Environmental Engineer sering mengumpulkan sejumlah data dari lingkungan untuk mempelajari proses yang terjadi pada sistem lingkungan dimana data tersebut berada. Sering kali mereka memiliki dugaan awal yang selanjutnya kita sebut sebagai hipotesis bagaimana suatu sistem bekerja. Tujuan pengumpulan data yang dilakukan untuk menguji apakah hipotesis yang telah terbentuk dapat dipertahankan sesuai dengan bukti-bukti yang disajikan oleh data. Uji statistik merupakan cara kuantitatif untuk menentukan apakah suatu hipotesis dapat dipertahankan atau hipotesis tersebut perlu ditolak.
Daftar Isi:
11.1 Klasifikasi Uji Hipotesis
Uji hipotesis dapat diklasifikasikan berdasarkan beberapa kriteria sebagai berikut:
11.1.1 Klasifikasi Berdasarkan Skala Pengukuran
Skala pengukuran dalam suatu data dapat berupa kategorikal atau numerikal. Suatu pengukuran dapat melakukan perbandingan antara dua buah grup (kategori) berdasarkan data kontinu yang dimiliki masing-masing grup. Uji hipotesis yang digunakan adalah uji perbandingan dua populasi. Jika terdapat lebih dari dua populasi maka uji yang digunakan adalah uji anova.
Contoh lainnya misalkan kita memiliki dua buah data dengan skala kontinu. Kita ingin mengetahui korelasi antara dua variabel tersebut, maka uji hipotesis yang digunakan adalah uji korelasi.
Bagaimana jika skala pengukuran data kita seluruhnya kategorikal? jika skala pengukuran data kita seluruhnya adalah kategori, kita perlu membuat tabel kontingensi yang mengukur frekuensi kejadian pada masing-masing grup atau antara satu gruo terhadap grup yang lain. Uji hipotesis yang digunakan adalah uji asosiasi.
Pada Chapter ini kita hanya akan membahas uji hipotesis yang digunakan pada satu populasi. Uji hipotesis lain seperti uji hipotesis untuk 2 populasi, anova, korelasi dan asosiasi akan dibahas pada Chapter lainnya.
11.1.2 Klasifikasi Berdasarkan Distribusi Data
Uji hipotesis yang melibatkan sejumlah asumsi seperti ditribusi data mengikuti distribusi tertentu (biasanya ditribusi normal) disebut sebagai uji hipotesis parametrik. Dinamakan uji parametrik karena uji ini melibatkan parameter-parameter yang ada pada data seperti nilai mean dan simpangan baku. Uji ini sangat bagus digunakan jika data kita benar-benar mengikuti asumsi ditribusi yang diinginkan. Jika tidak maka hasil uji yang diperoleh dapat menghasilkan keputusan yang salah. Hal ini disebabkan karena uji ini memiliki sensitifitas yang rendah (power) untuk mendeteksi efek nyata.
Alternatif lain yang dapat digunakan untuk melakukan uji hipotesis adalah dengan melakukan uji hipotesis nonparameterik. Uji ini tidak mengasumsikan data mengikuti distribusi tertentu. Informasi pada uji ini diperoleh dengan melakukan rangking pada data. Hal ini tentu berbeda dengan uji parametrik yang mengharuskan kita mengekstrak parameter pada data. Kesalahpahaman yang umum adalah pada uji nonparametrik memungkinkan terjadinya kehilangan informasi dibandingkan dengan tes parametrik karena tes nonparametrik membuang nilai data. Bradley (1968) dalam bukunya “Distribution-Free Statistical Tests” menanggapi kesalahpahaman ini: “Sebenarnya, pemanfaatan informasi sampel tambahan [dalam parameter] dimungkinkan oleh informasi populasi tambahan yang terkandung dalam asumsi uji parametrik. Oleh karena itu, uji bebas distribusi hanya membuang informasi hanya jika pada uji parametrik asumsi diketahui benar (data mengikuti distribusi tertentu).” Alih-alih membuang informasi, tes nonparametrik secara efisien mengekstraksi informasi pada besaran relatif (rangking) data tanpa menciutkan informasi menjadi hanya beberapa statistik sederhana.
11.2 Menyiapkan Prosedur UJi Hipotesis
11.2.1 Memilih Uji yang Sesuai
Prosedur uji dipilih berdasarkan karakteristik data dan tujuan studi. Kriteria pertama untuk memilih uji statistik yang sesuai adalah dengan melihat skala pengukuran pada data. Kita telah membahas ini pada klasifikasi uji berdasarkan skala pengukuran data.
Kriteria kedua yang digunakan adalah tujuan dari pengujian. Uji hipotesis yang tersedia dapat digunakan untuk melihat beda antara dua nilai sentral dua grup, tiga atau lebih grup, sebaran data antar grup, kovariansi antara dua atau lebi variabel antara satu sama lain.
Kriteria ketiga yang digunakan adalah memilih apakah akan melakukan uji parameterik atau nonparameterik. Pemilihan berdasarkan kriteria ini perlu melihat asumsi distribusi uji statististik apakah telah terpenuhi atau belum. Jika suatu data berdistribusi normal maka uji parametrik akan lebih dipilih, jika sebaliknya atau distribusi data tidak mengikuti distribusi tertentu maka uji yang digunakan adalah uji nonparametrik. Power dar uji parametrik untuk menolah hipotesis nol ketika hipotesis nol salah dapat sangat rendah jika digunakan pada data yang tidak berdistribusi normal. Selain itu, error tipe II biasanya juga terjadi pada uji parametrikpada data dengan distribusi tidak normal.
Transformasi data sering digunakan agar distribusi data mendekati distribusi normal. Jenis tranformasi akan berbeda pada setiap data sehingga proses transformasi akan mencoba pada berbagai format. Kendala yang timbul pada proses ini adalah jika kita akan melakukan uji pada dua atau lebih grup data. Jenis transformasi pada satu grup data bisa saja tidak berlaku untuk grup data lainnya. Jika kita paksakan transformasi ynag berbeda-beda pada tiap grup, maka pembacaan hasil yang diperoleh akan lebih sulit. Hal ini tidak terjadi jika sejak awal data yang tidak mengikuti distribusi normal dilakukan uji nonparametrik.
Untuk mempermudah proses pemilihan uji yang sesuai, Gardener (2012) membuat skema pemilihan uji hipotesis yang disajikan pada Gambar 1
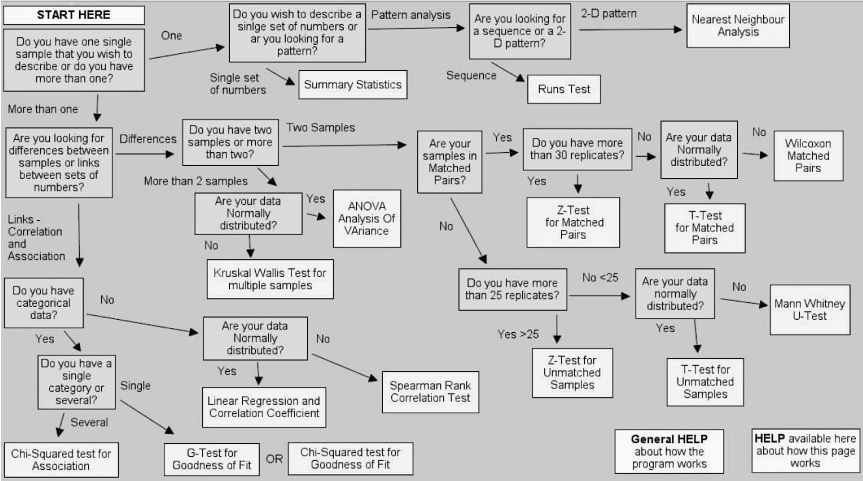
Figure 1: Skema pemilihan uji hipotesis (sumber: Gradener, 2012).
11.2.2 Hipotesis Nol dan Alternatif
Uji hipotesis akan melakukan perbandingan antara dua buah hipotesis, hipotesis nol (\(H_0\)) dan hipotesis alternatif (\(H_a\)). Desain \(H_0\) dan \(H_a\) yang benar merupakan tahapan yang paling penting sebab prosedur uji hipotesis didesain untuk cenderung memilih hipotesis nol, sehingga \(H_0\) tidak akan ditolak kecuali terdapat bukti kuat untuk menolaknya berdasarkan data yang kita miliki. Analogi ini mirip dengan istilah “praduga tak bersalah”, dimana tersangka akan dianggap tidak bersalah kecuali terbukti sebaliknya berdasarkan bukti-bukti persidangan.
