sampai dengan sejumlah \(k\) sukses terjadi, dimana \(k\) ditentukan terlebih dahulu.
Untuk memahaminya misalkan kita menguji sebuah obat dengan memberikannya kepada pasien yang sakit. Keberhasilan obat tersebut Obat dinyatakan sukses jika secara efektif memberikan efek pemulihan bagi pasien. Probabilitas obat tersebut melakukannya berdasarkan hasil studi yang telah dilakukan sebesar 60%. Kita tertarik untuk mengetahui probabilitas pasien kelima yang mengalami efek penyembuhan dimana pasien ini merupakan pasien ketujuh yang diberikan obat tersebut. Untuk melakukannya kita definisikan kejadian sukses dengan simbol \(S\) dan gagal dengan simbol \(F\), urutan yang mungkin dari ketujuh pasien berdasarkan respon terhadap obat adalah \(SFSSSFS\) yang probabilitas kejadian berdasarkan urutan tersebut adalah sebagai berikut:
\[ \left(0,6\right)\left(0,4\right)\left(0,6\right)\left(0,6\right)\left(0,6\right)\left(0,4\right)\left(0,6\right)=\left(0,6\right)^5\left(0,4\right)^2 \]
Kita dapat mendaftar sejumlah luaran yang mungkin pada kejadian tersebut mengatur ulang \(F\) dan \(S\) kecuali untuk hasil terakhir, yang harus menjadi keberhasilan kelima. Jumlah total luaran yang mungkin sama dengan jumlah partisi dari enam (7-1) percobaan pertama menjadi dua kelompok dengan 2 buah gagal dan 4 buah sukses menjadi kelompok tersendiri. Hal ini dapat dilakukan berdasarkan \(\binom{6}{4}=15\) cara yang mutually exclusive. Oleh karena itu, jika \(X\) mewakili hasil dimana keberhasilan kelima terjadi, maka
\[ P\left(X=7\right)=\binom{6}{4}\left(0.6\right)^2\left(0,4\right)^2=0,1866 \]
9.4.1 Distribusi Binomial Negatif
Berdasarkan contoh kasus tersebut, kita dapat mendefinisikan formula untuk distribusi probabilitas binomial negatif. Jika percobaan yang bersifat independen dan berulang dapat menghasilkan keberhasilan (kejadian sukses) dengan probabilitas \(p\) dan kegagalan dengan probabilitas \(q=1-p\), maka distribusi probabilitas variabel acak \(X\), jumlah percobaan di mana keberhasilan k terjadi dinyatakan pada Persamaan (12):
\[\begin{equation} b^{\ast}\left(x;k,p\right)=\binom{x-1}{k-1}p^kq^{x-k},\ \ \ \ \ x=k,k+1,k+2,.... \tag{12} \end{equation}\]Untuk lebih memahami penerapan dari distribusi binomial negatif. Misalkan pada suatu evan NBA (Championship series) atau final antar juara wilayah, dimana pada pertandingan puncak kedua tim dari dua wilayah akan melakukan 7 pertandingan terkahir. Suatu tim dinyatakan juara jika berhasil meraih 4 kemenangan dari 7 pertandingan yang ada. Anggaplah tim A dan B berhadapan satu sama lain. Probabilitas A memenangkan suatu pertandingan terhadap tim B sebesar 0,55, tentukan:
- Berapakah probabilitas tim A memenangkan kejuaraan pada pertandingan ke-6 dari 7 pertandingan yang ada?
- Berapakah probabilitas A memenangkan kejuaraan?
Dengan menggunakan Persamaan (12), probabilitas kemenangan tim A terhadap tim B dapat dihitung sebagai berikut:
- Tim A juara pada pertandingan ke-6 (\(x=6\), \(k=4\), dan \(p=0,55\))
\[ b^{\ast}\left(6;4,0.55\right)=\binom{6-1}{4-1}0,55^4\left(1-0,55\right)^{6-4}=0,1853 \]
- Tim A menjuarai kejuaraan
Tim A dapat menjuarai kejuaraan jika telah memenangkan 4 dari 7 pertandingan. Kemungkinan Tim A dapat memenangkan pertandingan tersebut dapat terjadi pada pertandingan ke-4 (menang berturut-turut), pertandingan ke-6, dan pertandingan ke-7.
\[ b^{\ast}\left(4;4,0.55\right)+b^{\ast}\left(5;4,0.55\right)+b^{\ast}\left(6;4,0.55\right)+b^{\ast}\left(7;4,0.55\right) \]
\[ 0,0915+0,1647+0,1853+0,1668=0,6083 \]
Pada R kita dapat menghitung probabilitas binomial negatif menggunakan fungsi dnbinom(). Format fungsi tersebut adalah sebagai berikut:
dnbinom(x, size, prob)Note:
- x: jumlah observasi gagal
- size: jumlah observasi sukses
- prob: probabilitas kejadian sukses
Dengan menggunakan fungsi dnbinom(), probabilitas Tim A menang pada pertandingan ke-6 dapat dihitung sebagai berikut:
dnbinom(x=2, # jumlah observasi gagal
size=4, # jumlah observasi sukses
prob=0.55) # probabilitas sukses## [1] 0.1853002Pada pertanyaan kedua soal dapat kita impulkan bahwa kita hendak mencari probabilitas kumulatif kemenangan Tim A. Untuk melakukannya kita dapat menggunakan fungsi pnbinom(). Format fungsi tersebut adalah sebagai berikut:
pnbinom(q, size, prob, lower.tail = TRUE)Note:
- q: jumlah observasi gagal minimum
- size: jumlah observasi sukses maksimum
- prob: probabilitas sukses
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE
Dengan menggunakan fungsi tersebut, probabilitas kumulatif kemenangan Tim A adalah sebagai berikut:
pnbinom(q=3, # jumlah observasi gagal min
size=4, # jumlah observasi sukses maks
prob=0.55) # probabilitas sukses## [1] 0.6082878# atau
dnbinom(x=0,size=4,prob=0.55)+
dnbinom(x=1,size=4,prob=0.55)+
dnbinom(x=2,size=4,prob=0.55)+
dnbinom(x=3,size=4,prob=0.55)## [1] 0.60828789.4.2 Distribusi Geometris
Pada kenyataannya kita hanya tertarik terhadap probabilitas kejadian sukses pertama kali akan terjadi. Probabilitas kejadian tersebut merupakan kejadian pada distribusi probabilitas geometris. Distribusi ini merupakan kasus khusus distribusi binomial negatif.
Jika suatu suatu percobaan independen dapat menghasilkan kejadian sukses dengan probabilitas \(p\) dan gagal dengan probabilitas \(q=1-p\), maka distribusi probabilitas variabel acak \(X\), jumlah percobaan dimana sukses pertama terjadi didefinisikan pada Persamaan (13):
\[\begin{equation} g\left(x;p\right)=pq^{x-1},\ \ \ \ \ x=1,2,3,... \tag{13} \end{equation}\]Agar pembaca lebih memahaminya, misalkan suatu pabrik memiliki probabilitas 1 dari 100 barang produksinya merupakan produk cacat. Pemeriksaan dilakukan pada setiap barang tersebut. Tentukan probabilitas barang ke-5 hasil pengecekan merupakan barang yang cacat?
Dengan menggunakan Persamaan (13) probabilitas barang ke-5 merupakan produk gagal sebagai berikut:
\[ g\left(5;0.01\right)=\left(0,01\right)\left(0,99\right)^{5-1}=0,0096 \]
Pada R probabilitas tersebut dapat dihitung menggunakan fungsi dgeom(). Format fungsi tersebut adalah sebagai berikut:
dgeom(x, prob)Note:
- x: vektor numerik observasi dimana kejadian sukses terjadi pertama kali
- prob: probabilitas kejadian sukses
Dengan menggunakan fungsi tersebut, probabilitas geometris dapat dihitung seperti berikut:
dgeom(x=5, # observasi kejadian sukses pertama terjadi
prob=0.01) # probabilitas kejadian sukses## [1] 0.0095099Terkadang kita tertarik untuk mempelajari probabilitas kejadian sukses pertama kali berdasarkan suatu rentang observasi atau dapat didefinisikan \(P\left(X<r\right),\ P\left(X>r\right),\ atau\ P\left(a<X<b\right)\) yang dapat dituliskan pada Persamaan (14).
\[\begin{equation} G\left(r;p\right)=\sum _{x=0}^rg\left(x,p\right) \tag{14} \end{equation}\]Berdasarkan contoh sebelumnya hitunglah probabilitas barang cacat pertama kali ditemukan pada observasi kurang dari sama dengan observasi ke-5?
\[ P\left(P\le5\right)=g\left(0;0.01\right)+g\left(1;0.01\right)+...+g\left(5;0.01\right)=0.0585 \]
Pada R fungsi yang digunakan untuk menghitung probabilitas kumulatif distribusi probabilitas geometris adalah pgeom(). Format yang digunakan adalah sebagai berikut:
pgeom(q, prob, lower.tail = TRUE)Note:
- q: batas observasi minimum terjadi
- prob: probabilitas sukses
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE
Berdasarkan hal tersebut, maka probabilitas dapat dihitung seperti berikut:
pgeom(5,0.01)## [1] 0.05851985# atau
dgeom(0,0.01)+
dgeom(1,0.01)+
dgeom(2,0.01)+
dgeom(3,0.01)+
dgeom(4,0.01)+
dgeom(5,0.01)## [1] 0.05851985Nilai rata-rata dan varians distribusi probabilitas geometris disajikan pada Persamaan (15).
\[\begin{equation} \mu=\frac{1}{p}\ dan\ \sigma^2=\frac{1-p}{p^2} \tag{15} \end{equation}\]9.5 Distribusi Poisson
Distribusi probabilitas Poisson menggambarkan berapa kali suatu peristiwa terjadi pada sebuah interval yang spesifik. Interval dapat berupa waktu, jarak, area, atau volume.
Distribusi Poisson didasarkan pada dua asumsi. Asumsi pertama menjelaskan bahwa probabilitas proporsional terhadap panjang interval. Asumsi yang kedua adalah interval bersifat independen. Dengan kata lain semakin panjang suatu interval, semakin besar probabilitas, dan jumlah kejadian pada sebuah interval tidak mempengaruhi interval lainnya. Distribusi ini juga merupakan bentuk terbatas dari distribusi binomial dimana probabilitas keberhasilan sangat kecil dengan ukuran sampel \(n\) besar.
Probabilitas Poisson memiliki karakteristik sebagai berikut:
- variabel acak merupakan berapa kali suatu peristiwa terjadi selama interval yang ditentukan. 2.probabilitas suatu peristiwa proporsional terhadap ukuran interval.
- interval tidak tumpang tindih dan bersifat independen
Distribusi probabilitas Poisson pada variabel acak \(X\), merepresentasikan jumlah luaran yang terjadi pada interval waktu yang diberikan atau wilayah yang spesifik dan dinotasikan sebagai \(t\). Distribusi probabilitas dituliskan pada Persamaan (16):
\[\begin{equation} p\left(x;\lambda t\right)=\frac{e^{-\lambda t}\left(\lambda t\right)^x}{x!},\ \ \ \ \ \ x=0,1,2,.... \tag{16} \end{equation}\]dimana \(\lambda\) merupakan rata-rata jumlah luaran per satuan waktu, jarak, area, atau volume dan \(e=2,71828...\)
Kumulatif probabilitas Poisson dituliskan berdasarkan Persamaan (17):
\[\begin{equation} P\left(r;\lambda t\right)=\sum_{x=0}^rp\left(x;\lambda t\right) \tag{17} \end{equation}\]dengan nilai rata-rata dan varians distribusinya disajikan pada Persamaan (18).
\[\begin{equation} \mu\ dan\ \sigma=\lambda t \tag{18} \end{equation}\]Untuk lebih memahami penerapan kedua persamaan tersebut, misalkan selama melakukan eksperimen laboratorium, rata-rata jumlah partikel radioaktif yang melewati couter pada 1 milidetik sebesar 4. Berapa probabilitas 6 partikel memasuki counter pada milidetik yang diberikan?
Contoh kasus tersebut dapat diselesaikan menggunakan Persamaan (16) dengan nilai \(x=4\) dan \(\lambda t=4\) seperti berikut:
\[ p\left(6;4\right)=\frac{e^{-4}\left(4\right)^6}{6!}=0,1042 \]
Kita dapat menggunakan fungsi dpois() pada R untuk menghitung probabilitas Poisson. Format yag digunakan adalah sebagai berikut:
dpois(x, lambda)Note:
- x: vektor numerik
- lamda: jumlah rata-rata luaran
Probabilitas 6 partikel memasuki counter berdasarkan fungsi tersebut adalah sebagai berikut:
dpois(x=6, lambda=4)## [1] 0.1041956Contoh kasus tersebut juga dapat diselesaikan menggunakan Persamaan (17) dengan terlebih dahulu menghitung selisih \(P(X\le6)\) terhadap \(P(X\le5)\). Pada R fungsi yang digunakan adalah ppois(). Format fungsi tersebut adalah sebagai berikut:
ppois(q, lambda, lower.tail = TRUE)Note:
- q: vektor numerik
- lambda: jumlah rata-rata luaran
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE
Dengan menggunakan fungsi tersebut, hasil yang diperoleh adalah sebagai berikut:
ppois(6,4)-ppois(5,4)## [1] 0.10419569.6 Distribusi Uniform
Distribusi uniform merupakan distribusi kontinu yang paling sederhana yang ditandai dengan fungsi densitas yang datar serta probabilitas yang seragam sepanjang interval tertutup. Distribusi ini juga disebut sebagai distribusi persegi panjang sebab bentuk distribusinya yang menyerupai persegi panjang. Fungsi densitas untuk distribusi uniform disajikan pada Persamaan (19).
\[\begin{equation} f(x;A,B) = \begin{cases} \frac{1}{B-A} & \quad A\le x\le B\\ 0 & \quad\text{} \end{cases} \tag{19} \end{equation}\]Nilai mean dan varians dari distribusi uniform disajikan pada Persamaan (20).
\[\begin{equation} \mu=\frac{A+B}{2}\ dan\ \sigma^2=\frac{\left(B-A\right)^2}{12} \tag{20} \end{equation}\]Untuk memudahkan pemahaman pembaca mengenai distribusi ini, berikut penulis sajikan visualisasi distribusi uniform dengan nilai minimum=1 dan maksimum=3. Variabel acak dibuat menggunakan fungsi runif(). Format fungsi yang digunakan adalah sebagai berikut:
runif(n, min = 0, max = 1)Note:
- n: jumlah data atau panjang variabel acak
- min: nilai minimum variabel acak
- max: nilai maksimum variabel acak
Visualisasi disajikan pada Gambar 1.
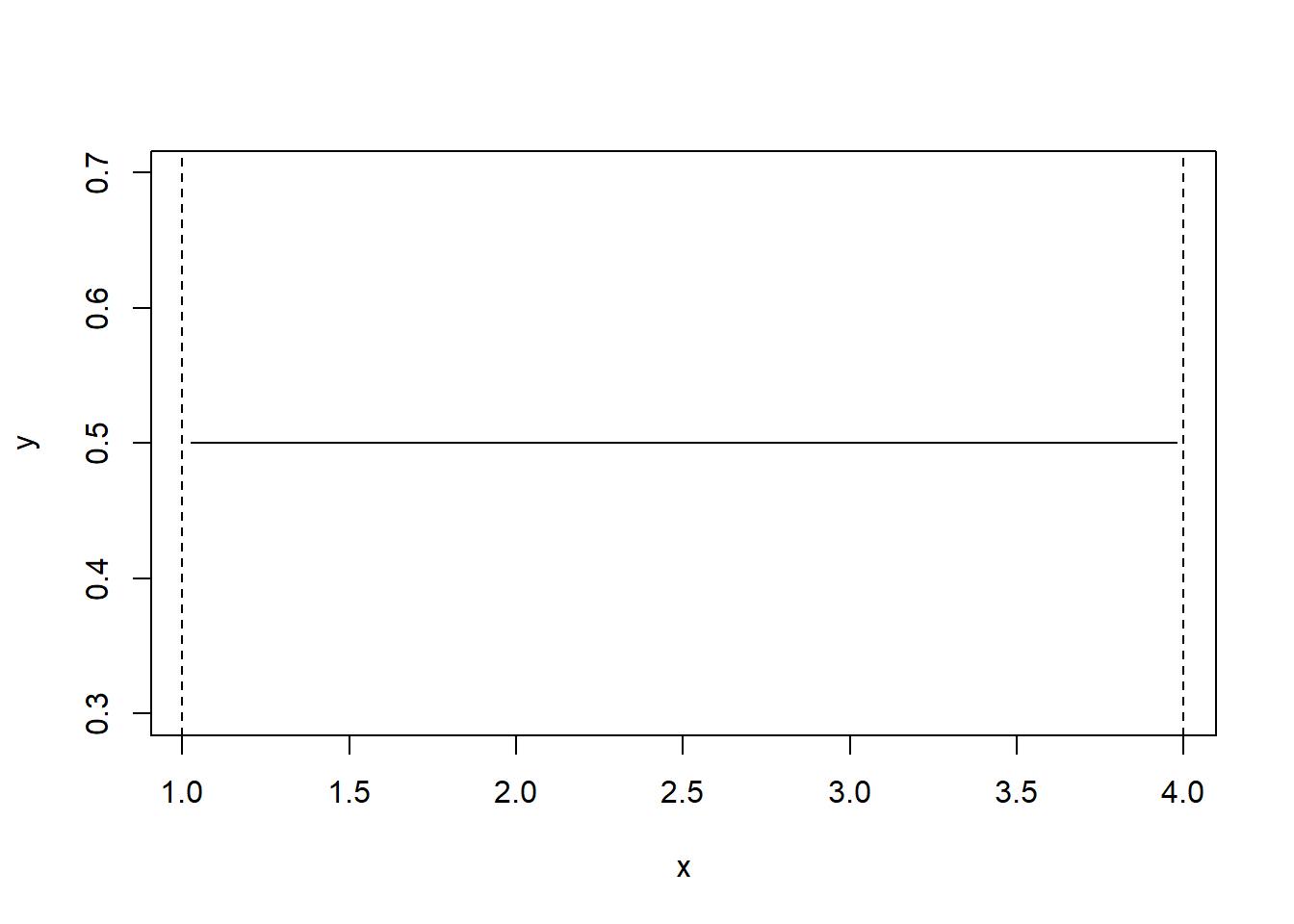
Figure 1: Distribusi uniform dengan nilai min 1 dan max 3
Berdasarkan Gambar 1, probabilitas distribusinya adalah sebagai berikut:
\[ f(x;A,B) = \begin{cases} \frac{1}{3} & \quad 0\le x\le 4\\ 0 & \quad\text{} \end{cases} \]
Kita juga dapat menghitung probabilitas suatu nilai melalui distribusi tersebut. Sebagai contoh, hitunglah probabilitas nilai \(X\ge3\)?
\[ P\left[X\ge3\right]=\int_3^4dx=\frac{1}{4} \]
Jika contoh tersebut divisualisasikan, maka akan tampak seperti pada Gambar 2.