Impilkasi dari kondisi yang telah dijelaskan di atas adalah ketika \(H_0\) diterima, kita tidak bisa menyatakan bahwa hipotesis tersebut benar. Hal yang tepat pada kondisi tersebut adalah tidak ada bukti yang cukup kuat pada data untuk menolaknya. Untuk memahaminya kita akan menggunakan contoh prosedur uji berbasis rentang kepercayaan (confidence interval) yang menolak \(H_0:\mu=\mu_0\) jika \(\mu_0\) tidak berada pada rentang kepercayaan \(\mu\) (lihat lagi pada Chapter 10). Karena setiap nilai dalam rentang kepercayaan adalah kandidat yang masuk akal (diberikan pada set data) untuk nilai parameter sebenarnya, jelas bahwa dengan tidak menolak \(H_0:\mu=\mu_0\), kita belum membuktikan bahwa \(H_0\) benar. Prosedur pengujian memberikan bukti statistik hanya ketika H0 ditolak. Dalam hal ini dapat diklaim bahwa alternatif telah dibuktikan (dalam arti statistik) pada tingkat signifikansi \(\alpha\). Tingkat signifikansi mengkuantifikasi keraguan wajar yang bersedia kita terima ketika menolak hipotesis nol.
Berdasarkan pembahasan di atas dapat disimpulkan bahwa pernyataan yang perlu dibuktikan secara statistika disebut sebagai \(H_a\). Penyataan pelengkapnya disebut sebagai \(H_0\) atau peryataan yang dianggap benar kecuali terbukti sebaliknya. Hal terpenting dalam desain \(H_0\) adalah perlunya penggunaan equality sign (=, \(\le\), atau \(\ge\)) sebagai bagian dari desain \(H_0\).
Untuk memahaminya misalkan diinginkan pengujian hipotesis bahwa rata-rata populasi adalah 100. Buatlah format hipotesis yang digunakan jika hipotesis alternatifnya menginginkan nilai rata-rata yang lebih besar?. Berdasarkan kondisi tersebut maka format hipotesisnya adalah sebagai berikut.
\(H_0\): \(\mu=100\)
\(H_a\): \(\mu > 100\)
11.2.3 Statistik Uji dan Aturan Penolakan
Pada uji statistik terdapat dua buah nilai yang penting untuk diketahui yaitu nilai statistik uji dan aturan penolakan. Uji statistik yang digunakan untuk menguji \(H_0\) terkait parameter \(\mu\) dapat didasarkan pada titik estimasi \(\hat\mu\) dari \(\mu\). Aturan penolakan menentukan kapan \(H_0\) harus ditolak. Pada dasarnya \(H_0\) ditolak ketika nilai uji statistik berada pada sejumlah rentang (lebih besar, atau lebih kecil, atau keduanya tergantung pada \(H_a\)) yang menyatakan bahwa pada nilai tersebut tidak mungkin jika \(H_0\) benar.
Menggunakan contoh kasus sebelumnya dimana kita kan menguji \(H_0\): \(\mu=100\). \(H_0\) ditolak jika nilai statistik uji lebih kecil sama dengan 100 atau \(H_a\le C_1\) sebagai contoh nilai statistik ujinya adalah 90,80, dst. Bagaimana jika hipotesis ujinya \(H_a\): \(\mu \le 100\)?. Sama dengan sebelumnya maka penolakan \(H_0\) terjadi jika nilai uji statistiknya \(H_a>C_2\) seperti 110, 120, dst. Kondisi lain yang dapat juga diterapkan jika \(H_a\): \(\mu \neq 100\), maka \(H_0\) ditolak jika nilai statistik ujinya adalah \(H_a<C_3\) atau \(H_a>C_4\)
Bagaimana cara tepat untuk memilih menggunakan nilai konstanta \(C_1\), \(C_2\), \(C_3\), atau \(C_4\)? jawabannya adalah dengan menggunakan tingkat signifikansinya atau error (tingkat kesalahan). Tingkat signifikansi didefinisikan sebagai probabilitas (terbesar) untuk menolak \(H_0\) secara tidak benar, atau, dengan kata lain, probabilitas (terbesar) untuk menolak \(H_0\) ketika \(H_0\) benar.
Seperti yang telah disebutkan, tingkat signifikansi menentukan risiko (atau, dalam hal legalistik, keraguan yang masuk akal) kita bersedia menerima kesalahan karena menyimpulkan bahwa \(H_0\) salah. Ternyata konstanta \(C_1\) dan \(C_2\) dapat ditentukan dengan menentukan tingkat signifikansi.
11.2.3.1 Probabilitas Error Tipe I
Terdapat dua buah error yang terjadi pada saat pengambilan keputusan. Secara sederhana penulis akan menjelaskan error tersebut dengan menggunakan contoh pemberian vaksin kepada pasien. Vaksin baru tersebut tidak lebih baik atau sama kualitasnya dengan vaksin yang telah ada sebelumnya (\(H_0\) benar). Sebagai data pendukung, pengujian telah dilakukan dengan memilih individu secara acak, dimana 8 individu melewati 2 tahun tanpa tertular virus. Kita akan melakukan kesalahan dengan menolak \(H_0\) dan mendukung \(H_a\) (vaksin lebih baik) sedangkan kenyataannya \(H_0\) benar. Error yang disebabkan oleh penolakan \(H_0\) padahal \(H_0\) benar disebut sebagai error tipe I.
Jenis error kedua dapat terjadi jika 8 individu atau kurang melewati dua tahun periode penggunaan vaksin secara sukses, namun kita tidak dapat menyimpulkan bahwa vaksin tersebut lebih baik meskipun pada kenyataannya demikian (\(H_a\) benar). Sehingga pada kasus ini kita gagal menolak \(H_0\) meskipun kenyataannya \(H_0\) salah. Kondisi dimana kita tidak menolak \(H_0\) meskipun \(H_0\) salah disebut sebagai error tipe II.
Dalam menguji hipotesis statistik apa pun, ada empat kemungkinan situasi yang menentukan apakah keputusan kita benar atau salah. Keempat kemungkinan tersebut disajikan pada Tabel 1:
| \(H_0\) Benar | \(H_0\) Salah | |
|---|---|---|
| Terima \(H_0\) | Keputusan benar | Error tipe II |
| Tolak \(H_0\) | Error tipe I | Keputusan benar |
Peluang untuk melakukan error tipe I disebut sebagai tingkat signifikansi, dilambangkan dengan huruf Yunani \(\alpha\). Dalam kondisi di atas kesalahan tipe satu terjadi ketika lebih dari 8 orang dari 20 orang yang diinokulasi dengan vaksin baru melampaui periode 2 tahun tanpa tertular virus dan peneliti menyimpulkan bahwa vaksin baru lebih baik padahal kenyataannya setara dengan vaksin yang sudah ada. Oleh karena itu, jika \(X\) adalah jumlah orang yang tetap bebas dari virus selama minimal 2 tahun dengan probabilitas sukses \(p=0,25\), maka probabilitas error tipe satu adalah sebagai berikut:
\[ \alpha=P\left(error\ tipe\ I\right)=P\left(X>8\ ketika\ p=\frac{1}{4}\right)=\sum_{x=9}^{20}b\left(x;20,\frac{1}{4}\right) \]
\[ \alpha=1-\sum_{x=0}^8b\left(x;20,\frac{1}{4}\right)=1-0,9591=0,0409 \]
Kita dapat mengatakan bahwa hipotesis nol dengan probabilitas kejadian sukses sebesar \(p=0,25\) telah teruji dengan tingkat signifikansi \(\alpha=0,0409\). Nilai yang dihasilkan sangat kecil, sehingga error tipe I kemungkinan tidak terjadi. Akibatnya, akan lebih tidak biasa bagi lebih dari 8 orang untuk tetap kebal terhadap virus selama periode 2 tahun menggunakan vaksin baru yang pada dasarnya setara dengan yang sekarang ada di pasaran.