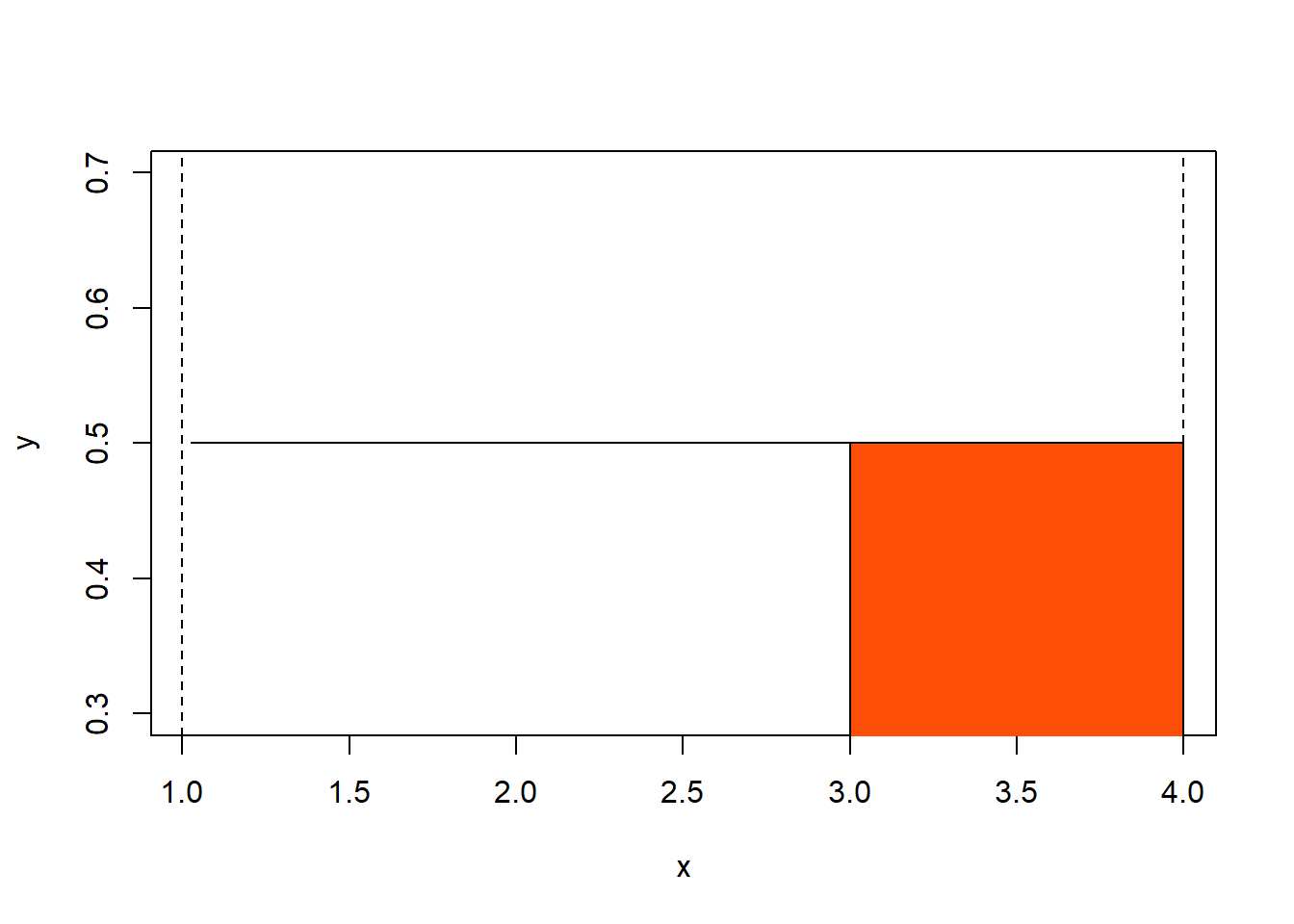
Figure 2: Probabilitas distribusi uniform pada rentang nilai x 3 sampai 4
Pada R terdapat 2 buah fungsi untuk menghitung probabilitas distribusi unifofm. Fungsi pertama adalah dunif() dan yang kedua adalah punif(). Fungsi pertama akan menghasilkan probabilitas (likelihood) dari suatu nilai yang kita inginkan, sedangkan fungsi kedua adalah fungsi probabilitas kumulatif yang akan menghasilkan nilai berdasarkan rentang yang dimasukkan (rentang satu arah bisa \(\le\) atau \(\ge\)).
Format fungsi dunif() adalah sebagai berikut:
dunif(x, min = 0, max = 1)Note:
- n: jumlah data atau panjang variabel acak
- min: nilai minimum variabel acak
- max: nilai maksimum variabel acak
Format fungsi punif adalah sebagai berikut:
punif(q, min = 0, max = 1, lower.tail = TRUE)Note:
- q: vektor numerik
- min: nilai minimum variabel acak
- max: nilai maksimum variabel acak
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
Nilai probabilitas berdasarkan contoh soal sebelumnya merupakan contoh kasus probabilitas kumulatif sehingga digunakan fungsi punif() untuk menghitung probabilitasnya.
punif(3, min=1, max=4, lower.tail=FALSE)## [1] 0.33333339.7 Distribusi Normal
Distribusi kontinu yang paling sering digunakan dalam analisa statistik adalah distribusi normal atau disebut juga sebagai distribusi Gauss. Distribusi ini dicirikan dari bentuknya yang mirip dengan lonceng. Secara umum fungsi densitas distribusi normal disajikan pada Persamaan (21).
\[\begin{equation} n\left(x;\mu,\sigma\right)=\frac{1}{\sqrt{2\pi\sigma}}e^{-\frac{1}{2\sigma^2}\left(x-\mu\right)^2},\ \ \ \ \ \ -\infty<x<\infty \tag{21} \end{equation}\]dimana \(\pi=3,14159...\) dan \(e=2,71828...\).
Berdasarkan persamaan di atas terdapat dua parameter penting dalam distribusi normal yaitu nilai mean \(\mu\) dan simpangan baku \(\sigma\). Kedua nilai tersebut akan mempengaruhi bentuk dari distribusi normal yang terbentuk. Pada contoh selanjutnya akan diberikan visualisasi mengenai bentuk distribusi normal dengan berbagai variasi mean dan simpangan baku.
- Distribusi normal dengan \(\mu\) berbeda dan \(\sigma\) yang sama.
Pada Gambar 3 disajikan visualisasi dua buah distribusi normal dengan nilai \(\mu\) sama dan \(\sigma\) berbeda.
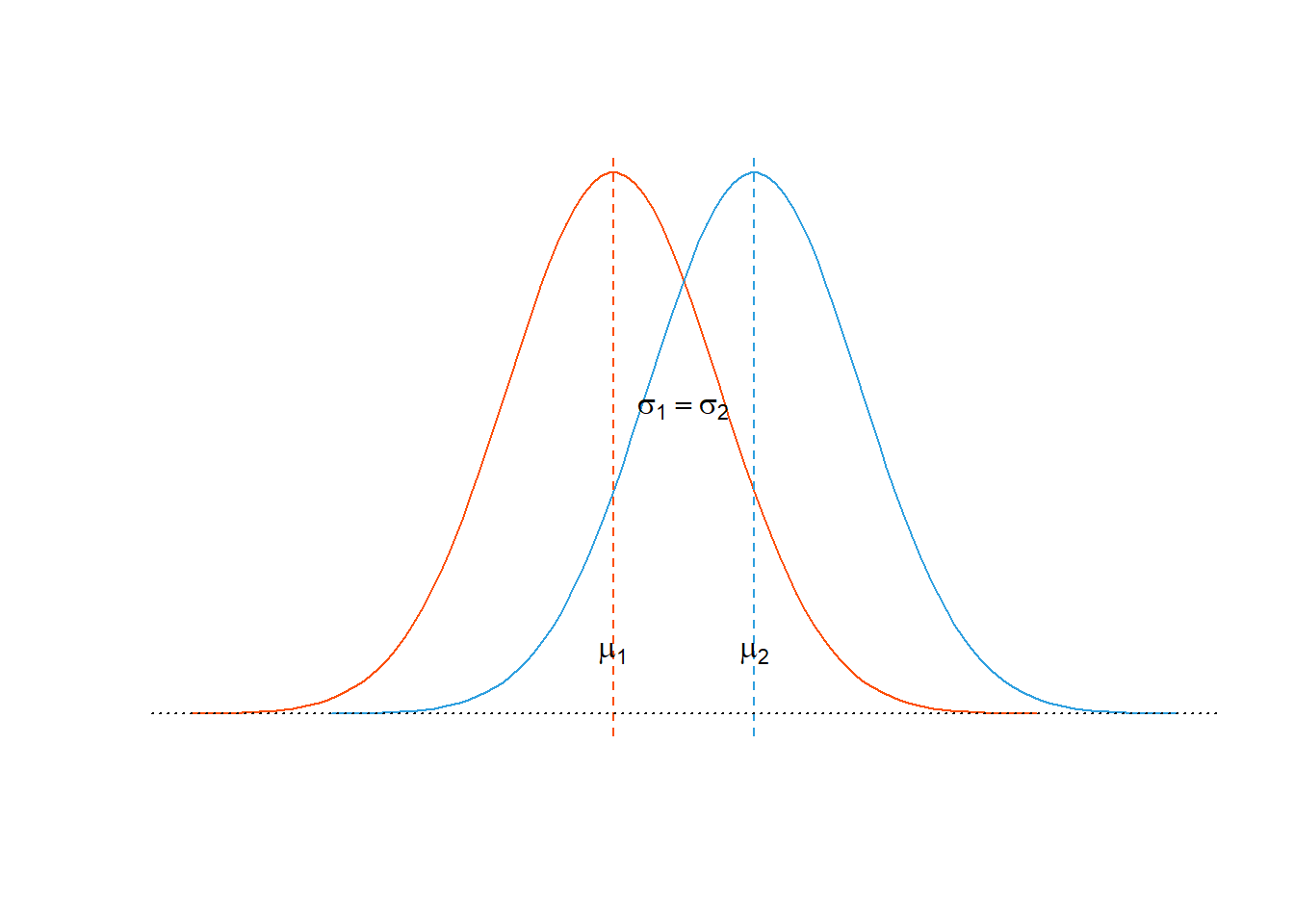
Figure 3: Distribusi normal dengan nilai mean sama dan simpangan baku berbeda.
- Distribusi normal dengan \(\mu\) sama dan \(\sigma\) yang berbeda.
Pada Gambar 4 disajikan visualisasi dua buah distribusi normal dengan nilai \(\mu\) berbeda dan \(\sigma\) sama. Perbedaan \(\sigma\) menyebabkan bentuk distribusi yang lebih datar. \(\sigma\) kecil membuat bentuk distribusi yang lebih lancip (sebaran data kecil), sedangkan \(\sigma\) akan berlaku sebaliknya.
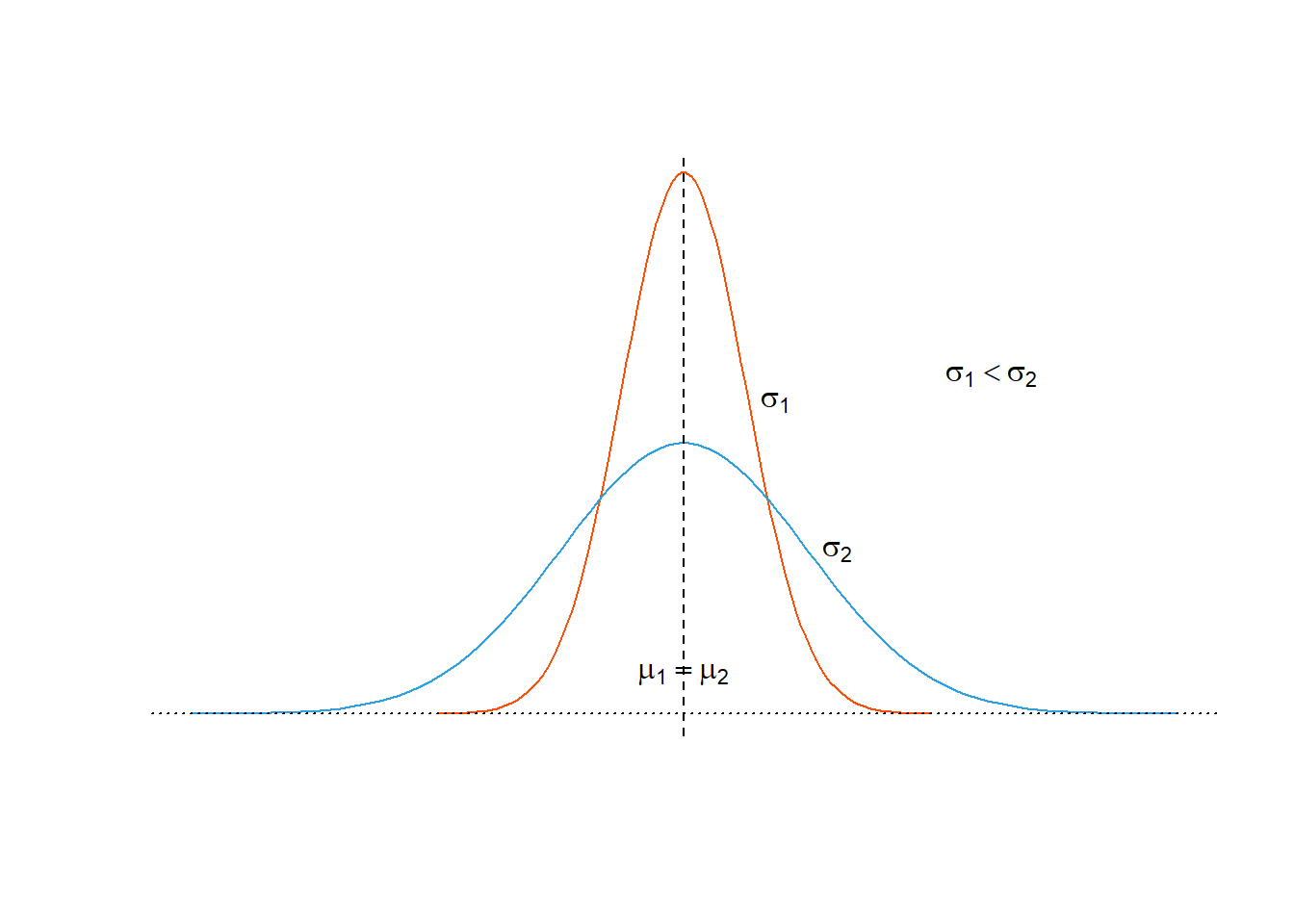
Figure 4: Distribusi normal dengan nilai mean sama dan simpangan baku berbeda.
- Distribusi normal dengan \(\mu\) berbeda dan \(\sigma\) yang berbeda.
Pada Gambar 5 disajikan visualisasi dua buah distribusi normal dengan nilai \(\mu\) berbeda dan \(\sigma\) yang berbeda pula. Perbedaan tersebut menyebabkan perbedaan letak distribsui normal serta bentuk distribusinya.
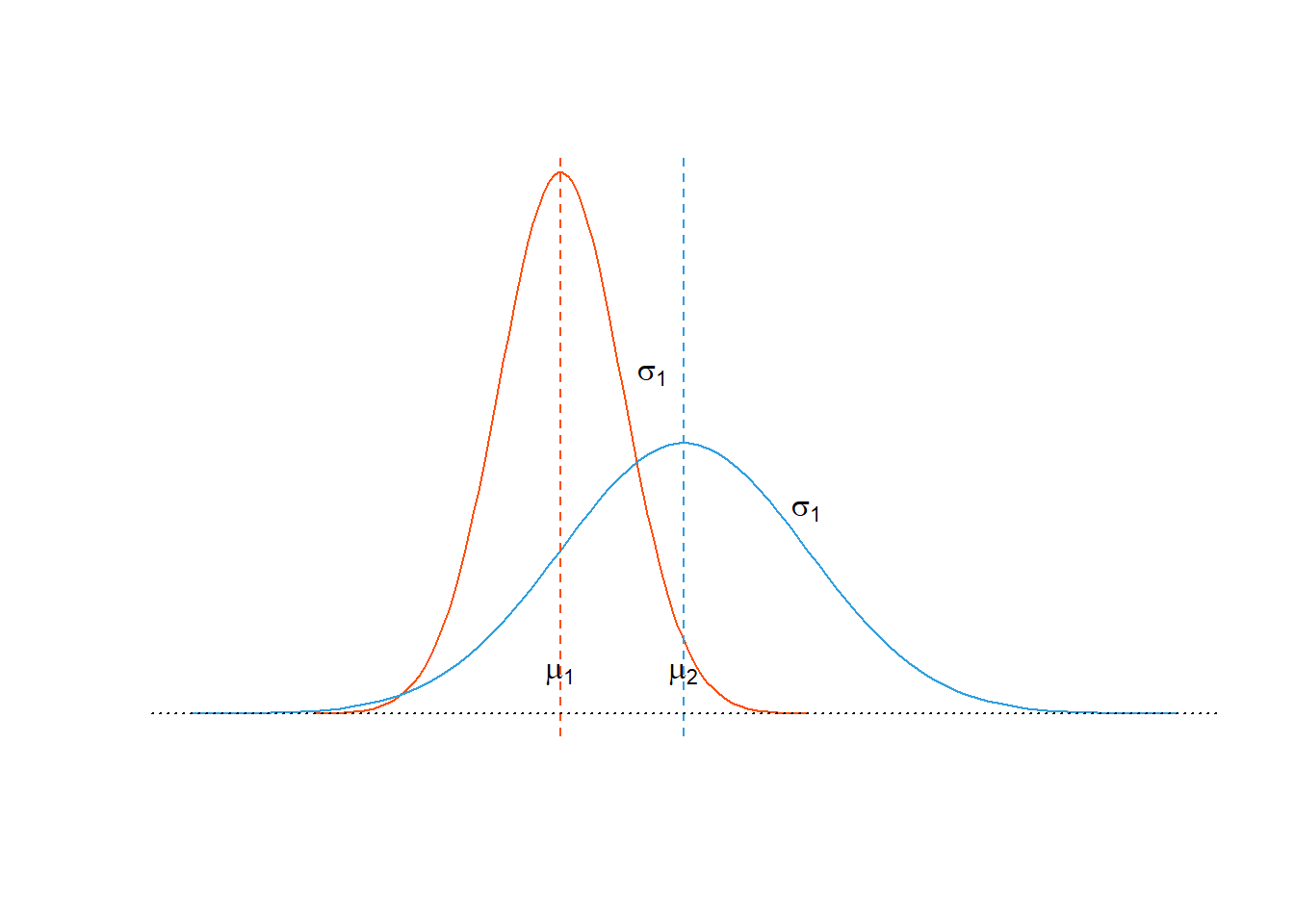
Figure 5: Distribusi normal dengan nilai mean berbeda dan simpangan baku berbeda.
Berdasarkan visualisasi di atas, sifat-sifat dasar distribusi normal adalah sebagai berikut:
- Modus distribusi normal berada pada titik horizontal dimana kurva berada pada posisi maksimum atau \(x=\mu\).
- Kurva berbentuk simestris terhadap nilai mean \(\mu\).
- Kurva memiliki titik infleksi pada \(x=\mu \pm \sigma\), yang cekung kebawah jika \(\mu-\sigma<X<\mu+\sigma\) dan cekung ke atas pada titik diluar rentang tersebut.
- Kurva normal mendekati sumbu horizontal asimtotik saat kita melanjutkan ke arah mana pun dari rata-rata.
- Luas total di bawah kurva dan di atas sumbu horizontal adalah 1.
Sifat lain yang dimiliki oleh distribusi normal adalah sebagai berikut:
- Sekitar 68% luas dibawah kurva normal berada pada kisaran 1 \(\sigma\) dari nilai \(\mu\).
- Sekitar 95% luas dibawah kurva normal berada pada kisaran 2 \(\sigma\) dari nilai \(\mu\).
- Sekitar 99,7% luas dibawah kurva normal berada pada kisaran 3 \(\sigma\) dari nilai \(\mu\).
Secara kolektif, titik-titik ini dikenal sebagai aturan empiris atau aturan 68-95-99,7. Hal ini jelas, mengingat distribusi normal sebagian besar hasil akan berada dalam 3 \(\sigma\) dari \(\mu\).
9.7.1 Luas Area Di Bawah Kurva Normal
Untuk memperoleh luas area dibawah distribusi normal kita perlu membuat batasan pada kurva tersebut. Dua koordinat pembatas dapat kita definisikan sebagai \(x_1\) dan \(x_2\). Luas area yang diarsir (lihat Gambar 6) selanjutnya dihitung dengan cara mengintegralkan area yang diarsir dengan batasan dua koordinat sebelumnya atau dapat ditulis sebagai berikut:
\[ P\left(x_1<X<x_2\right)=\int_{x_1}^{x_2}n\left(x;\mu,\sigma\right)dx=\frac{1}{\sqrt{2\pi\sigma}}\int_{x_1}^{x_2}e^{-\frac{1}{2\sigma^2}\left(x-\mu\right)^2}dx \]
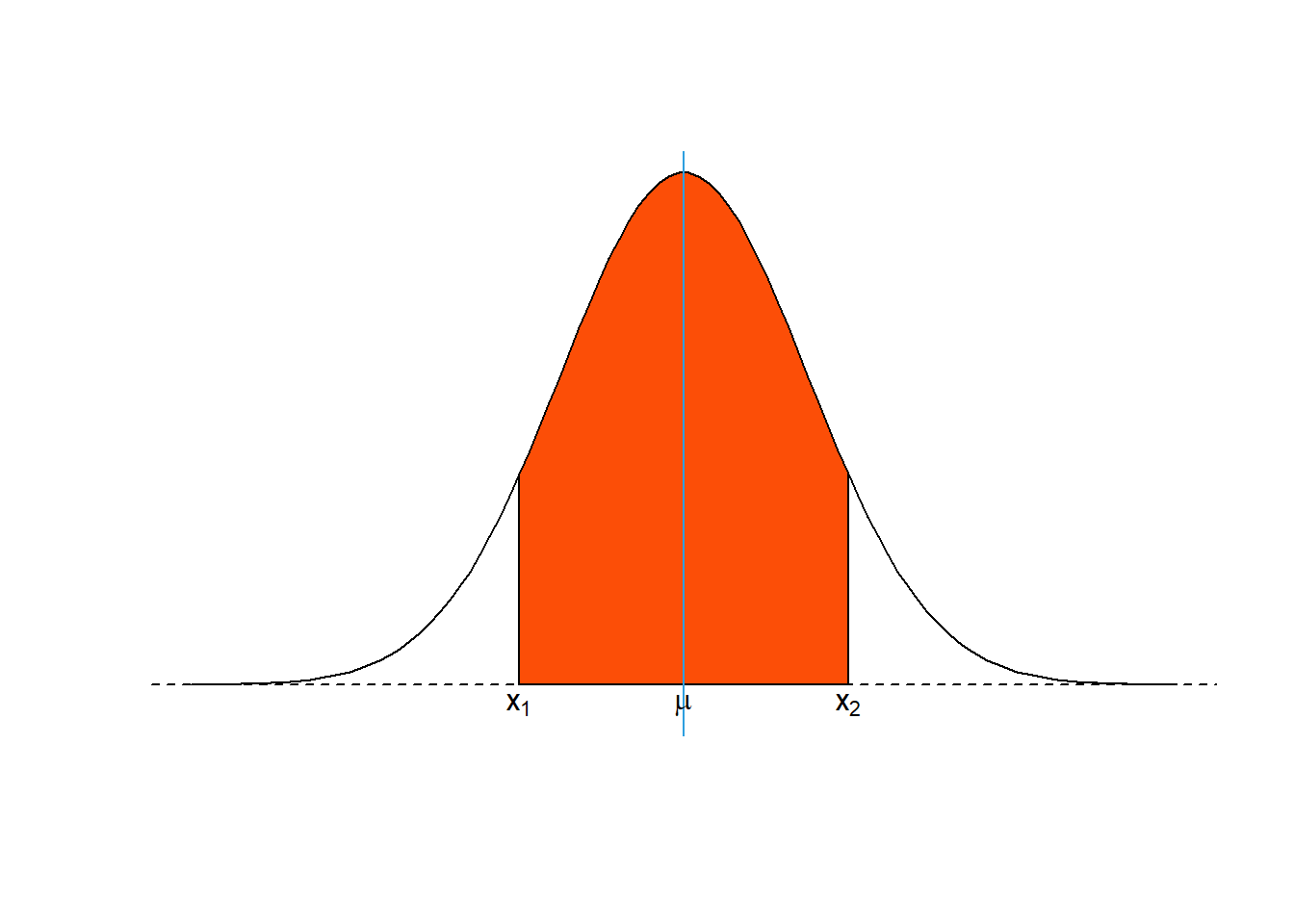
Figure 6: Luas area di bawah kurva normal.
Menghitung luas area di bawah kurva normal bukanlah pekerjaan yang mudah dilakukan sehingga terkadang kita memerlukan alat bantu untuk melakukan proses perhitungan. Alat bantu yang umum digunakan adalah Tabel distribusi normal standard (distribusi normal dengan \(\mu\) 0 dan \(\sigma^2\) 1) yang dapat pembaca unduh pada tautan berikut. Untuk dapat menggunakan Tabel tersebut kita perlu mengubah nilai \(x_1\) dan \(x_2\) pada Gambar 6 menjadi \(Z\). Untuk melakukannya kita dapat menggunakan Persamaan (22).
\[\begin{equation} Z=\frac{X-\mu}{\sigma} \tag{22} \end{equation}\]Jika kita lihat berdasarkan Gambar 6, luas area yang diblok dapat dihitung dengan Tabel distribusi normal. Luas area yang dicari dihitung sebagai berikut:
\[ P\left(x_1<z\le x_2\right)=P\left(z< x_2\right)+P\left(z> x_1\right) \]
Agar pembaca lebih memahami penerapan distribusi ini, misalkan kita diminta untuk menghitung probabilitas masa layan lampu. Rerata masa layan lampu suatu produk adalah 750 jam dengan simpangan baku 80 jam. Distribusi dari masa layan lampu tersebut diasumsikan mengikuti distribusi normal. Hitunglah probabilitas:
- Lampu memiliki masa layan antara 750 sampai 830 jam?
- Lampu dengan masa layan tepat 830 jam?
- Lampu dengan masa layan lebih dari atau sama dengan 830 jam
Masa layan lampu antara 750 sampai 830 jam
Distribusi dan luasan yang dicari dapat digambarkan berdasarkan Gambar 7 berikut:
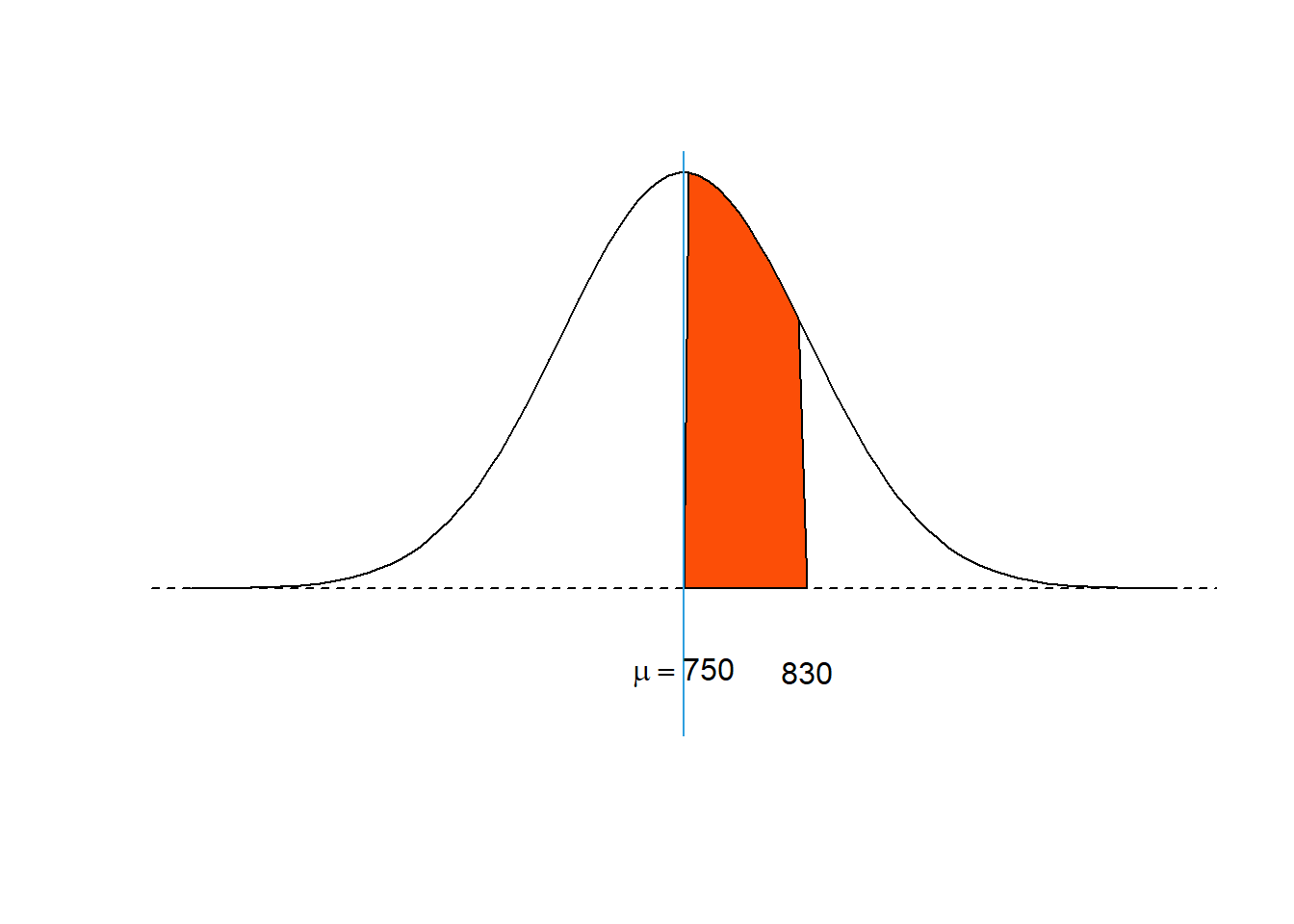
Figure 7: Luas area masa layan lampu antara 750 sampai 830 jam.