11.2.3.2 Probabilitas Error Tipe II
Probabilitas terjadinya error tipe II disimbolkan dengan \(\beta\). Error tipe II sulit untuk dihitung kecuali kita memiliki hipotesis alternatif. Pada contoh kali ini kita akan menguji hipotesis nol dengan nilai \(p=0,25\) melawan hipotesis alternatif dengan \(p=0,5\), sehingga kita dapat melakukan perhitungan probabilitas untuk tidak menolak \(H_0\) meskipun \(H_0\) salah. Kita selanjutnya dapat menghitung probabilitas 8 individu atau kurang yang melampaui periode 2 tahun ketika nilai \(p=0,5\).
\[ \beta =P\left(error\ tipe\ II\right)=P\left(X\le 8\ ketika\ p=\frac{1}{2}\right) \]
\[ \beta=\sum_{x-0}^8b\left(x;20,\frac{1}{2}\right)=0,2517 \]
Berdasarkan hasil perhitungan diperoleh nilai probabilitas yang relatif tinggi. Hal ini mengidikasikan penolakan vaksin baru tersebut meskipun kenyataannya vaksin baru tersebut lebih superior dibandingkan vaksin yang telah ada.
Idealnya kita akan menggunakan prosedur pengujian dimana probabilitas error tipe I dan II sangat kecil. Berdasarkan berbagai text book probabilitas error tipe I dan II dapat diturunkan dengan cara meningkatkan jumlah sampel yang kita miliki.
Berdasarkan pembahasan terkait error pada pengujian hipotesis, terdapat beberapa properti penting terkait pengujian hipotesis, antara lain:
- Error tipe I dan tipe II pada pengujian hipotesis saling terkait. Penurunan salah satu akan meningkatkan error lainnya.
- Ukuran wilayah kritis dan probabilitas melakukan error tipe I selalu dapat dikurangi dengan menyesuaikan nilai kritis (meningkatkan atau menurunkan tingkat signifikansi).
- Peningkatan ukuran sampel akan menurunkan nilai \(\alpha\) dan \(\beta\) secara simultan.
- Jika hipotesis nol salah, nilai \(\beta\) akan maksimum ketika nilai sebenarnya dari suatu parameter mendekati nilai yang sebenarnya. Semakin besar jarak antara nilai sebenarnya dengan nilai yang dihipotesiskan maka semakin kecil nilai \(\beta\).
11.2.4 P-Value
P-value merupakan probabilitas untuk memperoleh statistik uji yang dihitung, atau yang lebih kecil kemungkinannya, ketika hipotesis nolnya benar. P-value mengukur “kepercayaan” dari hipotesis nol. Semakin kecil p-value, semakin kecil kemungkinan statistik uji kemungkinan statistik uji yang diamati ketika \(H_0\) benar, dan semaikn kuat bukti penolakan \(H_0\). P-value disebut juga sebagai tingkat signifikansi yang dicapai oleh data.
Bagaimana bisa p-value berbeda dengan \(\alpha\)-level?. \(\alpha\)-level tidak bergantung pada data, tapi telah ditetapkan sebagai suatu resiko untuk melakukan error tipe I yang dapat diterima. \(\alpha\)-level merupakan nilai kritis yang memungkinkan sebuah keputusan “ya/tidak” dibuat. P-value menyediakan informasi lebih sepeti bukti kuat secara scientific. Penggunaan p-value memungkinkan seseorang dengan toleransi resiko berbeda-beda (\(\alpha\) berbeda) untuk membuat keputusannya sendiri.
11.2.5 Membuat Keputusan Untuk Menolak Hipotesis Nol atau Tidak
Ketika p-value lebih kecil dari \(\alpha\)-level, maka \(H_0\) ditolak. Sebaliknya jika p-value lebih besar dari \(\alpha\), maka \(H_0\) diterima. Telah dijelaskan sebelumnya bahwa penerimaan hipotesis nol tidak berarti \(H_0\) pasti benar. \(H_0\) siasumsikan benar sampai terbukti sebaliknya dan tidak ditolak sampai dengan terdapat bukti yang cukup kuat untuk menolaknya.
11.3 Uji Nilai Rata-Rata Sampel Tunggal
Pada bagian ini penulis akan menjelaskan prosedur uji hipotesis untuk satu populasi. Sebelum pembahasan dilakukan pembaca perlu mengingat bahwa uji ini sangat berkaitan dengan perhitungan interval kepercayaan yang telah kita bahas pada Chapter sebelumnya. Jika sebelumnya kita menghitung nilai mean suatu observasi pada selang tertentu, pada bagian ini kita akan membahas bagaimana menguji suatu rata-rata apakah berasal dari suatu populasi atau tidak berdasarkan p-value.
Prosedur uji hipotesis untuk satu populasi yang akan penulis bahas kali ini akan bergantung pada berbagai kondisi. Kondisi yang menjadi pertimbangan antara lain:
- Apakah sampel berdistribusi normal?
- Apakah jumlah sampel besar atau kecil?
Untuk mempermudahnya, pada Gambar 2 penulis sajikan skema pemilihan uji hipotesis untuk satu sampel.
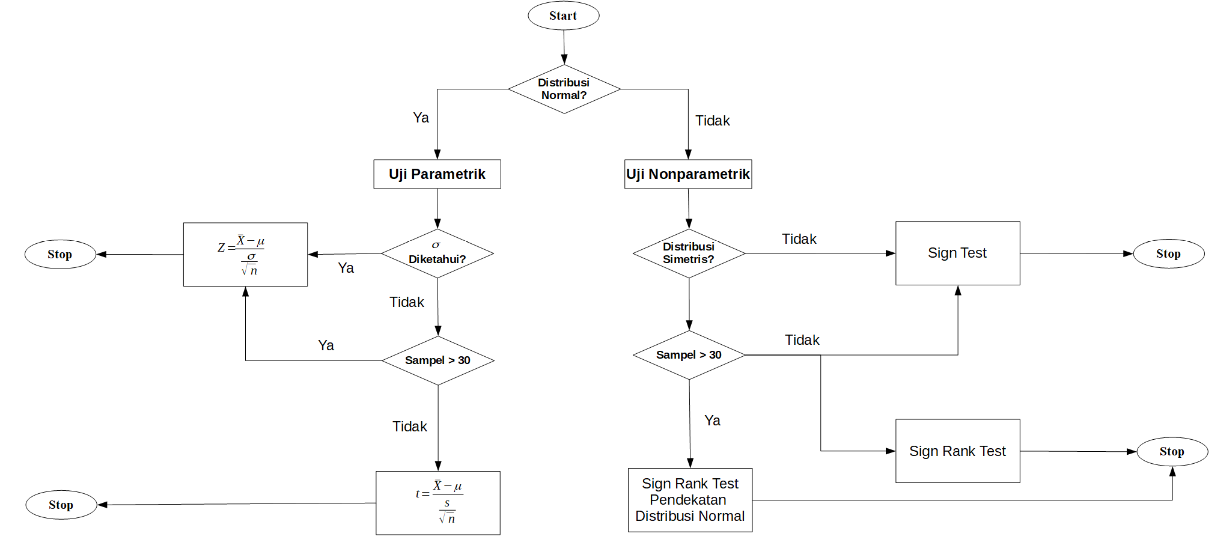
Figure 2: Skema pemilihan uji hipotesis untuk satu populasi.
11.3.1 Uji Parametrik
Pada uji parametrik asumsi normalitas distribusi sampel menjadi sesuatu yang penting agar hasil yang diperoleh valid. Pada uji satu populasi untuk uji parametrik terdapat dua pertimbangan dalam pemilihan metode uji yaitu varians populasi serta ukuran sampel.
Jika varians populasi diketahui maka kita dapat menggunakan pendekatan distribusi normal. Jika simpangan baku populasi (\(\sigma\)) tidak diketahui serta jumlah sampel kecil maka pendekatan dilakukan menggunakan distribusi t. Kondisi lain yang perlu dipertimbangkan adalah saat sampel yang kita miliki besar, namun simpangan baku populasi tidak diketahui. Hal ini merupakan kondisi yang banyak ditemukan di lingkungan. Beberapa textbook menjelaskan bahwa uji satu sampel untuk kondisi tersebut dapat menggunakan pendekatan distribusi normal sehingga simpangan baku populasi didekati dengan simpangan baku sampel (\(s\)). Hal ini sesuai dengan teori limit pusat dimana semakin besar ukuran sampel, maka nilai statistik sampel (mean dan simpangan baku) akan mendekati populasinya. Berikut adalah prosedur dalam melakukan uji hipotesisnya:
Prosedur Uji Hipotesis
- Asumsi : Distribusi normal
- Hipotesis nol (\(H_0\)) : \(\mu=\mu_0\)
- Statistik Uji:
- Aturan penolakan (RR) berdasarkan variasi \(H_a\)
Aturan penolakan berdasarkan variasi \(H_a\) dan pendekatan distribusi yang digunakan disajikan pada Tabel 2.