Nilai rentang perlu dikonversi kedalam nilai distribusi normal standard menggunakan Persamaan (22). Berikut adalah proses perhitungannya:
\[ Z_{750}=\frac{750-750}{80}=0\ \ \ dan\ \ \ Z_{830}=\frac{830-750}{80}=1 \]
Dengan menggunakan Tabel distribusi normal, probabilitas yang diinginkan dapat dihitung sehingga diperoleh nilai probabilitas sebagai berikut:
\[ P\left(z<1\right)=0,3413 \]
Masa layan lampu tepat 830 jam
Pertanyaan dapat dijawab menggunakan Persamaan (21). Hasil yang diperoleh adalah sebagai berikut:
\[ n\left(750;750,80\right)=\frac{1}{\sqrt{2\pi\left(80\right)}}e^{-\frac{1}{2\left(80\right)^2}\left(\left(750\right)-\left(750\right)\right)^2}=0.003 \]
Masa layan lampu lebih dari atau sama dengan 830 jam
Distribusi dan luasan yang dicari dapat digambarkan berdasarkan Gambar 8 berikut:
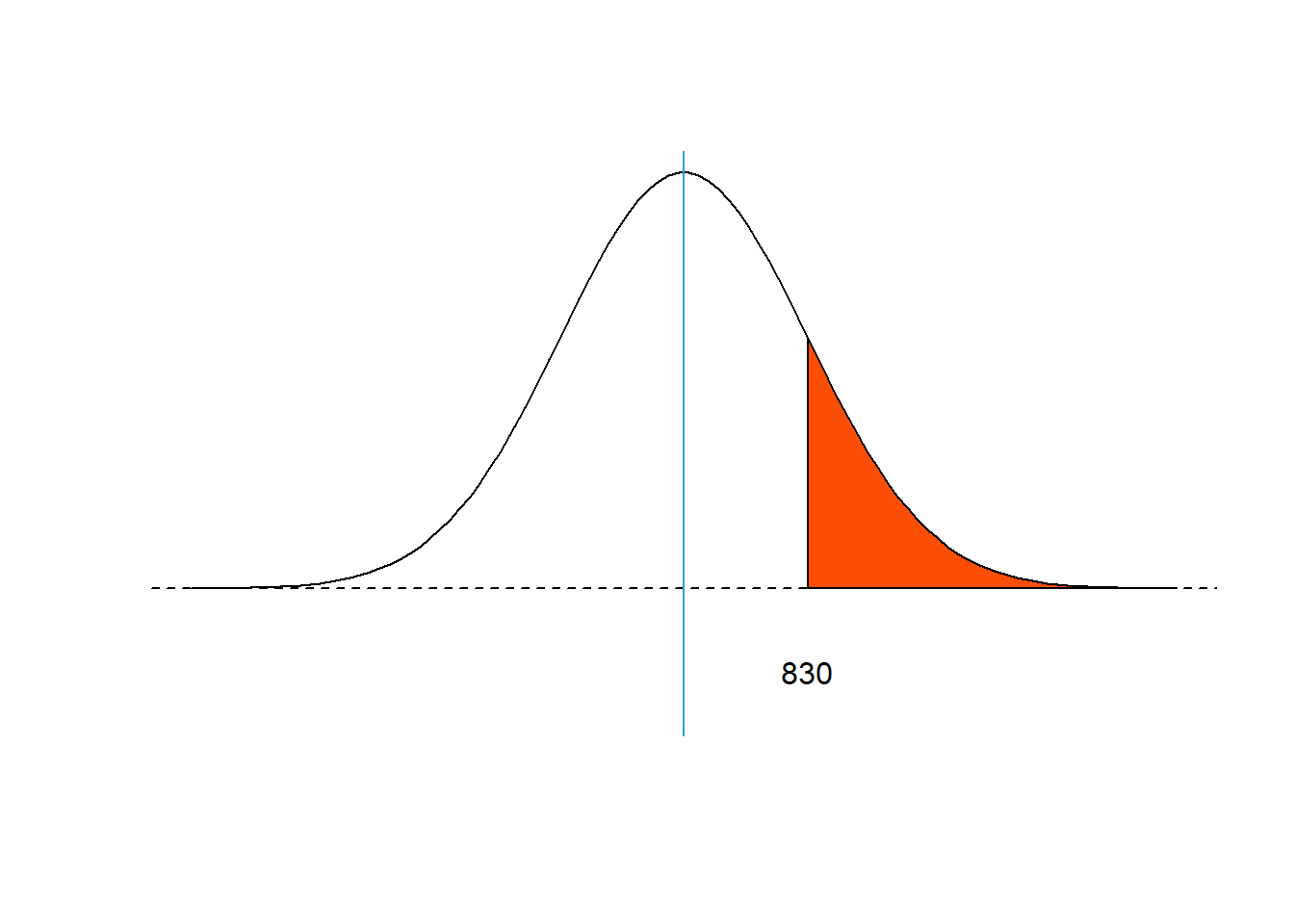
Figure 8: Luas area masa layan lampu lebih dari atau sama dengan 830 jam.
Probabilitas berdasarkan luas area tersebut dapat dihitung seperti berikut:
\[ P\left(z>1\right)=0,5-0,3413=0,1578 \]
Pada R probabilitas distribusi normal dapat dihitung menggunakan dua buah fungsi yaitu dnorm() (probabilitas distribusi normal) dan pnorm() (probabilitas kumulatif distribusi normal). Format yang digunakan adalah sebagai berikut:
dnorm(x, mean = 0, sd = 1)
pnorm(q, mean = 0, sd = 1, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil
- mean: rata-rata populasi
- sd: simpangan baku populasi
Berikut adalah contoh penyelesaian contoh soal masa layan lampu menggunakan sintaks R:
# masa layan 750 sampai 830 jam
pnorm(q=830, mean=750, sd=80)-pnorm(q=750, mean=750, sd=80)## [1] 0.3413447# masa layan 830 jam
dnorm(x=830, mean=750, sd=80)## [1] 0.003024634# masa layan lebih dari sama dengan 830 jam
pnorm(q=830, mean=750, sd=80, lower.tail=FALSE)## [1] 0.15865539.7.2 Uji Kecocokan Distribusi Normal
Uji kecocokan distribusi data apakah distribusi tersebut berdistribusi normal dapat dilakukan dengan dua cara yaitu: analisis grafik dan analisis numerik. Analisis grafik dilakukan dengan menggunakan grafik yaitu histogram, density plot, QQ-plot dan ECDF. Dalam Chapter sebelumnya telah penulis jelaskan bahwa ECDF dapat digunakan untuk menguji kecocokan distribusi secara umum. Metode lain yang dapat digunakan adalah metode numerik menggunakan metode Shapiro-Wilk (SW), Shapiro-Francia (SF), dll. Dalam buku ini penulis hanya akan menjelaskan uji kecocokan distribusi normal menggunakan metode Shaphiro-Wilk.
Kita adakn menggunakan dataset airquality yang merupakan data pengukuran kualitas udara New York bulan Mei sampai September 1973. Pertama-tama kita perlu melihat ringkasan data dari dataset tersebut. Berikut adalah sintaks untuk melakukannya:
library(tibble)glimpse(airquality)## Observations: 153
## Variables: 6
## $ Ozone <int> 41, 36, 12, 18, NA, 28, 23, 19, 8, NA, 7, 16, 11, 14, ...
## $ Solar.R <int> 190, 118, 149, 313, NA, NA, 299, 99, 19, 194, NA, 256,...
## $ Wind <dbl> 7.4, 8.0, 12.6, 11.5, 14.3, 14.9, 8.6, 13.8, 20.1, 8.6...
## $ Temp <int> 67, 72, 74, 62, 56, 66, 65, 59, 61, 69, 74, 69, 66, 68...
## $ Month <int> 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, ...
## $ Day <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,...Kita akan mengecek distribusi dari konsentrasi ozon apakah berdistribusi normal atau tidak, kita dapat memvisualisasikannya menggunakan grafik dalam contoh ini adalah grafik QQ-plot dan ECDF. Berikut adalah visualisasi yang dihasilkan
# install.packages("ggpubr")
library(ggplot2)
library(dplyr)
library(ggpubr)## set tema default dari paket ggpubr
theme_set(theme_pubr())
## QQ-plot
qq<-ggplot(airquality, aes(sample=Ozone))+
stat_qq(color="#2E9FDF")+
stat_qq_line(color="#FC4E07")
## membuat data frame
x <- sort(airquality[!is.na(airquality$Ozone), 1])
y <- rnorm(length(x),mean=mean(x),sd=sd(x))
data <- data.frame(x=c(x,y),
dist=gl(2,length(x),
labels=c("Empiris","Normal")))
## ECDF
ecdf<-ggplot(data, aes(x, colour=dist))+
stat_ecdf()+
labs(y="F(Ozon)", x="Ozon")+
scale_color_manual(values=c("#2E9FDF", "#FC4E07"))+
scale_x_continuous(breaks=seq(round(min(y)),round(max(x)),35))+
geom_rug()
## density
dens<-ggplot(data, aes(x, fill=dist))+
geom_density(alpha=0.5)+
labs(x="Ozon")+
scale_fill_manual(values=c("#2E9FDF", "#FC4E07"))+
scale_x_continuous(breaks=seq(round(min(y)),round(max(x)),35))+
geom_rug()
## Boxplot
data2 <- subset(data, dist=="Empiris")
bxp <- ggplot(data2, aes(x="", y=x))+
geom_boxplot(color="#FC4E07",outlier.alpha=0)+
geom_jitter(color="#2E9FDF",shape=1,position=position_jitter(0.1))+
labs(y="Ozon", x="")+
scale_y_continuous(breaks=seq(round(min(y)),round(max(x)),35))+
coord_flip()+
geom_rug()
## Menggabungkan grafik
ggarrange(dens,bxp,ecdf,qq,
ncol=2, nrow=2,
labels=c("a)","b)","c)","d)"))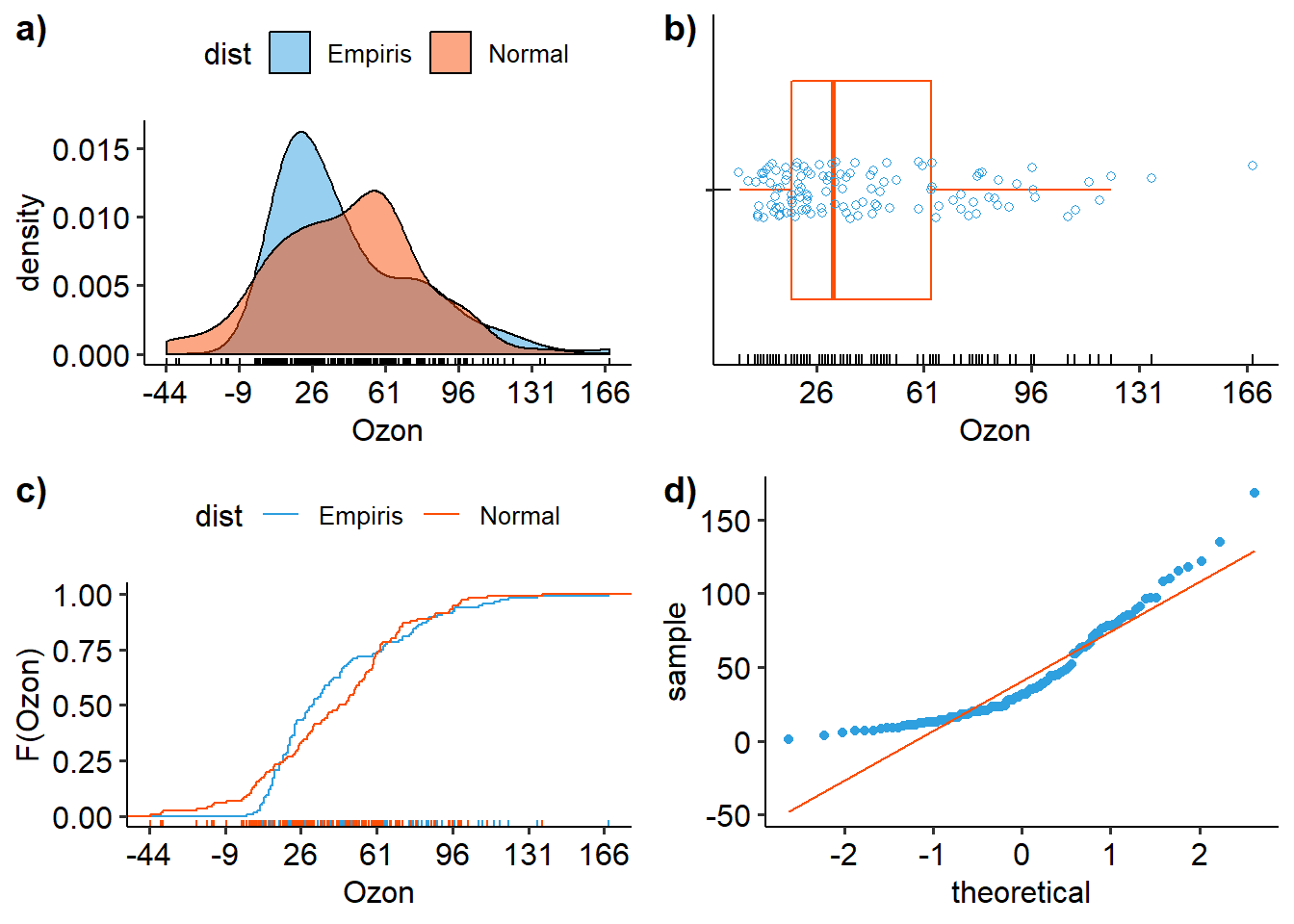
Figure 9: Visualisasi distribusi konsentrasi ozon Kota New York a)density plot, b)boxplot, c)ecdf, d)qq-plot
Berdasarkan kedua grafik tersebut terlihat bahwa titik observasi tidak mengikuti garis referensi distribusi normal sehingga dapat disimpulkan bahwa distribusi konsentrasi ozon tidak berdistribusi normal.
Metode lain yang digunakan untuk melakukan uji kecocokan terhadap distribusi normal adalah dengan menggunakan metode Shapiro-Wilk (SW). Metode ini merupakan metode nonparametrik yang memiliki power yang cukup besar untuk ukuran sampel relatif kecil (\(<2000\)). Perintah yang digunakan pada R untuk melakukan uji SW adalah shapiro.test(). Format yang digunakan adalah sebagai berikut:
shapiro.test(x)Note:
x: vektor numerik.
Pengujian ini merupakan suatu bentuk pengujian statistik sehingga melibatkan dua buah hipotesis. Pengujian statistik tidak akan dijelaskan secara detail pada Chapter ini. Hipotesis yang digunakan adalah sebagai berikut
\(H_0\): Sampel berdistribusi normal
\(H_1\): Sampel data tidak berdistribusi normal
Berikut adalah uji kecocokan yang dilakukan pada R:
shapiro.test(airquality$Ozone)##
## Shapiro-Wilk normality test
##
## data: airquality$Ozone
## W = 0.87867, p-value = 2.79e-08Berdasarkan hasil perhitungan diperoleh nilai p-value sebesar 2.79e-08. Dengan menggunakan tingkat kepercayaan 95% (error=5%), dapat disimpulkan bahwa distribusi ozon tidak berdistribusi normal (p-value<error).
9.7.3 Pendekatan Distribusi Binomial Menggunakan Distribusi Normal
Nilai probabilitas distribusi diskrit seperti distribusi binomial dapat dihitung dengan menggunakan pendekatan distribusi binomial. Pendekatan ini berlaku jika jumlah sampel yang digunakan sangat besar. Dengan menggunakan pendekatan ini, kita dapat menghitung probabilitas kumulatif distribusi binomial menggunakan Tabel distribusi normal.
Jika \(X\) merupakan variabel acak binomial dengan mean \(\mu=np\) dan varians \(\sigma^2=npq\), maka bentuk batas distribusi \(z\) dengan pendekatan distribusi normal standard dituliskan kedalam Persamaan (23).
\[\begin{equation} Z=\frac{X-np}{\sqrt{npq}} \tag{23} \end{equation}\]dimana \(n\to\infty\) merupakan distribusi normal standard \(n\left(z;0,1\right)\). Nilai \(z\) yang diperoleh selanjutnya dapat digunakan untuk mencari luasan dibawah kurva normal menggunakan Tabel distribusi normal.
Untuk memahami penerapannya, misalkan diketahui probabilitas suatu pompa air rusak disuatu kawasan adalah 0,4. Jika pada kawasan tersebut terdapat 100 buah pompa. Hitunglah probabilitas jumlah pompa rusak di kawasan tersebut kurang dari 30? ?
Pada kasus tersebut kejadian sukses didefinisikan jika terdapat pompa yang rusak. Untuk menghitungnya pertama-tama kita perlu menghitung nilai mean dan simpangan baku dari populasinya.
\[ \mu=np=\left(100\right)\left(0,4\right)=40\ \ \ dan\ \ \ \sigma=\sqrt{npq}=\sqrt{\left(100\right)\left(0,4\right)\left(0,6\right)}=4,899 \] Selanjutnya dihitung nilai \(z\) dengan nilai \(X=29,5\) berdasarkan Persamaan (23).
\[ Z=\frac{29,5-40}{\sqrt{4,899}}=-2,14 \]
Dengan menggunakan tabel distribusi normal standard, probabilitas dari kejadian tersebut adalah sebagai berikut (lihat Gambar 8):
\[ P\left(X<30\right)\approx P\left(Z<-2,14\right)=0,0162. \]
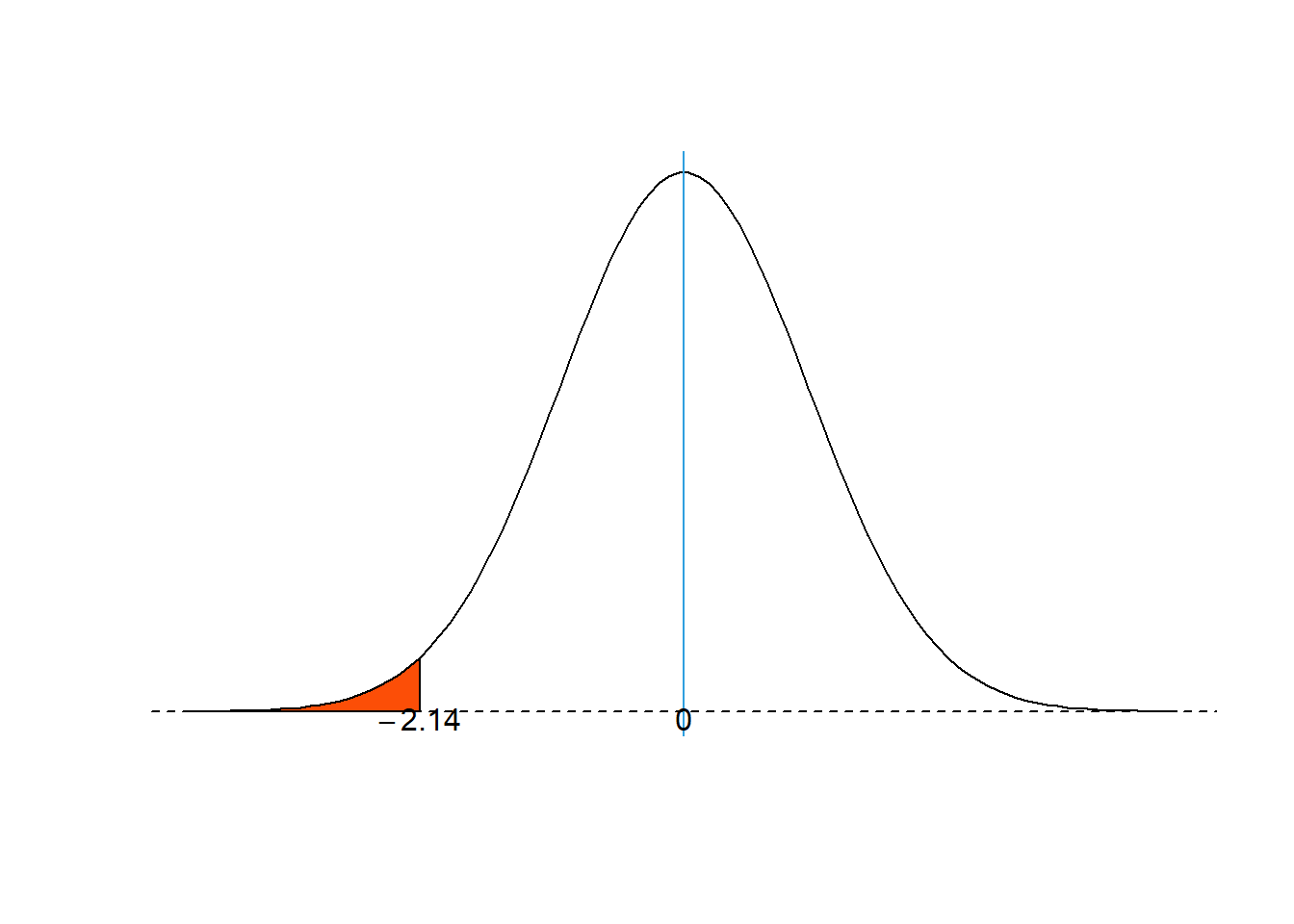
Figure 10: Luas area jumlah pompa rusak kurang dari 30.
Pada R probabilitas dari peristiwa tersebut dapat dihitung seperti berikut:
pnorm(q=29.5,mean=40,sd=4.899)## [1] 0.016044739.8 Distribusi Gamma dan Eksponensial
Distribusi eksponensial dan gamma merupakan distribusi yang berperan penting dalam menjelaskan teori antrian dan masalah reliabilitas. Waktu antara kedatangan di fasilitas layanan dan waktu kegagalan komponen bagian dan sistem kelistrikan sering dimodelkan dengan baik oleh distribusi eksponensial. Hubungan antara gamma dan eksponensial memungkinkan gamma digunakan dalam jenis masalah yang serupa.
Variabel acak kontinu \(X\) memiliki distribusi gamma, dengan parameter \(\alpha\) dan \(\beta\). Fungsi densitas dari distribusi tersebut dituliskan kedalam Persamaan (24).
\[\begin{equation} f\left(x;\alpha ,\beta \right) = \begin{cases} \frac{1}{\beta^{\alpha}\Gamma\left(\alpha\right)}x^{\alpha-1}e^{-\frac{x}{\beta}} & \quad x>0\\ 0 & \quad\text{} \end{cases} \tag{24} \end{equation}\]dimana \(\Gamma\left(\alpha\right)\) merupakan fungsi gamma yang dituliskan pada Persamaan (25)
\[\begin{equation} \Gamma\left(\alpha\right)=\int_0^{\infty}x^{\alpha-1}e^{-x}dx \tag{25} \end{equation}\]Pada Gambar 11 disajikan visualisasi distribusi gamma dengan variasi \(\alpha\) dan \(\beta\).
x <- seq(0,6, length=100)
x1 <- dgamma(x, shape=1, scale=1); x1_cum <- cumsum(x1)/max(cumsum(x1))
x2 <- dgamma(x, shape=2, scale=1); x2_cum <- cumsum(x2)/max(cumsum(x2))
x3 <- dgamma(x, shape=4, scale=1); x3_cum <- cumsum(x3)/max(cumsum(x3))
data <- data.frame(value=c(x,x,x),
density=c(x1,x2,x3),
cum_dens=c(x1_cum,x2_cum,x3_cum),
alpha=gl(3,length(x1),
labels=c(1,2,4)))
dens <- ggplot(data, aes(x=value, y=density, color=alpha))+
geom_line()+
scale_color_manual(values=c("#E7B800","#2E9FDF","#FC4E07")
)
ecdf <- ggplot(data, aes(x=value, y=cum_dens, color=alpha))+
geom_line()+
labs(y="Fn(x)")+
scale_color_manual(values=c("#E7B800","#2E9FDF","#FC4E07")
)
ggarrange(dens, ecdf, nrow=1, ncol=2, labels=c("a)","b)"))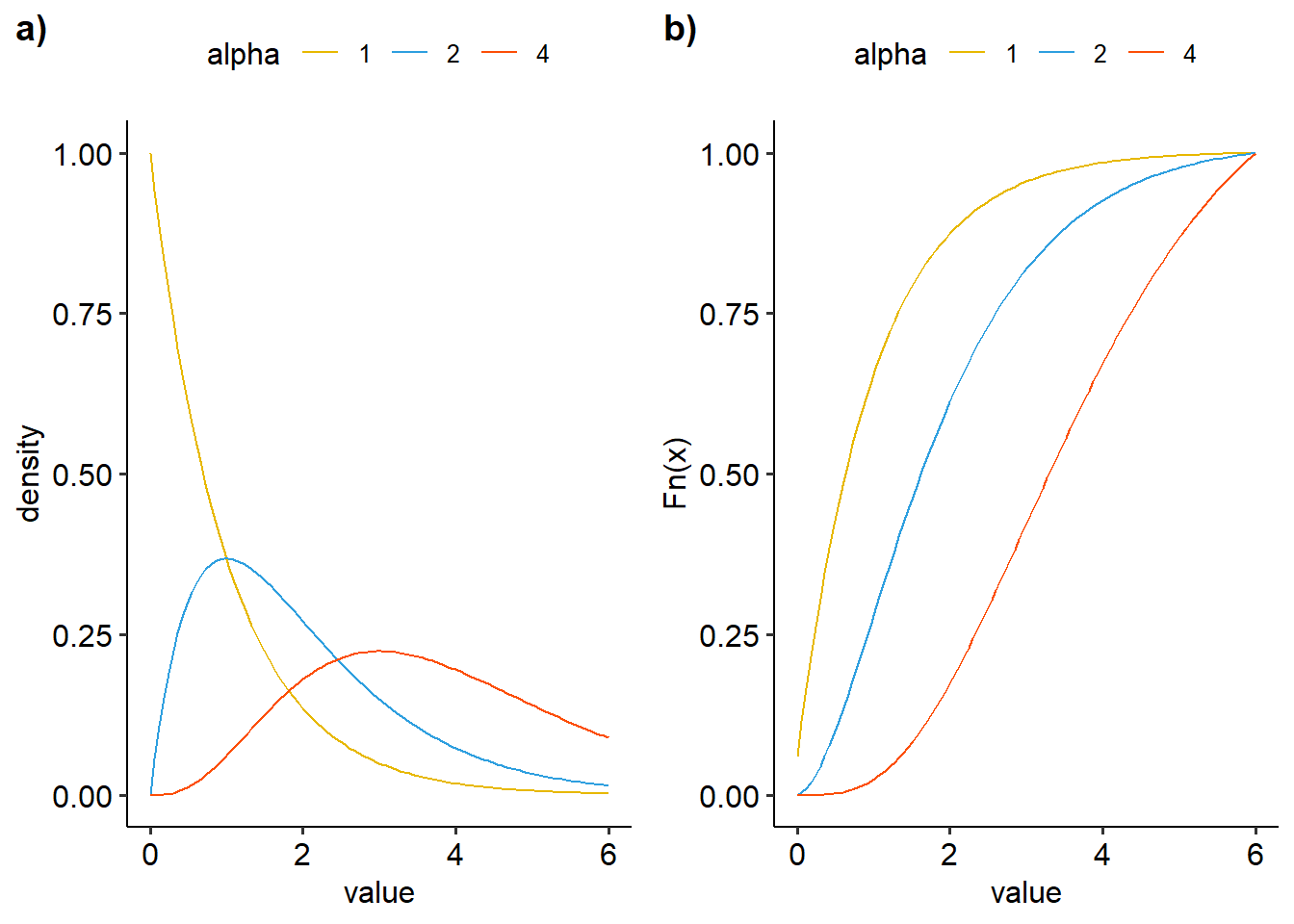
Figure 11: Visualisasi distribusi gamma dengan variasi alpha dengan beta 1 a) density plot, b)ecdf
Distribusi eksponensial merupakan kasus khusus dari distribusi gamma dengan nilai \(\alpha=1\). Distribusi probabilitas eksponensial dituliskan kedalam Persamaan (26).
\[\begin{equation} f\left(x;\beta \right) = \begin{cases} \frac{1}{\beta}e^{-\frac{x}{\beta}} & \quad x>0\\ 0 & \quad\text{} \end{cases} \tag{26} \end{equation}\]dimana \(\beta>0\).
Persamaan-persamaan berikut merupakan cara untuk menghitung mean dan varians dari kedua distribusi tersebut. Persamaan (27) merupakan persamaan untuk menghitung kedua nilai tersebut untuk distribusi gamma, sedangkan Persamaan (28) digunakan pada distribusi eksponensial.
\[\begin{equation} \mu=\alpha\beta\ \ \ dan\ \ \ \sigma^2=\alpha\beta^2 \tag{27} \end{equation}\] \[\begin{equation} \mu=\beta\ \ \ dan\ \ \ \sigma^2=\beta^2 \tag{28} \end{equation}\]Misalkan dalam suatu kawasan terdapat sistem penyediaan air minum lingkup kecil dengan komponen utama pompa, dimana waktu dalam tahun dimana pompa tersebut gagal beroperasi (rusak) disimbolkan sebagai \(T\). Variabel acak \(T\) dimodelkan dengan cukup baik menggunakan distribusi eksponensial dengan waktu sampai pompa tersebut gagal berfungsi \(\beta=5\). Jika 5 buah pompa dipasang pada sistem yang berbeda , berapa probabilitas setidaknya 2 buah pompa masih berfungsi hingga akhir tahun ke-8?
Probabilitas suatu pompa masih dapat berfungsi setelah 8 tahun dari kasus tersebut dapat dituliskan sebagai berikut:
\[ P\left(T>8\right)=\frac{1}{5}\int_0^{\infty}e^{-\frac{t}{5}}dt=e^{-\frac{8}{5}}\approx0,2. \]
Probabilitas sedikitnya 2 buah pompa yang masih beroperasi setelah 8 tahun dapat dihitung menggunakan probabilitas kumulatif distribusi binomial seperti berikut:
\[ P\left(X\ge2\right)=\sum_{x=2}^5b\left(x;5,0.2\right)=1-\sum_{x=0}^1b\left(x;5,0.2\right)=1-0,7373=0,2627 \]
Pada R probabilitas gamma dapat dihitung menggunakan 2 fungsi yaitu dgamma() dan pgamma() (probabilitas kumulatif). Format fungsi tersebut adalah sebagai berikut:
dexp(x, rate=1)
pexp(q, rate=1, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil
- rate: nilai 1/beta
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
Berikut adalah sintaks yang digunakan untuk menghitung probabilitas pada contoh soal tersebut:
# probabilitas pompa masih berfungsi lebih dari 8 tahun
pexp(q=8, rate=1/5, lower.tail=FALSE)## [1] 0.2018965# probabilitas sedikitnya 2 pompa yang masih berfungsi
pbinom(q=1, size=5, prob=0.2018965, lower.tail=FALSE)## [1] 0.2666086Contoh lainnya misalkan pada pengujian toksikan terhadap hewan uji untuk menentukan dosis mematikan pada suatu hewan uji. Toksikan yang digunakan merupakan logam berat yang ada di perairan. Berdasarkan dosis tertentu, hasil percobaan menentukan bahwa survival time, dalam minggu dari hewan uji, memiliki distribusi gamma dengan \(\alpha=5\) dan \(\beta=10\). Hitunglah probabilitas hewan uji tidak dapat selamat tidak lebih dari 60 minggu?
Diberikan variabel acak \(X\) yang menyatakan survival time (waktu hingga mati). Probabilitas yang terjadi dapat dituliskan sebagai berikut:
\[ P\left(X\le60\right)=\frac{1}{\beta^5}\int_0^{\infty}\frac{x^{\alpha-1}e^{-\frac{x}{\beta}}}{\Gamma\left(5\right)}dx \]
Intergral pada persamaan diatas dapat diselesaikan dengan menggunakan incomplete gamma function, yang menjadikan persamaan di atas menjadi fungsi distribusi kumulatif untuk distribusi gamma yang dapat dituliskan kembali seperti berikut:
\[ F\left(x;\alpha\right)=\int_0^x\frac{y^{\alpha-1}e^{-y}}{\Gamma\left(\alpha\right)}dy \]
jika diberikan \(y=\frac{x}{\beta}\) dan \(x=\beta y\), persamaan tersebut dapat dituliskan lagi menjadi berikut:
\[ P\left(X\le60\right)=\int_0^6\frac{y^4e^{-y}}{\Gamma\left(\alpha\right)}dy \]
yang dapat dituliskan sebagai \(F\left(6;5\right)\) pada tabel incomplete gamma function yang dapat pembaca lihat pada buku yang ditulis oleh Ronald E. Walpole (2012) pada Appendix A.23. Berdasarkan tabel tersebut diperoleh nilai probabilitas sebagai berikut:
\[ P\left(X\le60\right)=F\left(6;5\right)=0,715 \]
Pada R probabilitas distribusi gamma dapat dihitung menggunakan fungsi dgamma() dan pgamma() (probabilitas kumulatif). Format fungsi tersebut adalah sebagi berikut:
dgamma(x, shape, scale)
pgamma(q, shape, scale, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil
- shape: nilai alpha
- scale: niali beta
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
Berikut adalah nilai probabilitas dari contoh kasus tersebut:
pgamma(q=60, shape=5, scale=10)## [1] 0.71494359.9 Distribusi Chi-Square, Student’s t, dan Snedecor’s F
Pada sub-chapter kali ini penulis akan menjelaskan sejumlah distribusi probabilitas yang memegang peranan penting dalam statistika inferensi. Distribusi ini tidak akan penulis jelaskan secara detail karena akan terdapat porsi tersendiri pada chapter selanjutnya.
9.9.1 Distribusi Chi-Square
Distribusi chi-square merupakan kasus khusu lain dari distribusi gamma, dimana nilai \(\alpha\) dan \(\beta\) dari distribusi ini masing-masing adalah \(\alpha=\nu/2\) dan \(\beta=2\) dengan nilai \(\nu\) merupakan integer positif. Distribusi ini memiliki parameter tunggal yaitu \(\nu\) yang disebut sebagai degrees of freedom (derajat kebebasan). Fungsi densitas distribusi ini disajikan pada Persamaan (29).
\[\begin{equation} f\left(x;\nu \right) = \begin{cases} \frac{1}{2^{\frac{\nu}{2}}\Gamma\left(\frac{\nu}{2}\right)}x^{\frac{\nu}{2}-1}e^{-\frac{x}{2}} & \quad x>0\\ 0 & \quad\text{} \end{cases} \tag{29} \end{equation}\]dimana \(\nu\) adalah integer positif.