Formula p-value
Distribusi Normal
- Distribusi t
dimana \(G_{n-1}\) adalah CDF (fungsi densitas kumulatif) dari distribusi t.
| \(H_a\) | RR pada level \(\alpha\) (Distribusi Normal) | RR pada level \(\alpha\) (Distribusi t) |
|---|---|---|
| \(\mu>\mu_0\) | \(Z_{H_0}\ge Z_\alpha\) | \(T_{H_0}>t_{n-1,\alpha}\) |
\(\mu<\mu_0\) | \(Z_{H_0}\le -Z_\alpha\) | \(T_{H_0}< -t_{n-1,\alpha}\) | \(\mu\neq\mu_0\) | \(Z_{\frac{\alpha}{2}}\le Z_{H_0}\le Z_{\frac{\alpha}{2}}\) | \(-t_{n-1,\frac{\alpha}{2}}<T_{H_0}< t_{n-1,\frac{\alpha}{2}}\) |
: (#tab:stha) Aturan penolakan berdasakan hipotesis alternatif.
Uji Hipotesis Menggunakan R
- Distribusi Normal
Untuk menghitung p-value pada distribusi normal kita dapat menggunakan fungsi pnorm() (probabilitas kumulatif). Berikut adalah sintaks yang digunakan:
# uji satu sisi
1-pnorm(((x/n)-mu)/(sd/sqrt(n)))
pnorm(((x/n)-mu)/(sd/sqrt(n)))
# uji dua sisi
2*(1-pnorm(abs(((x/n)-mu)/(sd/sqrt(n)))))Note:
- x/n: rata-rata sampel
- mu: rata-rata populasi
- sd: simpangan baku
- n: ukuran sampel
- Distribusi t
Pada uji hipotesis menggunakan distribusi t, fungsi yang digunakan sudah tersedia pada R. Fungsi yang digunakan adalah t.test(). Berikut adalah format fungsi yang digunakan:
t.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE,
conf.level = 0.95, ...)Note:
- x,y: vektor numerik. Kedua argumen akan terisi jika akan dilakukan uji hipotesis untuk dua populasi.
- alternative: diguanakan untuk menentukan jenis uji hipotesis apakah satu sisi(“less” dan “greater”), atau dua sisi (“two.sided”).
- mu: rata-rata populasi. Secara default nilainya
0- paired: vektor logikal yang menentukan apakah uji dua populasi digunakan untuk sampel berpasangan (
TRUE) atau tidak (FALSE).- conf.level: tingkat kepercayaan. Secara default tingkat kepercayaan yang digunakan adalah
95%.
Example 1 (Varian populasi diketahui) Suatu produk kompos dalam kantong berisi rata-rata 16 kg per kantong, dengan simpangan baku=0,2 kg. Bila berat tersebut secara signifikan lebih kecil, maka toko penyalur berhak untuk menolak. Untuk mengujinya diambil sampel secara acak sebanyak 36 kantong, kemudian ditimbang, dan berat rata-rata yang diperoleh sebesar 15,7 kg. Dengan menggunakan \(\alpha=0,01\) tentukan apakah berat rata-rata sampel lebih kecil dari berat seharusnya dengan asumsi distribusi yang terbentuk adalah distribusi normal?
Jawab:
\[ Hipotesis \begin{cases} H_0:\mu=16kg\\ H_a:\mu<16kg \end{cases} \]
dengan \(n>30\) dan \(\sigma\) diketahui, maka digunakan distribusi normal. Nilai Z untuk \(\alpha=0,01\) adalah \(-2,33\) dengan daerah penolakan berada pada rentang \(Z_{H_0}\le -Z_\alpha\).
Statistik uji diperoleh berdasarkan Persamaan (1).
\[ Z_{H_0}=\frac{15,7-16}{\frac{0,2}{\sqrt{36}}}=-9,00 \]
Nilai p-value selanjutnya dapat dihitung menggunakan Persamaan (3).
\[ \Phi\left(Z_{-9}\right)=1.128588e-19 \]
Pada R p-value dapat dihitung menggunakan sintaks berikut:
pnorm(((15.7)-16)/(0.2/sqrt(36)))## [1] 1.128588e-19Kesimpulan: p-value < \(\alpha\), atau \(H_0\) ditolak. Berat rata-rata sampel < 16 kg (di bawah standard) sehingga diperlukan pembenahan dalam penimbangan kompos ke kantongnya agar sesuai standard.
Example 2 (Varians populasi tidak diketahui) Menurut seorang pengusaha industri, unit pengolah limbahnya mengeluarkan effluent dengan parameter BOD rata-rata harian sebesar 17 mg/l. Untuk itu dilakukan sampling komposit selama 7 hari berturut-turut, dan ternyata rerata BOD sampelnya adalah 19 mg/l, dengan simpangan baku 4 mg/l. Bila fenomena tersebut berdistribusi normal, lakukan pengujian dengan tingkat keyakinan \(\alpha=0,01\)?
Jawab:
\[ Hipotesis \begin{cases} H_0:\mu=17kg\\ H_a:\mu\ne17kg \end{cases} \]
dengan \(n\le30\) dan \(\sigma\) tidak diketahui maka pengujian dilakukan dengan menggunakan distribusi t. Daerah penerimaan \(H_0\) untuk \(\alpha=0,01\) dan \(df=7-1=6\) berada pada rentang \(-3,143<T{H_0}<3,143\).
Statistik uji dihitung menggunakan Persamaan (2).
\[ T_{H_0}=\frac{19-17}{\frac{4}{\sqrt{7}}}=1,322876 \]
p-value selanjutnya dapat dihitung menggunakan Persamaan (4).
\[ 2\left[1-G_{6}\left|T_{1,323}\right|\right]=0,2340573 \]
p-value pada R dapat dihitung menggunakan fungsi pt() (fungsi densitas kumulatif). Berikut adalah sintaks yang digunakan:
2*(1-pt(1.322876, df=6))## [1] 0.2340573# atau
set.seed(48)
t.test(x=rnorm(n=7, mean=19, sd=4),
mu=17,alternative="two.sided",
conf.level=0.99)##
## One Sample t-test
##
## data: rnorm(n = 7, mean = 19, sd = 4)
## t = 1.1742, df = 6, p-value = 0.2848
## alternative hypothesis: true mean is not equal to 17
## 99 percent confidence interval:
## 10.97128 28.61775
## sample estimates:
## mean of x
## 19.79452Kesimpulan: p-value > \(\alpha\). Terima \(H_0\). Pernyataan pengusaha tersebut dapat diterima.
Berdasarkan hasil perhitungan di atas penulis menggunakan dua cara yaitu dengan menggunakan fungsi pt() dan t.test(). Pada fungsi t.test() penulis perlu mereproduksi kembali data berdasarkan nilai mean dan simpangan baku yang ada. Hal ini tentu berbeda dengan cara satunya, namun kelebihan cara ini kita bisa melakukan uji hipotesis sekaligus menghitung rentang keyakinan dari sampel. Hasil yang diperoleh juga tidak berbeda antara kedua cara tersebut, sehingga pembaca bebas untuk menggunakan salah satunya.
11.3.2 Uji Nonparametrik
Uji nonparametrik tidak memerlukan asumsi sampel untuk mengikuti distribusi tertentu. Untuk uji hipotesis satu populasi terdapat dua macam uji nonparametrik, yaitu: sign test dan signed-rank test. Kedua uji tersebut menggunakan nilai median sebagai nilai pemusatan data (data tidak berdistribusi normal).
11.3.2.1 Sign Test
Sign test digunakan untuk menguji hipotesis terhadap nilai median populasi. Uji ini sangat cocok digunakan untuk sampel yang kecil dengan ukuran sampel \(n<30\).
Pada uji sign test, nilai sampel yang selisihnya positif akan diganti nilainya dengan tanda “+”, Sedangkan jika hasilnya negatif nilainya diganti dengan “-”. Jika hipotesis nol benar (\(H_0:\tilde{\mu}=\tilde{\mu_0}\)) dan populasi simetris, maka jumlah tanda positif dan tanda negatif akan sama. Ketika salah satu tanda muncul lebih sering, maka kita dapat menolak \(H_0\).
Secara teorotis, sign test dapat diaplikasikan hanya pada situasi dimana \(\tilde{\mu_0}\) tidak sama dengan nilai observasi yang ada (selisih median terhadap observasi tidak menghasilkan angka nol). Meskipun terdapat nol peluang untuk memperoleh sampel dengan nilai tepat sama dengan \(\tilde{\mu_0}\) ketika distribusi populasinya berasal dari distribusi kontinu. Pada kondisi aktual nilai sampel sama dengan \(\tilde{\mu_0}\) berasal dari kurang presisinya proses pengukuran data. Jika memang benar diketahui nilai sampel sama dengan \(\tilde{\mu_0}\), maka nilai tersebut selanjutnya akan dikecualikan pada proses perhitungan.
p-value pada sign test dihitung menggunakan menggunakan distribusi binomial, dimana kejadian sukses didefinisikan sebagai jumlah observasi dengan tanda “+” dengan probabilitas sukses \(p=0,5\). Pembaca dapat membuka kembali Chapter yang membahas mengenai distribusi probabilitas binomial untuk memahami cara perhitungannya.
Prosedur Uji Hipotesis
- Asumsi : jumlah sampel \(n<30\)
- Hipotesis nol (\(H_0\)) : \(\tilde{\mu}=\tilde{\mu_0}\)
- Hipotesis nol terkonversi: \(H_0:p=0,5\), dimana p merupakan probabilitas observasi \(>\tilde{\mu_0}\).
- Sign Statistic: Y = # observasi yang \(>\tilde{\mu_0}\)
- Hipotesis alternatif terkonversi
| \(H_a\) untuk \(\tilde{\mu}\) | \(H_a\) untuk \(p\) |
|---|---|
| \(\tilde{\mu}>\tilde{\mu_0}\) | \(p>0,5\) |
| \(\tilde{\mu}<\tilde{\mu_0}\) | \(p<0,5\) |
| \(\tilde{\mu}\ne\tilde{\mu_0}\) | \(p\ne0,5\) |
| \(H_a\) | RR pada level \(\alpha\) |
|---|---|
| \(\tilde{\mu}> \tilde{\mu_0}\) | \(Z_{H_0}\ge Z_\alpha\) |
| \(\tilde{\mu}< \tilde{\mu_0}\) | \(Z_{H_0}\le -Z_\alpha\) |
| \(\tilde{\mu}\ne\tilde{\mu_0}\) | $ |
Statistik Uji
- \(n<10\): Fungsi densitas kumulatif distribusi binomial. Lihat tabel distribusi binomial untuk \(p=0,5\).
\(n\ge10\):
dimana \(X\) merupakan jumlah observasi bertanda “+”. \(p\) merupakan probabilitas kejadian sukses, dimana \(p=q=0,5\). \(n\) merupakan jumlah observasi.
p-value
\(n<10\)
- \(n\ge10\)
Example 3 Nilai di bawah ini merupakan waktu yang diperlukan untuk menyisihkan suatu polutan di air sebesar 70% melalui proses sedimentasi pada percobaan di laboratorium:
1,1; 2,2; 0,9; 1,3; 2,0; 1,6; 1,8; 1,5; 2,0; 1,2; 1,7.
Gunakan sign test untuk mengecek apakah median dari hasil tersebut sesuai sama dengan yang dihasilkan penelitian sebelumnya sebesar 1,8 jam? Gunakan tingkat keyakinan 0,05 pendekatan distribusi binomial dan normal untuk kasus tersebut.
Jawab:
- \(H_0:\tilde{\mu}=1,8\)
- \(H_a:\tilde{\mu}\ne1,8\)
- \(\alpha=0,05\)
- Uji statistik: Binomial variabel X dengan p=0,5.
- perhitungan statistik uji:
Gnatilah tiap selisih nilai observasi terhadap median 1,8. Jika nilai selisih lebih besar dari median maka ganti dengan tanda “+”, sedangkan jika lebih kecil ganti dengan tanda “-”. Jika nilai nol yang dihasilkan maka kecualikan observasi tersebut. Berikut adalah hasil yang diperoleh:
\[ - + - - + - - + - - \]
Berdassarkan hasil tersebut diperoleh jumlah kejadian sukses (nilai positif) \(x=3\) dan \(n=10\) (satu observasi nol dikecualikan).
Pendekatan Distribusi Binomial
Pembaca dapat menggunakan tabel distribusi binomial untuk menghitung probabilitas binomial dengan \(n=10\), \(p=0,5\), dan \(x=3\). Berikut adalah hasil perhitungan yang dilakukan:
\[ P=2P\left(X\le3\ ketika\ p=\frac{1}{2}\right)=2\sum_{x=0}^3b\left(x;10;\frac{1}{2}\right)=0,3438>0,05 \]
Dengan menggunakan R kita dapat menggunakan fungsi pbinom() untuk menghitung probabilitas kumulatif dari distribusi binomial. Langkah pertama yang perlu dilakukan adalah membuat vektor yang berisikan observasi tersebut:
# membuat vektor numerik
df <- c(1.5, 2.2, 0.9, 1.3, 2.0,
1.6, 1.8, 1.5, 2.0, 1.2, 1.7)
# cek panjang vektor
length(df)## [1] 11Langkah selanjutnya yang perlu dilakukan adalah menghitung selisih dari elemen vektor tersebut dengan nilai median yang telah kita miliki.
# menghitung selisih nilai elemen vektor dengan median
df_new <- df-1.8
# print
df_new## [1] -0.3 0.4 -0.9 -0.5 0.2 -0.2 0.0 -0.3 0.2 -0.6 -0.1Selanjutnya menghitung nilai x (jumlah observasi bernilai positif) dan ukuran sampel yang baru (n).
# subset nilai vektor positif
df_new2 <- df_new[df_new>0]
# print
df_new2## [1] 0.4 0.2 0.2# x
x <- length(df_new2)
# n
n <- length(df_new[df_new!=0])Langkah terakhir setelah kita memperoleh nilai x dan n adalah menghitung probabilitas binomial menggunakan fungsi pbinom() dengan \(p=0,5\).
2*pbinom(q=x, size=n, prob=0.5)## [1] 0.34375Pendekatan Distribusi Normal
Untuk menghitung p-value dengan menggunakan pendekatan distribusi normal, kita perlu menghitung nilai mean dan simpangan baku dari contoh kasus di atas. Contoh kasus di atas merupakan contoh kasus percobaan binomial. Kita perlu menghitung nilai mean dan simpangan baku dari percobaan di atas. Data yang diperlukan untuk melakukannya adalah data yang telah dikonversi kedalam bentuk tanda “+” dan “-”. Berdasarkan hasil perhitungan di atas telah diketahui \(n=10\) dan \(x=3\). Berikut adalah hasil perhitungan nilai mean dan simpangan baku contoh kasus tersebut:
\[ \tilde{\mu}=np=\left(10\right)\left(0,5\right)=5 \]
\[ \sigma=\sqrt{npq}=\sqrt{\left(10\right)\left(0,5\right)\left(0,5\right)}=1,581139 \]
Setelah kedua nilai tersebut dihitung selanjutnya kita dapat menghitung nilai Z dan menggunakan tabel distribusi normal untuk menghitung p-value.
\[ Z_{H_0}=\frac{2,5-5}{1,581139}=-1,581139 \]
Sehingga nilai p-value yang diperoleh:
\[ P=2\left[\Phi\left(Z_{-1,581139}\right)\right]=0,1138463 \]
Pada R kita dapat menggunakan fungsi pnorm() untuk menghitung probabilitas kumulatif dari distribusi normal. Berikut adalah sintaks yang digunakan:
2*pnorm(q=2.5, mean=n*0.5, sd=sqrt(n*(0.5^2)))## [1] 0.1138463Kesimpulan: p-value > \(\alpha\). Terima \(H_0\). Median hasil observasi tidak berbeda signifikan dengan median hasil percobaan sebelumnya.