Pada Gambar 12 disajikan visualisasi distribusi chi-square dengan variasi \(\nu\).
x <- seq(0,20, length=100)
x1 <- dchisq(x, df=1); x1_cum <- cumsum(x1)/max(cumsum(x1))
x2 <- dchisq(x, df=3); x2_cum <- cumsum(x2)/max(cumsum(x2))
x3 <- dchisq(x, df=5); x3_cum <- cumsum(x3)/max(cumsum(x3))
x4 <- dchisq(x, df=7); x4_cum <- cumsum(x4)/max(cumsum(x4))
data <- data.frame(value=c(x,x,x,x),
density=c(x1,x2,x3,x4),
cum_dens=c(x1_cum,x2_cum,x3_cum,x4_cum),
df=gl(4,length(x1),
labels=c(1,3,5,7)))
dens <- ggplot(data, aes(x=value, y=density, color=df))+
geom_line()+
scale_color_manual(values=c("#E7B800", "#2E9FDF", "#FC4E07", "black"))
ecdf <- ggplot(data, aes(x=value, y=cum_dens, color=df))+
geom_line()+
labs(y="Fn(x)")+
scale_color_manual(values=c("#E7B800", "#2E9FDF", "#FC4E07","black"))
ggarrange(dens, ecdf, nrow=1, ncol=2, labels=c("a)","b)"))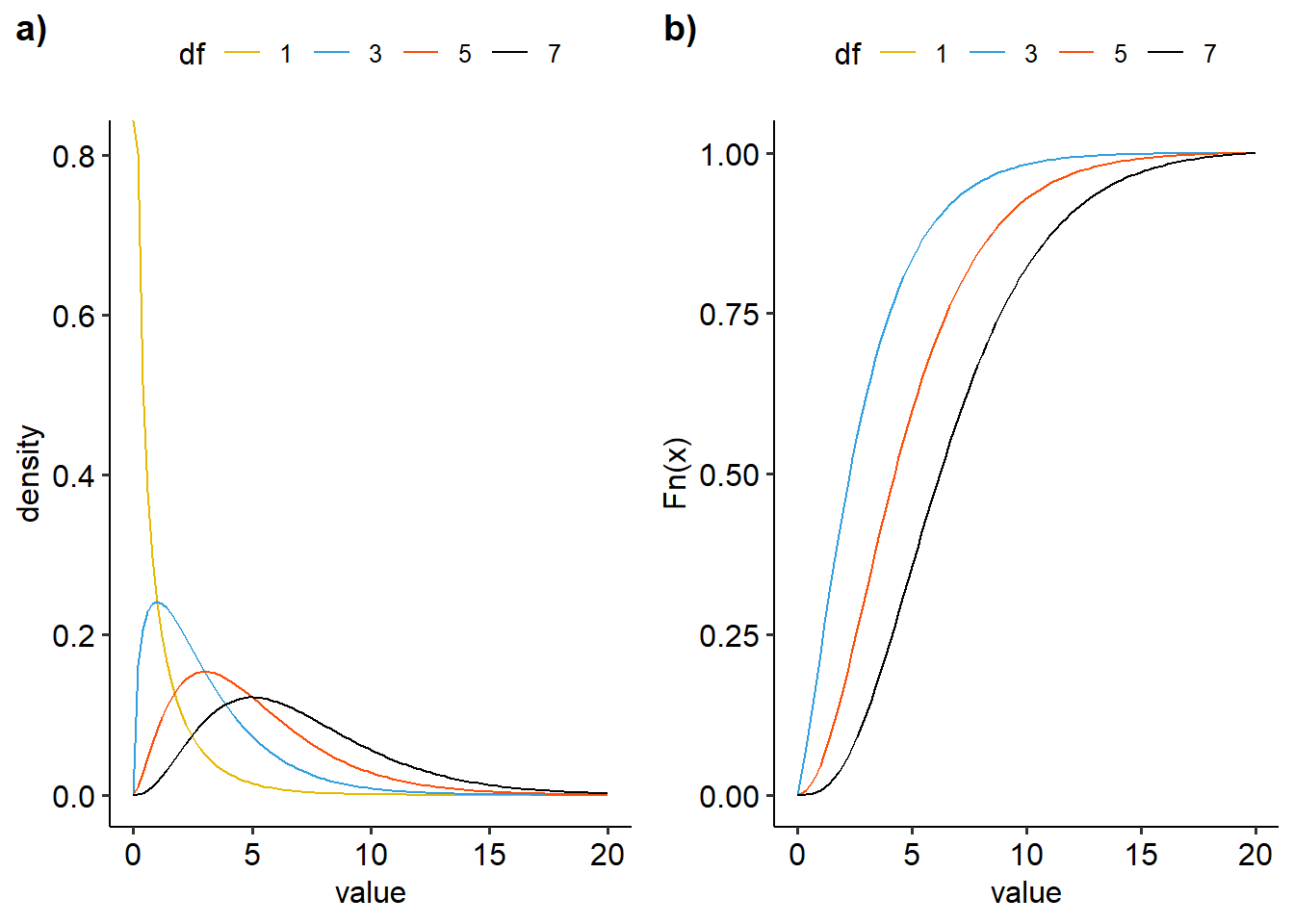
Figure 12: Visualisasi distribusi chi-square dengan variasi derajat kebebasan a) density plot, b)ecdf
Pada R terdapat dua buah fungsi yang digunakan untuk menghitung probabilitas distribusi chi-square yaitu dchisq() dan pchisq() (probabilitas kumulatif). Format fungsi tersebut adalah sebagai berikut:
dgamma(x, df)
pgamma(q, df, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil
- df: derajat kebebasan (n-1)
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
9.9.2 Distribusi Student’s t
Distribusi student’s t merupakan kasus lain dari distribusi gamma. Fungsi densitas probabilitasnya disajikan pada Persamaan (30).
\[\begin{equation} \frac{\Gamma\left[\frac{\left(r+1\right)}{2}\right]}{\sqrt{r\pi}\Gamma\left(\frac{r}{2}\right)}\left(1+\frac{x^2}{r}\right)^{-\frac{\left(r+1\right)}{2}},\ \ \ \ \ -\infty<x<\infty \tag{30} \end{equation}\]dimana \(r\) merupakan derajat kebebasan atau \(\left(n-1\right)\).
Pada Gambar 13 disajikan visualisasi distribusi t dengan variasi \(r\).
x <- seq(-7,7, length=100)
x1 <- dt(x, df=1); x1_cum <- cumsum(x1)/max(cumsum(x1))
x2 <- dt(x, df=12); x2_cum <- cumsum(x2)/max(cumsum(x2))
x3 <- dt(x, df=20); x3_cum <- cumsum(x3)/max(cumsum(x3))
x4 <- dnorm(x); x4_cum <- cumsum(x4)/max(cumsum(x4))
data <- data.frame(value=c(x,x,x,x),
density=c(x1,x2,x3,x4),
cum_dens=c(x1_cum,x2_cum,x3_cum,x4_cum),
df=gl(4,length(x1),
labels=c(1,12,20,"Normal")))
dens <- ggplot(data, aes(x=value, y=density, color=df))+
geom_line()+
scale_color_manual(values=c("#E7B800", "#2E9FDF", "#FC4E07", "black"))
ecdf <- ggplot(data, aes(x=value, y=cum_dens, color=df))+
geom_line()+
labs(y="Fn(x)")+
scale_color_manual(values=c("#E7B800", "#2E9FDF", "#FC4E07", "black"))
ggarrange(dens, ecdf, nrow=1, ncol=2, labels=c("a)","b)"))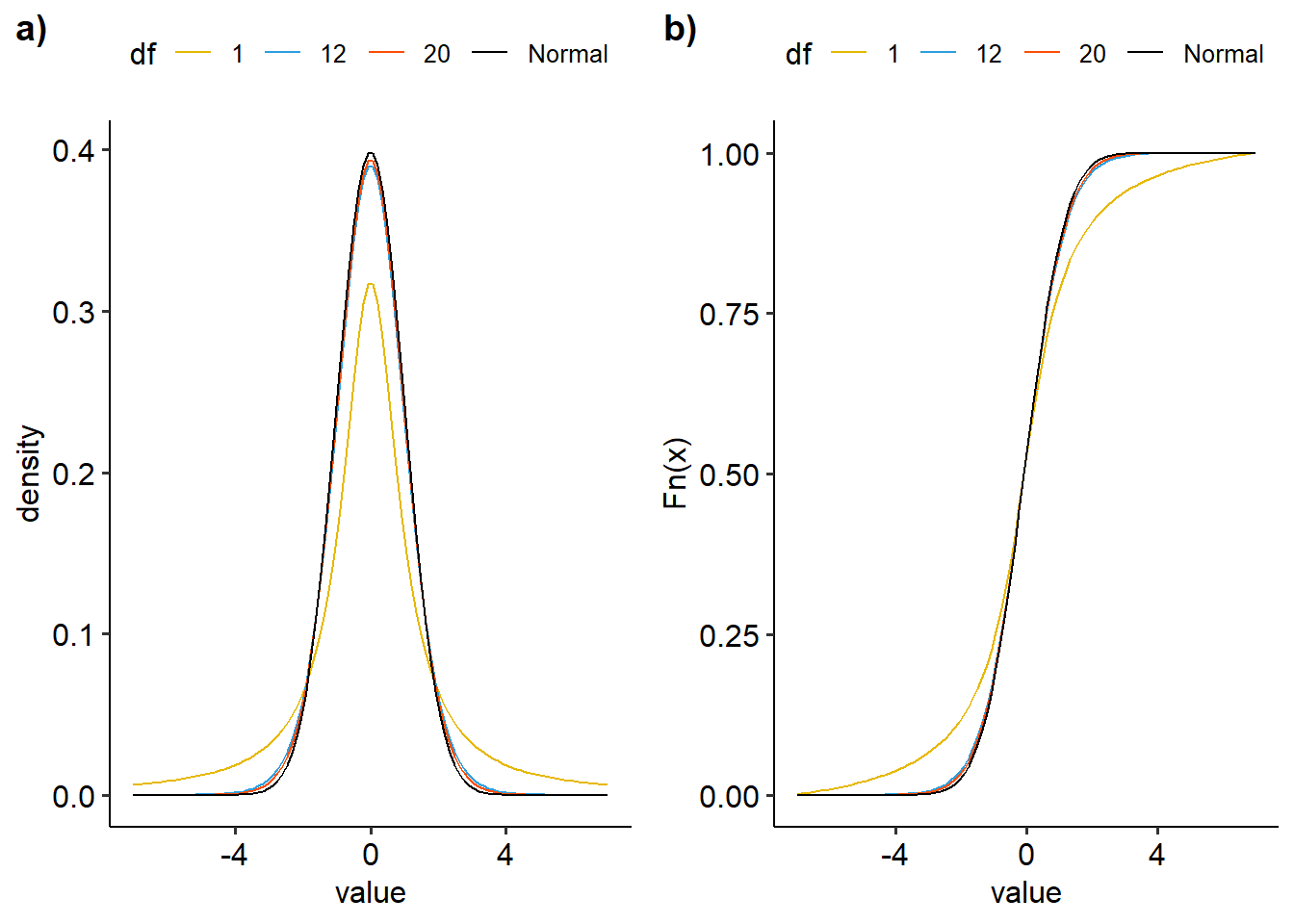
Figure 13: Visualisasi distribusi t dengan variasi derajat kebebasan a) density plot, b)ecdf
Jika kita perhatikan dengan seksama terlihat bahwa peningkatan derajat kebebasan akan membuat distribusi yag dihasilkan semakin mendekati kurva normal.
Pada R terdapat dua fungsi yang berguna untuk menghitung probabilitas distribusi t yaitu dt() dan pt() (probabilitas kumulatif). Format fungsi yang digunakan adalah sebagai berikut:
dt(x, df)
pt(q, df, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil
- df: derajat kebebasan (n-1)
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
9.9.3 Distribusi Snedecor’s F
Fungsi densitas probabilitas distribusi F disajikan pada Persamaan (31).
\[\begin{equation} f\left(x;df1,df2 \right) = \begin{cases} \frac{\Gamma\left[\frac{\left(df1+df2\right)}{2}\right]}{\Gamma\left(\frac{df1}{2}\right)\Gamma\left(\frac{df2}{2}\right)}\left(\frac{df1}{df2}\right)^{\frac{df1}{2}}x^{\frac{df1}{2}-1}\left(1+\frac{df1}{df2}x\right)^{-\frac{\left(df1+df2\right)}{2}} & \quad x>0\\ 0 & \quad\text{} \end{cases} \tag{31} \end{equation}\]dimana \(df1\) dan \(df2\) merupakan derajat kebebasan.
Pada Gambar 14 disajikan visualisasi distribusi F dengan variasi \(df1\) dan \(df2\).
x <- seq(0,5, length=100)
x1 <- df(x, df1=1, df2=10); x1_cum <- cumsum(x1)/max(cumsum(x1))
x2 <- df(x, df1=6, df2=60); x2_cum <- cumsum(x2)/max(cumsum(x2))
x3 <- df(x, df1=10,df2=100); x3_cum <- cumsum(x3)/max(cumsum(x3))
data <- data.frame(value=c(x,x,x),
density=c(x1,x2,x3),
cum_dens=c(x1_cum,x2_cum,x3_cum),
df1=gl(3,length(x1),
labels=c(1,6,10)),
df2=gl(3,length(x1),
labels=c(10,60,100)))
dens <- ggplot(data, aes(x=value, y=density, color=df1, linetype=df2))+
geom_line()+
theme(legend.position="right", legend.box="vertical")+
guides(color=FALSE)+
scale_color_manual(values=c("#E7B800", "#2E9FDF", "#FC4E07"))
ecdf <- ggplot(data, aes(x=value, y=cum_dens, color=df1, linetype=df2))+
geom_line()+
labs(y="Fn(x)")+
theme(legend.position="right", legend.box="vertical")+
guides(linetype=FALSE)+
scale_color_manual(values=c("#E7B800", "#2E9FDF", "#FC4E07"))
ggarrange(dens, ecdf, nrow=2, ncol=1, labels=c("a)","b)"))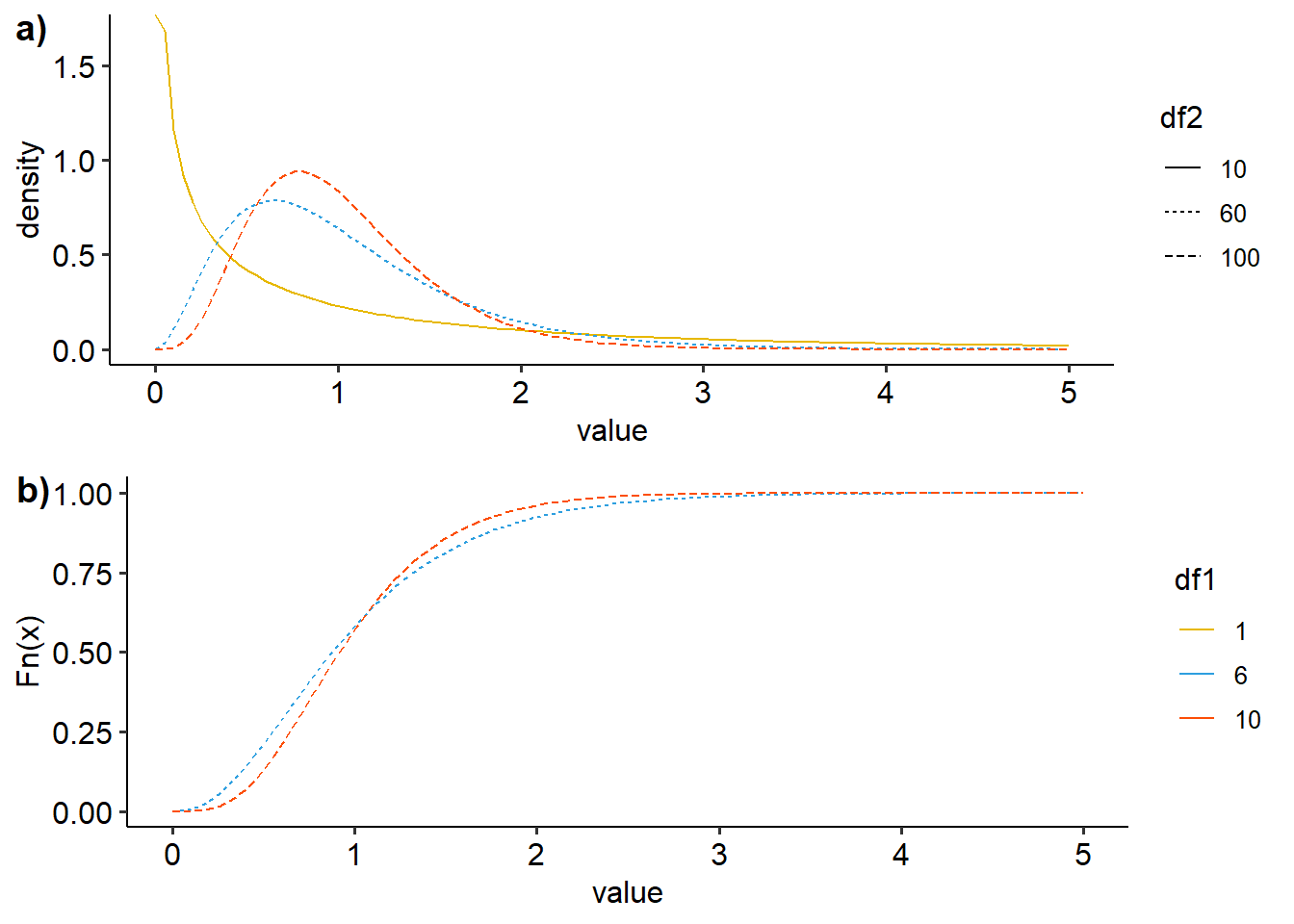
Figure 14: Visualisasi distribusi F dengan variasi derajat kebebasan a) density plot, b)ecdf
Pada R terdapat dua fungsi yang berguna untuk menghitung probabilitas distribusi F yaitu df() dan pf() (probabilitas kumulatif). Format fungsi yang digunakan adalah sebagai berikut:
dt(x, df1, df2)
pt(q, df1, df2, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil.
- df1,df2: derajat kebebasan.
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
9.10 Distribusi Kontinu Lainnya
9.10.1 Distribusi Beta
Distribusi ini merupakan perluasan dari distribusi uniform. Distribusi ini didasarkan pada fungsi beta yang disajikan pada Persamaan (32).
\[\begin{equation} B\left(\alpha,\beta\right)=\int_0^1x^{\alpha-1}\left(1-x\right)^{\beta-1}dx=\frac{\Gamma\left(\alpha\right)\Gamma\left(\beta\right)}{\Gamma\left(\alpha+\beta\right)},\ \ \ untuk\ \alpha,\beta>0 \tag{32} \end{equation}\]dimana \(\Gamma\left(\alpha\right)\) merupakan fungsi gamma.