Berdasarkan kedua pendekatan tersebut terlihat bahwa p-value yang diperoleh berbeda hampir 2 kali lipat, namun kesimpulan yang diperoleh tidak berbeda. Pada penerapannya pembaca dapat memilih salah satu pendekatan tersebut dengan memperhatikan jumlah sampel (\(n\)) yang dimiliki oleh pembaca. Jika jumlah sampel \(n\ge10\) maka gunakan pendekatan distribusi normal.
Kita juga dapat membuat user define function kita sendiri jika suatu saat kita akan melakukan perhitungan kembali. Berikut adalah contoh sintaks yang digunakan untuk melakukan sign test:
sign.test <- function(df, median, alternative){
df_new <- df-median
x <- length(df_new[df_new>0])
n <- length(df_new[df_new!=0])
if(n<10){
if(alternative=="two.sided"){
p.value=2*pbinom(q=x, size=n, prob=0.5)
}else if(alternative=="greater"){
p.value=1-pbinom(q=x, size=n, prob=0.5)
}else if(alternative=="lower"){
p.value=pbinom(q=x, size=n, prob=0.5)
}else{
warning("You must determine the alternative")
}
}else{
if(alternative=="two.sided"){
p.value=2*pnorm(q=x-0.5, mean=n*0.5,
sd=sqrt(n*(0.5^2)))
}else if(alternative=="greater"){
p.value=0.5-pnorm(q=x-0.5, mean=n*0.5,
sd=sqrt(n*(0.5^2)))
}else if(alternative=="lower"){
p.value=pnorm(q=x-0.5, mean=n*0.5,
sd=sqrt(n*(0.5^2)))
}else{
warning("You must determine the alternative")
}
}
p.value
}Pembaca juga dapat mengedit script di atas sesuai dengan apa yang pembaca inginkan. Berikut adalah contoh output script tersebut menggunakan objek df:
sign.test(df=df, median=1.8, alternative="two.sided")## [1] 0.113846311.3.2.2 Signed-Rank Test
signed-rank test disebut juga sebagai Wilcoxon signed-rank test merupakan metode nonparameterik untuk melakukan uji median pada satu populasi dengan distribusi yang simetris. Dengan kondisi tersebut, kita dapat melakukan uji hipotesis nol (\(H_0=\tilde{\mu}=\tilde{\mu_0}\)). Langkah pertama kita perlu menguragi seluruh nilai sampel dengan \(\tilde{\mu_0}\), serta mengecualikan hasil pengurangan bernilai nol. Hasil pengurangan selanjutnya dirangking (diperingkat) tanpa memperdulikan tandanya. Rangking pertama merupakan nilai absolut terkecil dari hasil pengurangan (tanpa mempedulikan tanda), rangkin kedua merupakan absolut terkecil kedua, dst. Ketika nilai absolut hasil pengurangan memiliki nilai yang sama, maka peringkat masing-masing nilai merupakan rata-rata dari peringkat tersebut. Sebagai contoh misalnya nilai hasil pengurangan peringkat 5 dan 6 sama, maka peringkat masing-masing selanjutnya di ubah menjadi 5,5 (rata-rata kedua peringkat). Jika hipotesis nol benar, maka total rangking hasil penurangan yang positif akan sama dengan total rangkin hasil pengurangan yang negatif. Total pengurangan yang positif selanjutnya dilambangkan dengan \(w_+\) dan total pengurangan yang negatif dengan \(w_-\). Nilai terkecil dari kedua nilai tersebut dilambangkan dengan \(w\).
Dalam penentuan penerimaan hipotesis terdapat beberapa hal yang perlu pembaca cermati. Jika hipotesis alternatif yang digunakan adalah \(\tilde{\mu}<\tilde{\mu_0}\), hipotesis nol dapat ditolak hanya jika nilai \(w_+\) kecil dan \(w_-\) besar. Sebaliknya jika hipotesis alternatif yang digunakan adalah \(\tilde{\mu}>\tilde{\mu_0}\), hipotesis nol dapat ditolak hanya jika nilai \(w_+\) besar dan \(w_-\) kecil. Untuk uji dua sisi, hipotesis nol akan ditolak jika kedua nilai \(w_+\) dan \(w_-\) cukup kecil.
Prosedur Uji Hipotesis
- Asumsi : Distribusi simetris.
- Hipotesis nol (\(H_0\)) : \(\tilde{\mu}=\tilde{\mu_0}\)
- signed-rank: Menghitung:
\(d_i\) = selisih nilai observasi dengan median pembanding.
\(r_i\) = rangking \(d_i\) tanpa mempedulikan tanda (nol dikecualikan)
\(w_+\) = Total \(r_i\) positif
\(w_-\) = Total \(r_i\) negatif
\(w\) = Nilai terkecil antara \(w_-\) dan \(w_+\)
- Komputasi jumlah rangking dan aturan penolakan berdasarkan \(H_a\)
| \(H_a\) | RR pada level \(\alpha\) | komputasi |
|---|---|---|
| \(\tilde{\mu}> \tilde{\mu_0}\) | \(w \le w_\alpha\) | \(w_-\) |
| \(\tilde{\mu}< \tilde{\mu_0}\) | \(w \le w_\alpha\) | \(w_+\) |
| \(\tilde{\mu}\ne\tilde{\mu_0}\) | \(w \le w_\alpha\) | \(w\) |
Untuk \(n\ge15\) aturan penolakan dapat menggunakan pendekatan distribusi normal seperti pada Tabel 3.
- Statistik Uji
Untuk ukuran sampel \(n<15\) nilai kritis dapat ditentukan berdasarkan tabel nilai kritis untuk Signed-Rank Test yang dapat pembaca unduh pada tautan https://math.ucalgary.ca/files/math/wilcoxon_signed_rank_table.pdf.
Untuk ukuran sampel \(n\ge15\) dapat menggunakan pendekatan distribusi normal dengan sebelumnya menghitung nilai Z berdasarka nilai \(w_+\) (atau \(w_-\)).
\[\begin{equation} \mu w_+=\frac{n\left(n+1\right)}{4}\ dan\ \sigma_{w_+}^2=\frac{n\left(n+1\right)\left(2n+1\right)}{24} \tag{8} \end{equation}\]Sehingga nilai Z dapat dihitung menggunakan persamaan berikut:
\[\begin{equation} Z=\frac{w_+-\mu w_+}{\sigma w_+} \tag{9} \end{equation}\]Prosedur Uji Hipotesis Menggunakan R
Prosedur uji signed-rank test juga dapat dilakukan di R menggunakan fungsi wilcox.test(). Fungsi ini dapat digunakan untuk melakukan dua buah uji yaitu signed-rank dan Wilcoxon Rank Sum. Khusus untuk signed rank kita dapat melakukan test untuk satu atau dua populasi. Jika kita ingin melakukannya untuk satu populasi, maka kita hanya perlu menginputkan satu vektor saja. Berikut adalah format fungsi tersebut:
wilcox.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, conf.level = 0.95, ...)Note:
- x,y: vektor numerik. Kedua argumen akan terisi jika akan dilakukan uji hipotesis untuk dua populasi.
- alternative: diguanakan untuk menentukan jenis uji hipotesis apakah satu sisi(“less” dan “greater”), atau dua sisi (“two.sided”).
- mu: rata-rata populasi. Secara default nilainya
0- paired: vektor logikal yang menentukan apakah uji dua populasi digunakan untuk sampel berpasangan (
TRUE) atau tidak (FALSE).- conf.level: tingkat kepercayaan. Secara default tingkat kepercayaan yang digunakan adalah
95%.
Jawab:
- \(H_0: \tilde{\mu}=1,8\)
- \(H_a: \tilde{\mu}\ne1,8\)
- \(\alpha=0,05\)
Berdasarkan Tabel nilai kritis signed-rank test diperoleh nilai kritis untuk \(\alpha=0,05\) sebesar 8 dengan menggunakan parameter n=10 (pengecualian selisih sama dengan nol) dan median=1.8. Aturan penolakan berdasarkan nilai tersebut berada pada rentang nilai \(w\le8\).