Suatu variabel acak kontinu \(X\) memiliki distribusi beta dengan parameter \(\alpha>0\) dan \(\beta>0\) jika densitas fungsiya diberikan pada Persamaan (33).
\[\begin{equation} f\left(x \right) = \begin{cases} \frac{1}{B\left(\alpha,\beta\right)}x^{\alpha-1}\left(1-x\right)^{\beta-1} & \quad 0<x<1\\ 0 & \quad\text{} \end{cases} \tag{33} \end{equation}\]Nilai mean dan varians distribusi beta dituliskan kedalam Persamaan (34).
\[\begin{equation} \mu=\frac{\alpha}{\alpha+\beta}\ \ \ \ dan\ \ \ \ \sigma^2=\frac{\alpha\beta}{\left(\alpha+\beta\right)^2\left(\alpha+\beta+1\right)} \tag{34} \end{equation}\]Pada Gambar 15 disajikan visualisasi distribusi beta dengan variasi \(\alpha\) dan \(\beta\).
x <- seq(0,1, length=100)
x1 <- dbeta(x, shape1=1, shape2=5); x1_cum <- cumsum(x1)/max(cumsum(x1))
x2 <- dbeta(x, shape1=6, shape2=30); x2_cum <- cumsum(x2)/max(cumsum(x2))
x3 <- dbeta(x, shape1=10,shape2=50); x3_cum <- cumsum(x3)/max(cumsum(x3))
data <- data.frame(value=c(x,x,x),
density=c(x1,x2,x3),
cum_dens=c(x1_cum,x2_cum,x3_cum),
alpha=gl(3,length(x1),
labels=c(1,6,10)),
beta=gl(3,length(x1),
labels=c(10,60,100)))
dens <- ggplot(data, aes(x=value, y=density, color=alpha, linetype=beta))+
geom_line()+
theme(legend.position="right", legend.box="vertical")+
guides(color=FALSE)+
scale_color_manual(values=c("#E7B800", "#2E9FDF", "#FC4E07"))
ecdf <- ggplot(data, aes(x=value, y=cum_dens, color=alpha, linetype=beta))+
geom_line()+
labs(y="Fn(x)")+
theme(legend.position="right", legend.box="vertical")+
guides(linetype=FALSE)+
scale_color_manual(values=c("#E7B800", "#2E9FDF", "#FC4E07"))
ggarrange(dens, ecdf, nrow=2, ncol=1, labels=c("a)","b)"))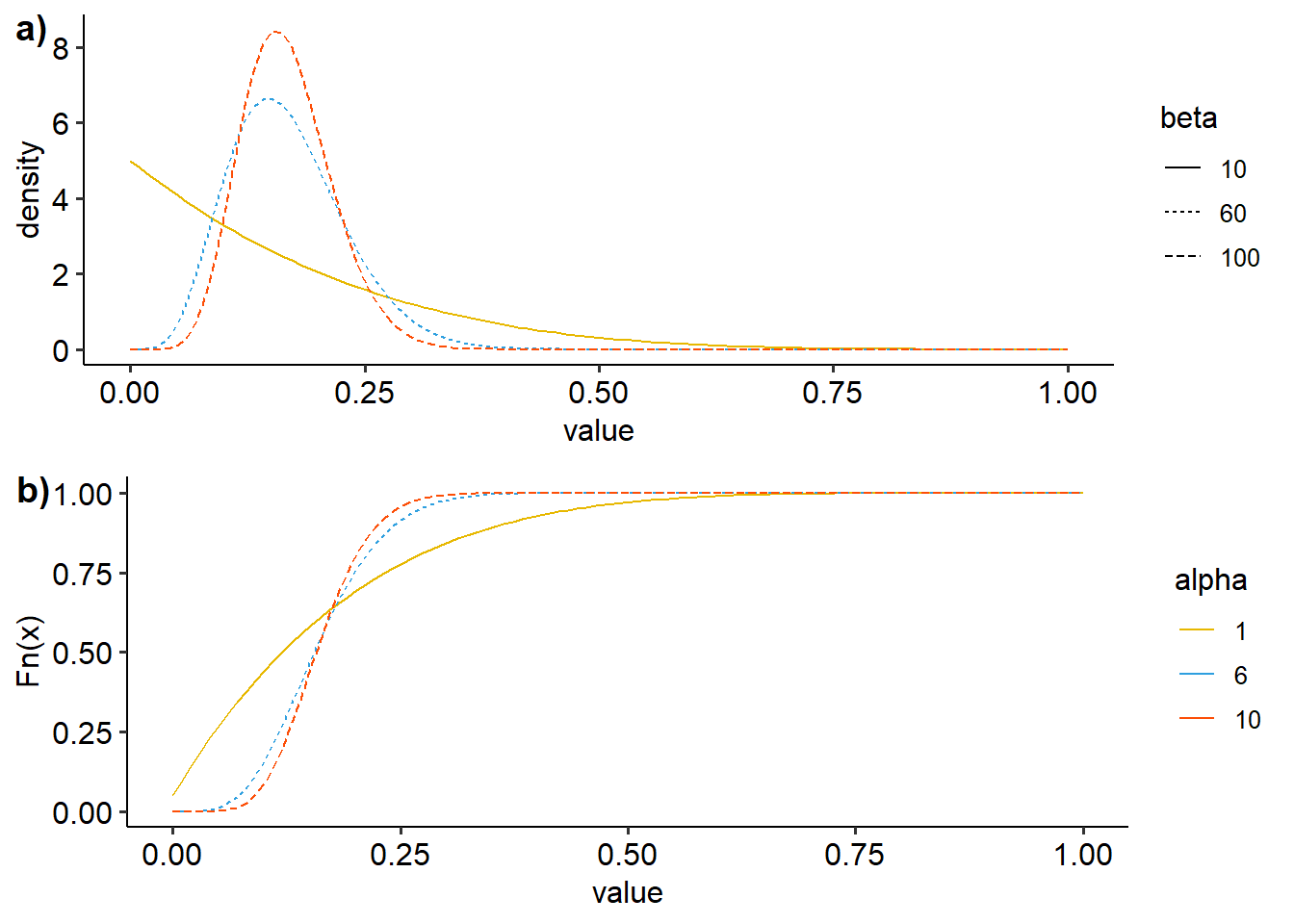
Figure 15: Visualisasi distribusi beta dengan variasi derajat kebebasan a) density plot, b)ecdf
Pada R terdapat dua fungsi yang berguna untuk menghitung probabilitas distribusi beta yaitu dbeta() dan pbeta() (probabilitas kumulatif). Format fungsi yang digunakan adalah sebagai berikut:
dbeta(x, shape1, shape2)
pbeta(q, shape1, shape2, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil.
- shape1: alpha.
- shape2: beta.
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
9.10.2 Distribusi Lognormal
Distribusi lognormal telah digunakan pada berbagai aplikasi yang luas. Distribusi berlaku dalam kasus di mana transformasi log natural menghasilkan distribusi normal.
Suatu variabel acak \(X\) berdistribusi lognormal jika variabel acak \(Y=ln\left(X\right)\) berdistribusi normal dengan nilai mean \(\mu\) dan simpangan baku \(\sigma\). Fungsi densitas yang digunakan disajikan pada Persamaan (35).
\[\begin{equation} f\left(x;\mu,\sigma \right) = \begin{cases} \frac{1}{\sqrt{2\pi\sigma x}}e^{-\frac{1}{2\sigma^2}\left[\ln\left(x\right)-\mu\right]^2} & \quad x\ge 0\\ 0 & \quad x<0 \end{cases} \tag{35} \end{equation}\]Nilai mean dan varians distribusi lognormal dihitung menggunakan Persamaan (36).
\[\begin{equation} \mu=e^{\mu+\frac{\sigma^2}{2}}\ \ \ \ dan\ \ \ \ \sigma^2=e^{2\mu+\sigma^2}\left(e^{\sigma^2}-1\right) \tag{36} \end{equation}\]Pada Gambar 16 disajikan visualisasi distribusi lognormal dengan variasi \(\mu\) dan \(\sigma\).
x <- seq(0,5, length=100)
x1 <- dlnorm(x, meanlog=0, sdlog=1); x1_cum <- cumsum(x1)/max(cumsum(x1))
x2 <- dlnorm(x, meanlog=1, sdlog=1.5); x2_cum <- cumsum(x2)/max(cumsum(x2))
x3 <- dlnorm(x, meanlog=2, sdlog=2); x3_cum <- cumsum(x3)/max(cumsum(x3))
data <- data.frame(value=c(x,x,x),
density=c(x1,x2,x3),
cum_dens=c(x1_cum,x2_cum,x3_cum),
mean=gl(3,length(x1),
labels=c(0,1,2)),
sd=gl(3,length(x1),
labels=c(1,1.5,2)))
dens <- ggplot(data, aes(x=value, y=density, color=mean, linetype=sd))+
geom_line()+
theme(legend.position="right", legend.box="vertical")+
guides(color=FALSE)+
scale_color_manual(values=c("#E7B800", "#2E9FDF", "#FC4E07"))
ecdf <- ggplot(data, aes(x=value, y=cum_dens, color=mean, linetype=sd))+
geom_line()+
labs(y="Fn(x)")+
theme(legend.position="right", legend.box="vertical")+
guides(linetype=FALSE)+
scale_color_manual(values=c("#E7B800", "#2E9FDF", "#FC4E07"))
ggarrange(dens, ecdf, nrow=2, ncol=1, labels=c("a)","b)"))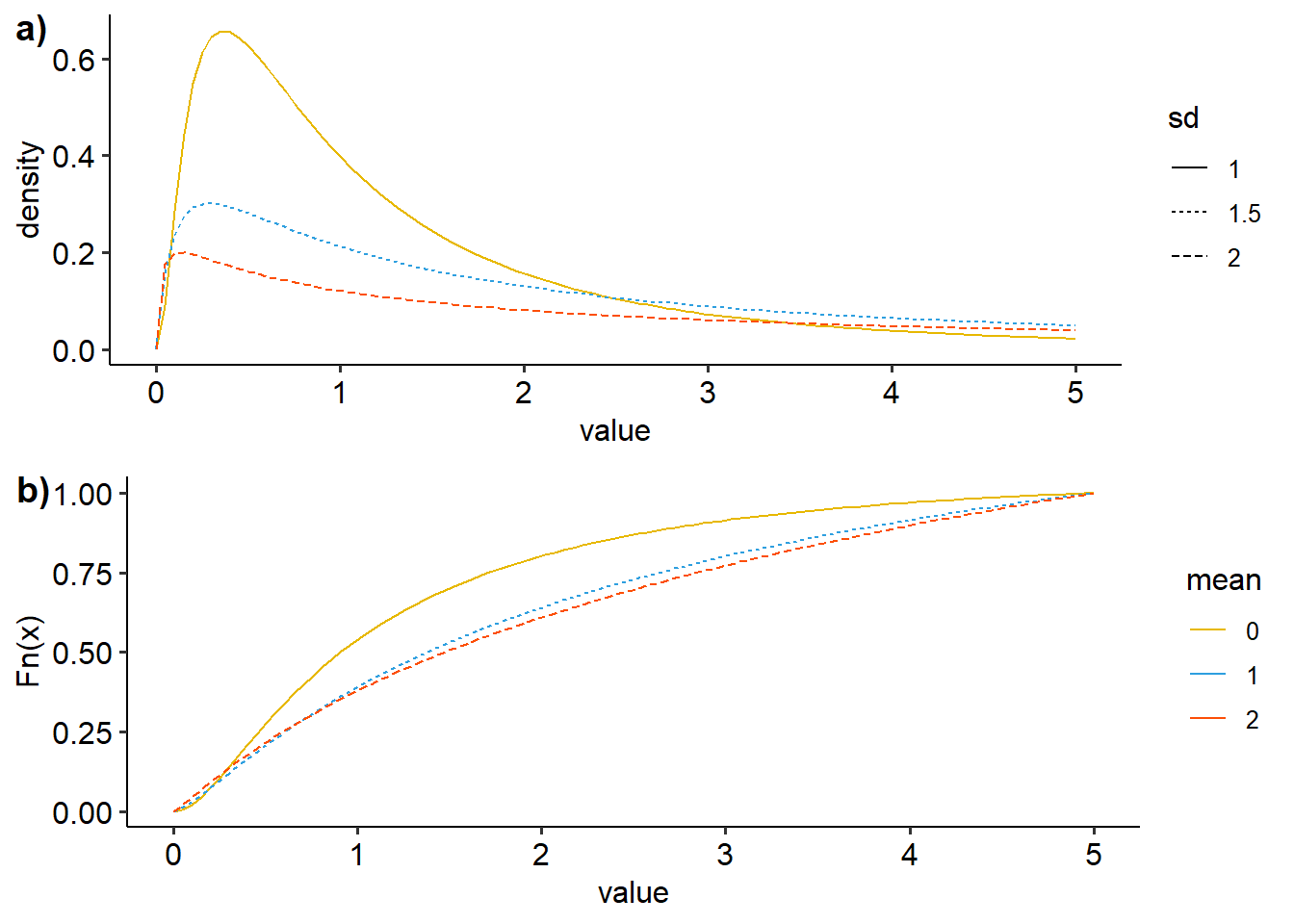
Figure 16: Visualisasi distribusi beta dengan variasi mean dan sd a) density plot, b)ecdf
Pada R, fungsi utama yang digunakan untuk menghitung probabilitas distribusi lognormal adalah dlnorm() dan plnorm() (probabilitas kumulatif). Format fungsi tersebut adalah sebagai berikut:
dlnorm(x, meanlog = 0, sdlog = 1)
plnorm(q, meanlog = 0, sdlog = 1, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil.
- meanlog: mean dalam bentuk logaritmik.
- sdlog: simpangan baku dalam bentuk logaritmik.
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
9.10.3 Distribusi Cauchy
Distribusi Chauchy merupakan kasus khusus dari distribusi t ketika nilai \(r\) atau derajat kebebasannya adalah 1. Distribusi ini tampak mirip dengan distribusi normal, namun dengan ekor yang lebih panjang. Parameter utama dari distribusi probabilitas ini adalah \(\beta\) dan \(m\) atau median. Fungsi densitas probabilitasnya dituliskan kedalam Persamaan (37).
\[\begin{equation} f\left(x;m,\beta\right)=\frac{1}{\beta\pi}\left[1+\left(\frac{x-m}{\beta}\right)^2\right]^{-1},\ \ \ \ \ \ \ \ -\infty<x<\infty \tag{37} \end{equation}\]Pada Gambar 17 disajikan visualisasi distribusi Cauchy dengan variasi \(m\) dan \(\beta\).
x <- seq(-7,7, length=100)
x1 <- dcauchy(x, location=0, scale=1); x1_cum <- cumsum(x1)/max(cumsum(x1))
x2 <- dcauchy(x, location=0.5, scale=1.5); x2_cum <- cumsum(x2)/max(cumsum(x2))
x3 <- dcauchy(x, location=1, scale=2); x3_cum <- cumsum(x3)/max(cumsum(x3))
x4 <- dnorm(x); x4_cum <- cumsum(x4)/max(cumsum(x4))
data <- data.frame(value=c(x,x,x,x),
density=c(x1,x2,x3,x4),
cum_dens=c(x1_cum,x2_cum,x3_cum,x4_cum),
m=gl(4,length(x1),
labels=c(0,1,1.5,"Normal")),
beta=gl(4,length(x1),
labels=c(1,1.5,2,"Normal")))
dens <- ggplot(data, aes(x=value, y=density, color=m, linetype=beta))+
geom_line()+
theme(legend.position="right", legend.box="vertical")+
guides(color=FALSE)+
scale_color_manual(values=c("#E7B800","#2E9FDF","#FC4E07","black"))
ecdf <- ggplot(data, aes(x=value, y=cum_dens, color=m, linetype=beta))+
geom_line()+
labs(y="Fn(x)")+
theme(legend.position="right", legend.box="vertical")+
guides(linetype=FALSE)+
scale_color_manual(values=c("#E7B800","#2E9FDF","#FC4E07","black"))
ggarrange(dens, ecdf, nrow=2, ncol=1, labels=c("a)","b)"))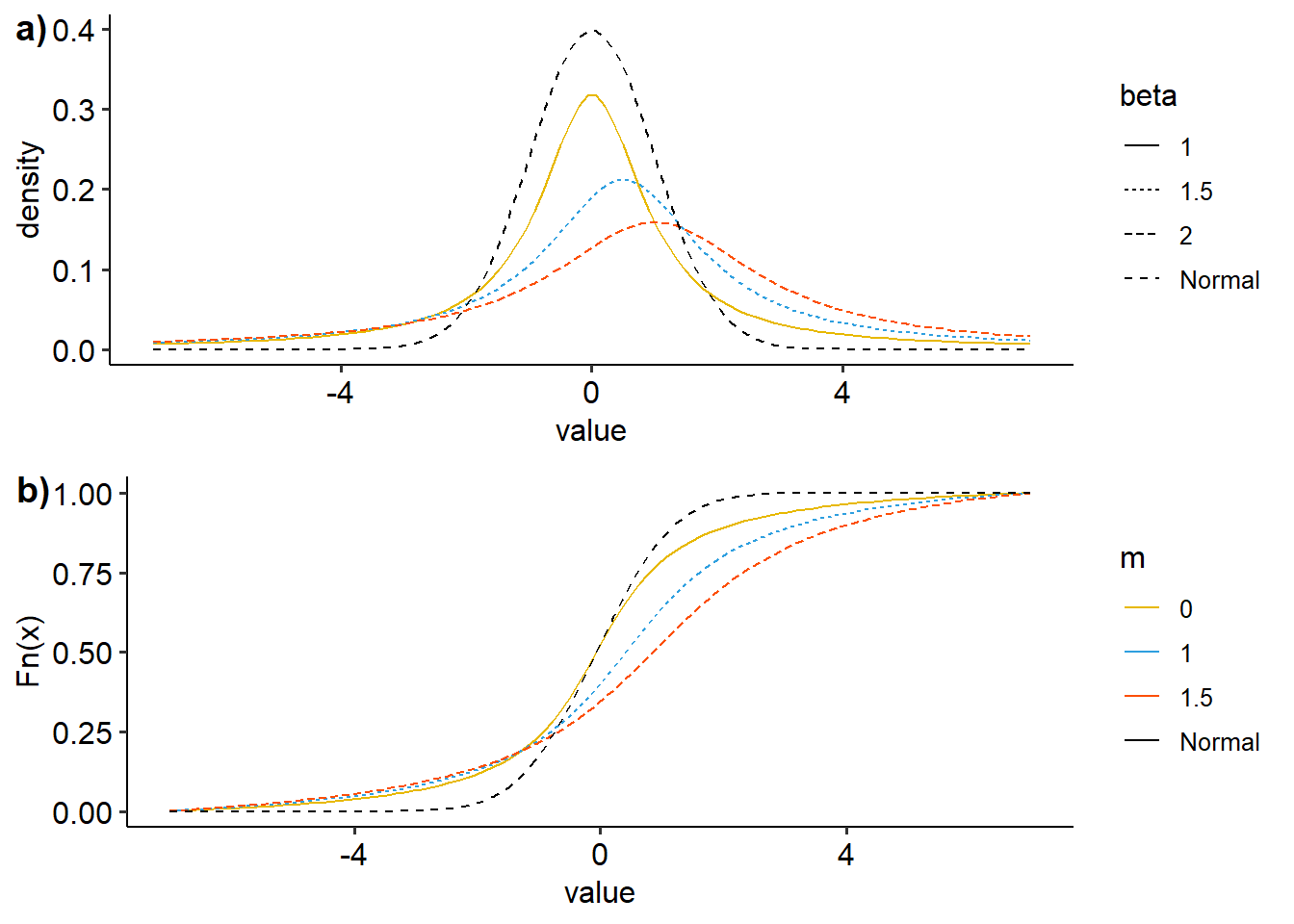
Figure 17: Visualisasi distribusi t dengan variasi m dan beta a) density plot, b)ecdf
Pada R, fungsi utama yang digunakan untuk menghitung probabilitas distribusi Cauchy adalah dcauchy() dan pcauchy() (probabilitas kumulatif). Format fungsi tersebut adalah sebagai berikut:
dcauchy(x, location = 0, scale = 1)
pcauchy(q, location = 0, scale = 1, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil.
- location: median.
- scale: beta.
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
9.10.4 Distribusi Logistik
Distribusi logistik sering diterapkan untuk memodelkan pertumbuahan populasi berdasarkan asumsi tertentu seperti keterbatasan lahan atau ruang atau bahkan makanan. Fungsi densitas probabilitas distribusi logistik disajikan pada Persamaan (38).
\[\begin{equation} f\left(x;\mu,\sigma\right)=\frac{1}{\sigma}\exp\left(-\frac{x-\mu}{\sigma}\right)\left[1+\exp\left(-\frac{x-\mu}{\sigma}\right)\right]^{-2},\ \ \ \ \ \ \ \ -\infty<x<\infty \tag{38} \end{equation}\]Pada Gambar 18 disajikan visualisasi distribusi Cauchy dengan variasi \(m\) dan \(\beta\).
x <- seq(-7,7, length=100)
x1 <- dlogis(x, location=0, scale=1); x1_cum <- cumsum(x1)/max(cumsum(x1))
x2 <- dlogis(x, location=0.5, scale=1.5); x2_cum <- cumsum(x2)/max(cumsum(x2))
x3 <- dlogis(x, location=1, scale=2); x3_cum <- cumsum(x3)/max(cumsum(x3))
x4 <- dnorm(x); x4_cum <- cumsum(x4)/max(cumsum(x4))
data <- data.frame(value=c(x,x,x,x),
density=c(x1,x2,x3,x4),
cum_dens=c(x1_cum,x2_cum,x3_cum,x4_cum),
mean=gl(4,length(x1),
labels=c(0,1,1.5,"Normal")),
sd=gl(4,length(x1),
labels=c(1,1.5,2,"Normal")))
dens <- ggplot(data, aes(x=value, y=density, color=mean, linetype=sd))+
geom_line()+
theme(legend.position="right", legend.box="vertical")+
guides(color=FALSE)+
scale_color_manual(values=c("#E7B800","#2E9FDF","#FC4E07","black"))
ecdf <- ggplot(data, aes(x=value, y=cum_dens, color=mean, linetype=sd))+
geom_line()+
labs(y="Fn(x)")+
theme(legend.position="right", legend.box="vertical")+
guides(linetype=FALSE)+
scale_color_manual(values=c("#E7B800","#2E9FDF","#FC4E07","black"))
ggarrange(dens, ecdf, nrow=2, ncol=1, labels=c("a)","b)"))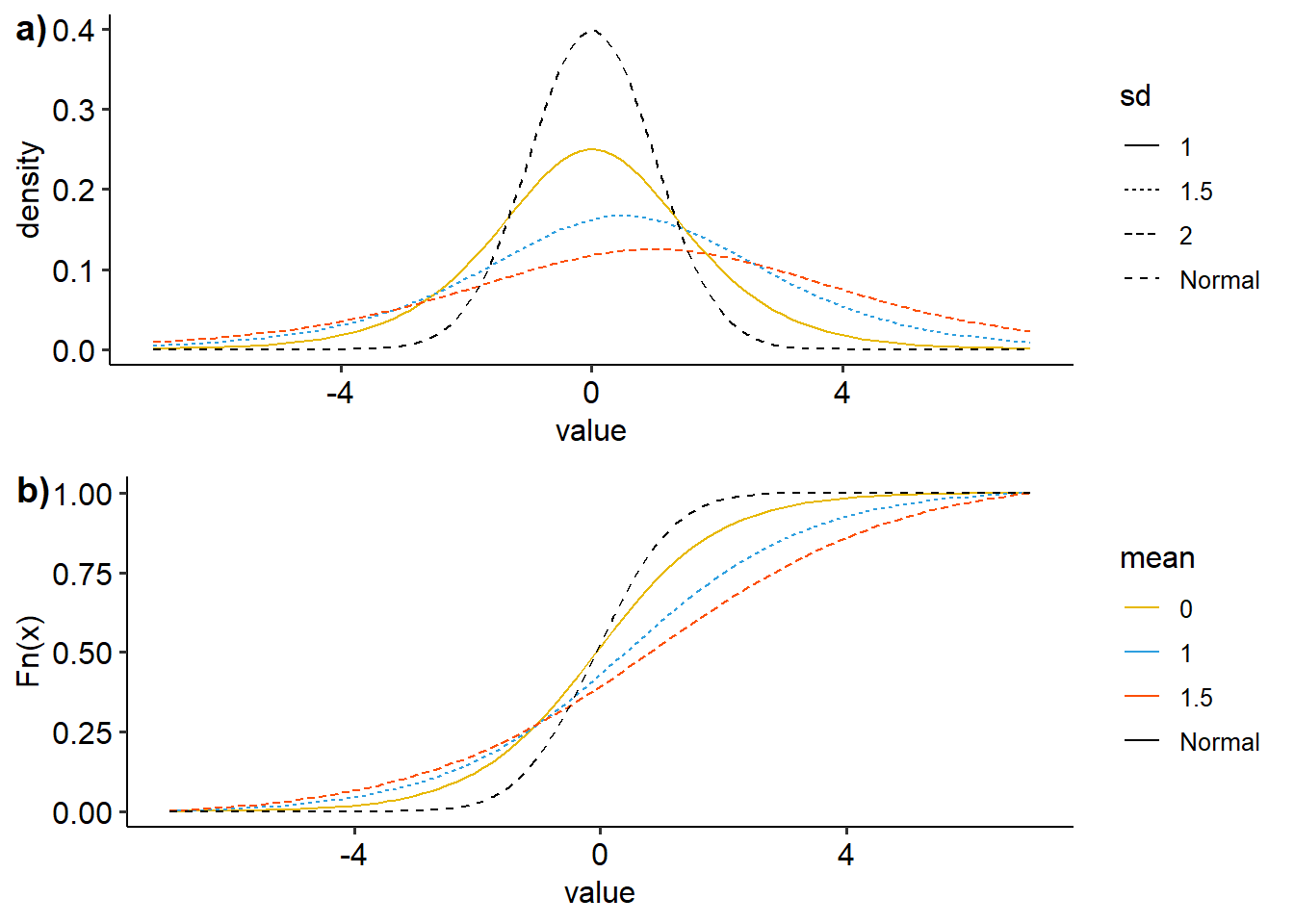
Figure 18: Visualisasi distribusi logistik dengan variasi mean dan simpangan baku, a) density plot, b)ecdf
Pada R, fungsi utama yang digunakan untuk menghitung probabilitas distribusi Logistik adalah dlogis() dan plogis() (probabilitas kumulatif). Format fungsi tersebut adalah sebagai berikut:
dlogis(x, location = 0, scale = 1)
plogis(q, location = 0, scale = 1, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil.
- location: mean.
- scale: simpangan baku
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
9.10.5 Distribusi Weibull
Distribusi lain yang digunakan secara intensif selain distribusi gamma dan eksponensial untuk memperkirakan probabilitas kegagalan suatu proses adalah distribusi Weibull. Fungsi densitas probabilitas distribusi Weibull disajikan pada Persamaan (39).
\[\begin{equation} f\left(x;\alpha,\beta \right) = \begin{cases} f\left(x;\alpha,\beta\right)=\frac{\alpha}{\beta}\left(\frac{x}{\beta}\right)^{\alpha-1}\exp\left(\frac{x}{\beta}\right)^{\alpha} & \quad x>0\\ 0 & \quad\text{} \end{cases} \tag{39} \end{equation}\]Pada Gambar 19 disajikan visualisasi distribusi gamma dengan variasi \(\alpha\) dan \(\beta\).
x <- seq(0,6, length=100)
x1 <- dweibull(x, shape=1, scale=1); x1_cum <- cumsum(x1)/max(cumsum(x1))
x2 <- dweibull(x, shape=2, scale=1); x2_cum <- cumsum(x2)/max(cumsum(x2))
x3 <- dweibull(x, shape=4, scale=1); x3_cum <- cumsum(x3)/max(cumsum(x3))
data <- data.frame(value=c(x,x,x),
density=c(x1,x2,x3),
cum_dens=c(x1_cum,x2_cum,x3_cum),
alpha=gl(3,length(x1),
labels=c(1,2,4)))
dens <- ggplot(data, aes(x=value, y=density, color=alpha))+
geom_line()+
scale_color_manual(values=c("#E7B800","#2E9FDF","#FC4E07")
)
ecdf <- ggplot(data, aes(x=value, y=cum_dens, color=alpha))+
geom_line()+
labs(y="Fn(x)")+
scale_color_manual(values=c("#E7B800","#2E9FDF","#FC4E07")
)
ggarrange(dens, ecdf, nrow=1, ncol=2, labels=c("a)","b)"))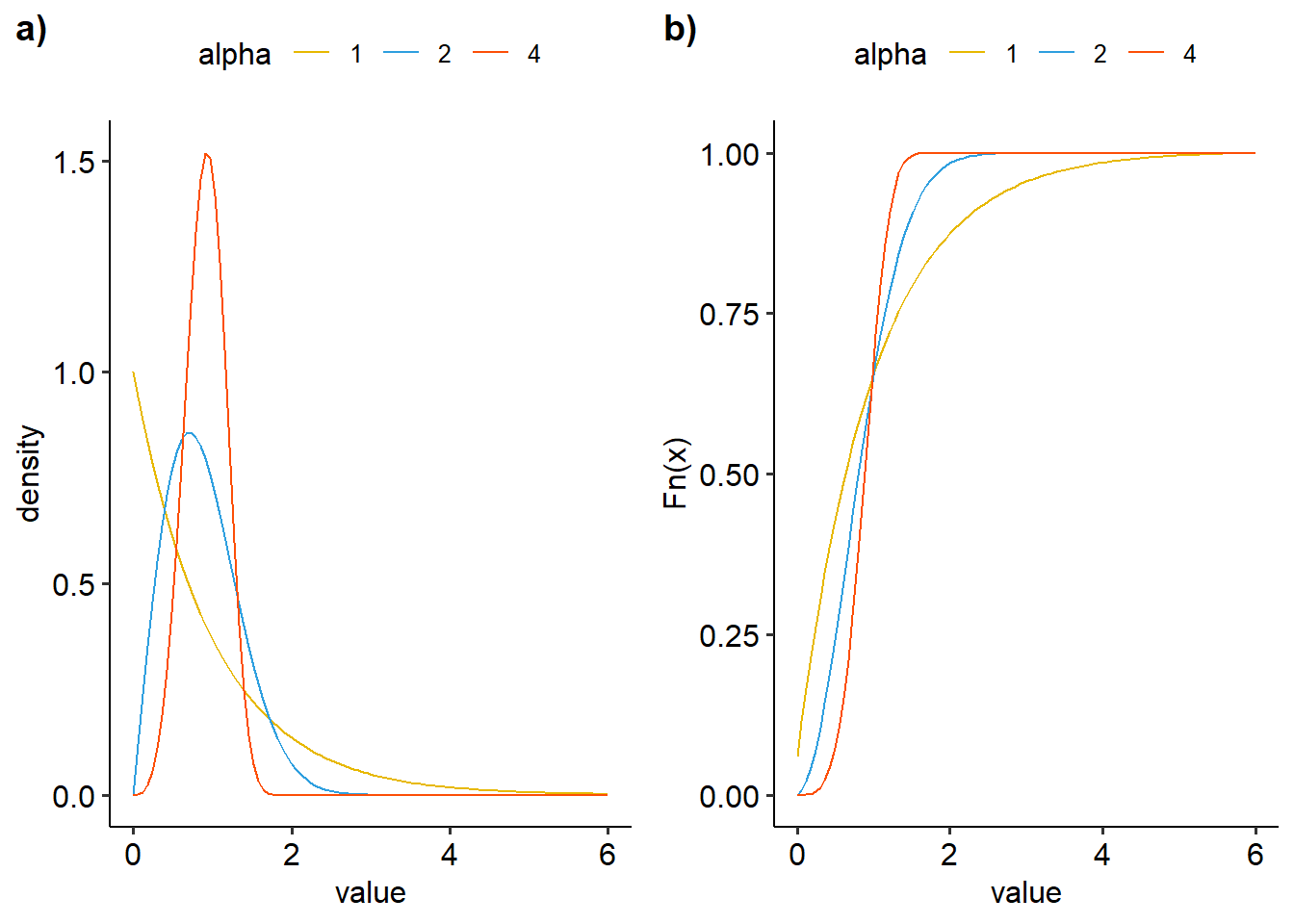
Figure 19: Visualisasi distribusi weibull dengan variasi alpha dengan beta 1 a) density plot, b)ecdf
Pada R probabilitas distribusi Weibull dapat dihitung menggunakan fungsi dweibull() dan pweibull() (probabilitas kumulatif). Format fungsi tersebut adalah sebagi berikut:
dweibull(x, shape, scale)
pweibull(q, shape, scale, lower.tail = TRUE)Note:
- x,p: vektor numerik atau kuantil
- shape: nilai alpha
- scale: niali beta
- lower.tail: probabilitas dihitung dari ujung bawah. Nilai yang mungkin adalah TRUE atau FALSE.
Referensi
- Chi Yau. 2014. R Tutorial with Bayesian Statistics Using OpenBUGS. Amazon Kindle
- Damanhuri, E. 2011. Statitika Lingkunga. Penerbit ITB.
- Janicak, C.A. 2007. Applied Statistics in Occupational Safety and Health. Government Institutes.
- Kerns, G.Jay. 2018. Introduction to Probability and Statistics Using R Third Edition. GNU Free Documentation License.
- King, William B. PROBILITY DISTRIBUTIONS, QUANTILES, CHECKS FOR NORMALITY. http://ww2.coastal.edu/kingw/statistics/R-tutorials/prob.html.
- Ofungwu, J. 2014. Statistical Applications For Environmental Analysis and Risk Assessment. John Wiley & Sons, Inc.
- Quick-R. Probability Plots . https://www.statmethods.net/advgraphs/probability.html
- STAT TREK. Binomial Probability Distribution.https://stattrek.com/probability-distributions/binomial.aspx?tutorial=prob.
- ____.Hypergeometric Distribution. https://stattrek.com/probability-distributions/hypergeometric.aspx?tutorial=prob.
- ____. Multinomial Distribution. https://stattrek.com/probability-distributions/multinomial.aspx?tutorial=prob.
- ____. Negative Binomial Distribution. https://stattrek.com/probability-distributions/negative-binomial.aspx?tutorial=prob.
- ____. Poisson Distribution. https://stattrek.com/probability-distributions/poisson.aspx?tutorial=prob.
- UBC. Probability DIstribution. https://www.zoology.ubc.ca/~schluter/R/probability/.
- Walpole, E. R., Myers, H.M., Myers, S.L., Keying Ye. 2011. Probability $ Statistics for Engineering & Scientists Ninth Edition. Prentice Hall.