Hasil perhitungan \(d_i\) dan rangking masing-masing nilai disajikan sebagai berikut:
| \(d_i\) | \(r_i\) |
|---|---|
| -0,3 | 5,5 |
| 0,4 | 7 |
| -0,9 | 10 |
| -0,5 | 8 |
| 0,2 | 3 |
| -0,2 | 3 |
| -0,3 | 5,5 |
| 0,2 | 3 |
| -0,6 | 9 |
| -0,1 | 1 |
Berdasarkan nilai \(w_+=13\) dan \(w_-=42\). Karena berupa uji dua sisi maka nilai \(w\) perlu ditentukan. Berdasarkan kedua nilai tersebut nilai \(w=13\) (nilai terkecil).
Dengan menggunakan R kita dapat melakukan uji menggunakan fungsi wilcox.test(). Uji ini akan menghasilkan p-value sehingga aturan penolakan \(H_0\) menggunakan p-value akan sama seperti uji lainnya, dimana jika p-value \(\ge H_0\), maka hipotesis nol diterima. Berikut adalah sintaks untuk melakukannya:
wilcox.test(x=df, alternative ="two.sided", mu = 1.8,
conf.level = 0.95)## Warning in wilcox.test.default(x = df, alternative = "two.sided", mu =
## 1.8, : cannot compute exact p-value with ties## Warning in wilcox.test.default(x = df, alternative = "two.sided", mu =
## 1.8, : cannot compute exact p-value with zeroes##
## Wilcoxon signed rank test with continuity correction
##
## data: df
## V = 13, p-value = 0.1522
## alternative hypothesis: true location is not equal to 1.8Kesimpulan: \(w\) > \(w_\alpha\). Terima \(H_0\). Median hasil observasi tidak berbeda signifikan dengan median hasil percobaan sebelumnya.
11.4 Uji Asumsi Normalitas Distribusi Data
Pada pengujian hipotesis yang telah dilakukan, asumsi normalitas merupakan asumsi yang wajib terpenuhi jika prosedur yang digunakan adalah prosedur uji parametrik. Terdapat dua buah cara untuk melihat apakah suatu data berditribusi normal atau tidak, cara tersebut adalah sebagai berikut:
- Metode grafis (QQ-plot, ECDF, Density plot, Histogram, dan Boxplot)
- Metode matematis (Shapiro-Wilk, Cramer-von Mises, Shapiro-Francia, Anderson-Darling, Liliefors, Pearson Chi-square, dll)
Metode grafis telah banyak kita bahas pada Chapter-Chapter terkait visualisasi sebelumnya. Pada Chapter ini kita akan fokus membahas metode yang kedua.
Hipotesis yang digunakan pada uji asumsi normalitas adalah sebagai berikut:
\[ H_0:\ Sampel\ berdistribusi\ normal \]
\[ H_1:\ Sampel\ tidak\ berdistribusi\ normal \]
11.4.1 Shapiro-Wilk
Metode uji normalitas Shapiro-Wilk merupakan metode uji normalitas nonparametrik yang memiliki power yang besar, khususnya untuk sampel berukuran relatif kecil. Versi awal metode ini terbatas dengan jumlah sampel 3 sampai 50 sampel. Versi selanjutnya mengalami modifikasi sehingga dapat menangani sampel sampai dengan 5000 sampel bahkan lebih.
Versi awal persamaan matematis metode Shapiro-Wilk disajikan pada Persamaan (10)
\[\begin{equation} W=\frac{\left(\sum_{i=1}^ma_i\left(x_{n+1-i}-x_i\right)\right)^2}{\sum_{i=1}^n\left(x_i-\overline{x}\right)^2} \tag{10} \end{equation}\]dimana \(m=\frac{n}{2}\) (\(n\) genap) dan \(m=\frac{n-1}{2}\) (\(n\) ganjil), \(n\) merupakan jumlah sampel, dan \(a\) merupakan bobot yang didasarkan pada nilai \(n\) (tabel penentuan nilai \(a\) dapat pembaca lihat pada tautan http://www.real-statistics.com/statistics-tables/shapiro-wilk-table/).
Untuk perhitungan secara manual, langkah-langkah perhitungannya adalah sebagai berikut:
- Urutkan nilai data dari yang terkecil sampai terbesar.
- Tentukan nilai \(m\) dari jumlah sampel \(n\).
- Hitung jumlah selisih kuadrat sampel (penyebut pada Persamaan (10))
- Hitung nilai selisih \(a_{i}\left(x_{i}-\bar{x}\right)\).
- Hitung nilai \(W\) menggunakan Persamaan (10).
- Untuk menghitung nilai p-value gunakan Tabel Shaphiro-Wilk yang dapat pembaca akses pada tautan http://www.real-statistics.com/statistics-tables/shapiro-wilk-table/. Gunakan metode interpolasi untuk memperoleh nilai yang paling mendekati \(W\). Misal diperoleh \(W=0,975\) dengan \(n=10\). Berdasarkan Tabel Shapiro-Wilk nilai p-value uji berada antara 0,90 (\(W=0,972\)) dan 0,95 (\(W=0,978\)).
Untuk jumlah sampel yang besar (sampai 5000) Persamaan (10) dimodifikasi menjadi Persamaan (11).
\[\begin{equation} W=\frac{\left(\sum_{i=1}^na_ix_i\right)^2}{\sum_{i=1}^n\left(x_i-\overline{x}\right)^2} \tag{11} \end{equation}\]Nilai p-value uji selanjutnya dihitung menggunakan pendekatan kurva normal standard (\(Z\)). Persamaan (12) menyajikan cara menghitung nilai koefisien \(Z\).
\[\begin{equation} Z=\frac{\ln\left(1-W\right)-\mu}{\sigma} \tag{12} \end{equation}\]dimana
\[\begin{equation} \mu=0,0038915\left(\ln\left(n\right)\right)^3-0,083751\left(\ln\left(n\right)\right)^2-0,31082\left(\ln\left(n\right)\right)-1,5861 \tag{13} \end{equation}\] \[\begin{equation} \sigma=e^{0,0030302\left(\ln\left(n\right)\right)^2-0,082676\left(\ln\left(n\right)\right)-0,4803} \tag{14} \end{equation}\]Contoh perhitungan uji normalitas Shapiro-Wilk dapat pembaca cek pada tautan http://www.real-statistics.com/tests-normality-and-symmetry/statistical-tests-normality-symmetry/shapiro-wilk-test/ dan http://www.real-statistics.com/tests-normality-and-symmetry/statistical-tests-normality-symmetry/shapiro-wilk-expanded-test/
11.4.2 Cramer-von Mises
Uji normalitas Cramér-von Mises adalah tes fungsi omnibus distribusi empiris untuk hipotesis normalitas komposit. Uji ini menggunakan jumlah selisih kudrat antara proporsi kumulatif yang diamati dan yang diharapkan. Statistik uji metode ini disajikan pada Persamaan (15).
\[\begin{equation} W=\frac{1}{12n}+\sum_{i=1}^n\left[p_i-\frac{2i-1}{2n}\right]^2 \tag{15} \end{equation}\]dimana
\[\begin{equation} p_{i=}\Phi\left[\frac{x_i-\overline{x}}{s}\right] \tag{16} \end{equation}\]merupakan fungsi distribusi kumulatif distribusi normal standard. \(\bar{x}\) dan \(s\) merupakan nilai mean dan simpangan baku sampel.
p-value dari statistik uji dapat dihitung menggunakan pendekatan fungsi normal standard (nilai Z) berdasarkan pada Tabel 4.9 Stephens (1986) menggunakan Persamaan (17).
\[\begin{equation} Z=W\left(1+\frac{0,5}{n}\right) \tag{17} \end{equation}\]11.4.3 Shapiro-Francia
Uji normalitas Shapiro-Francia merupakan versi sederhana dari uji Shapiro_Wilk. Uji ini secara umum sama dengan uji Shapiro-Wilk untuk jumlah data yang besar. Seperti uji Shapiro-Wilk, uji Shapiro-Francia menghitung nilai \(W\) untuk melihat apakah data berasal dari distribusi normal atau tidak. Jika data berdistribusi normal, maka akan terdapat korelasi antara data yang telah diurutkan dan nilai Z yang diambil dari distribusi normal standard.
Nilai statistik uji dihitung menggunakan Persamaan (18) untuk data yang telah diurutkan.
\[\begin{equation} W=\frac{\left(\sum_{i=1}^nm_ix_i\right)^2}{\left(n-1\right)s^2\sum_{i=1}^nm_i^2} \tag{18} \end{equation}\]dimana \(x_i\) merupakan data pada urutan ke-i, \(m_i\) merupakan nilai perkiraan yang diharapkan pada data dengan urutan ke-i dari kuantil normal (atau nilai z). \(m_i\) dapat dihitung menggunakan Persamaan (19)
\[\begin{equation} m_i=\Phi^{-1}\left(\frac{i}{n+1}\right) \tag{19} \end{equation}\]dimana \(\Phi^{-1}\) merupakan nilai inverse dari distribusi normal standard (Z). Nilai p-value selanjutnya dapat dihitung menggunakan Tabel Shapiro-Francia pada Appendix D tautan https://www.itrcweb.org/gsmc-1/Content/Resources/Unified_Guidance_2009.pdf#10.5.2.
11.4.4 Anderson-Darling
Uji normalitas Anderson-Darling merupakan uji fungsi omnibus densitas empiris (EDF) untuk hipotesis normalitas komposit. Statistik uji disajikan pada Persamaan (20)
\[\begin{equation} m_i=\Phi^{-1}\left(\frac{i}{n+1}\right) \tag{20} \end{equation}\]p-value selanjutnya dapat dihitung menggunakan pendekatan distribusi normal standard menggunakan nilai Z berdasarkan Tabel 4.9 di Stephens (1986). Perhitungan nilai Z disajikan pada Persamaan (21).
\[\begin{equation} Z=A\left(1+\frac{0,75}{n}+\frac{2,25}{n^2}\right) \tag{21} \end{equation}\]Uji Anderson-Darling merupakan uji EDF yang direkomendasikan oleh Stephens (1986). Dibandingkan dengan uji Cramer-von-Misses (sebagai alternatif kedua), uji Anderson-Darling memberikan bobot lebih pada ekor distribusi.
11.4.5 Liliefors (Kolmogorov-Smirnov)
Ujnormalitas Liliefors (Kolmogorov-Smirnov) merupakan uji fungsi omnibus distribusi empiris untuk uji normalitas komposit. Statistik uji yang digunakan didasarkan pada nilai selisih absolut maksimum antara fungsi distribusi kumulatif empiris dan hipotetikal. Komuptasi statistik uji disajikan pada Persamaan (22).
\[\begin{equation} D=\max\left\{D^+,\ D^-\right\} \tag{22} \end{equation}\]dimana
\[\begin{equation} D^+=\max_{i=1,..,n}\left\{\frac{1}{n}-p_i\right\},\ \ \ D^-=\max_{i=1,...,n}\left\{p_i-\frac{\left(i-1\right)}{n}\right\} \tag{23} \end{equation}\]p-value dihitung berdasarkan formula Dallas-Wilkinson (1986), dimana diklaim hanya dapat diandalkan ketika p-value lebih kecil dari 0,1. Jika p-value Dallas-Wilkinson lebih besar dari 0,1, maka p-value dihitung menggunakan pendekatan distribusi normal standard (lihat Stephens(1974)). Pehitungan nilai Z menggunakan Persamaan (24).
\[\begin{equation} Z=D\left(\sqrt{n}-0,01+\frac{0,85}{\sqrt{n}}\right) \tag{24} \end{equation}\]11.4.6 Pearson Chi-square
Statistik uji Pearson chi-square disajikan pada Persamaan (25).
\[\begin{equation} P=\sum_{ }^{ }\frac{\left(C_i-E_i\right)}{E_i} \tag{25} \end{equation}\]dimana \(C_i\) merupakan jumlah observasi terhitung dan \(E_i\) merupakan jumlah observasi estimasi di kelas i. Nilai uji tersebut selanjutnya digunakan untuk menghitung p-value menggunakan table chi-square.
Uji normalitas chi-square tidak direkomendasikan digunakan untuk menguji hipotesis normalitas komposit. Hal ini disebabkan karena uji ini memiliki power yang rendah.
11.4.7 Uji Normalitas menggunakan R
Terdapat beberapa library yang dapat digunakan untuk melakukan uji normalitas pada R. Library yang tersedia diantaranya adalah library stats, nortest, dan RcmdrMisc. Pada Tabel 6 disajikan fungsi-fungsi uji normalitas beserta library fungsi tersebut:
| Fungsi | Library | Keterangan |
|---|---|---|
shapiro.test(x) |
stats |
Uji Shapiro-Wilk |
ad.test(x) |
nortest |
uji Anderson-Darling |
cvm.test(x) |
nortest |
uji Cramer-von Mises |
lillie.test(x) |
nortest |
uji Liliefors (Kolmogorov-Smirnov) |
pearson.test(x) |
nortest |
uji Pearson Chi-square |
sf.test(x) |
nortest |
uji Shapiro-Francia |
normalityTest(x,test) |
RcmdrMisc |
uji Normalitas berbagai metode |
Note:
- x: vektor numerik
- test: argumen tambahan berupa fungsi uji normalitas. misal:
shapiro.test.
airquality, lakukan pengujian pada R untuk mengetahui apakah distribusi konsentrasi Ozone berdistribusi normal menggunakan uji Shapiro-Wilk?
Jawab:
Berikut adalah sintaks untuk melakukan uji normalitas pada R:
shapiro.test(airquality$Ozone)##
## Shapiro-Wilk normality test
##
## data: airquality$Ozone
## W = 0.87867, p-value = 2.79e-08# atau
library(RcmdrMisc)## Warning: package 'RcmdrMisc' was built under R version 3.5.3## Loading required package: car## Warning: package 'car' was built under R version 3.5.3## Loading required package: carData## Loading required package: sandwich## Warning: package 'sandwich' was built under R version 3.5.3normalityTest(airquality$Ozone, test="shapiro.test")##
## Shapiro-Wilk normality test
##
## data: airquality$Ozone
## W = 0.87867, p-value = 2.79e-08Kesimpulan: dengan menggunakan \(alpha=5%\) dapat disimpulkan bahwa distribusi konsentrasi Ozone pada dataset airquality tidak berdistribusi normal.
11.5 Tranformasi Box-Cox
Kita telah belajar bagaimana melakukan uji hipotesis untuk satu populasi dan pada Chapter sebelumnya kita juga telah belajar bagaimana menghitung interval kepercayaan. Pada kedua materi tersebut untuk metode parametrik diperlukan pemenuhan asumsi normalitas. Jika asumsi tersebut tidak terpenuhi, maka perlu digunakan metode lain yaitu metode nonparametrik atau melakukan transformasi data untuk memperoleh data yang mendekati distribusi normal.
Transformasi Box-COx merupakan metode tansformasi data yang tidak mengikuti distribusi normal agar data mengikuti distribusi normal. Metode ini dikembangkan oleh George Box dan Sir David Roxbee Cox.
Inti dari tansformasi Box Cox adalah eksponen, lamda \(\lambda\) yang bervariasi dari -5 sampai 5. Semua nilai \(\lambda\) dipertimbangkan dan nilai optimal untuk data selanjutnya dipilih. Nilai optimal merupakan \(\lambda\) yang menghasilkan perkiraan terbaik dari kurva distribusi normal. Transformasi y memiliki bentuk yang disajikan pada Persamaan (26).
\[\begin{equation} y\left(\lambda\right) = \begin{cases} \frac{x^{\lambda}-1}{\lambda} & \quad \lambda\ne0\\ \log\left(x\right) & \quad \lambda = 0 \end{cases} \tag{26} \end{equation}\]Uji ini hanya berfungsi pada data bernilai positif. Jika data negatif, maka Persamaan (26) akan dimodifikasi menjadi Persamaan (27).
\[\begin{equation} y\left(\lambda\right) = \begin{cases} \frac{\left(x+\lambda_2\right)^{\lambda_2}-1}{\lambda_1} & \quad \lambda_{1}\ne0\\ \log\left(x+\lambda_2\right) & \quad \lambda_{1} = 0 \end{cases} \tag{27} \end{equation}\]Setelah nilai \(\lambda\) optimal diperoleh, transformasi data dilakukan menggunakan Persamaan (26) atau Persamaan (27). Pada Tabel 7 disajikan nilai \(\lambda\) dan transformasinya yang bersesuaian untuk menghasilkan distribusi normal.
| \(\lambda\) | Transformasi |
|---|---|
| 2 | \(x^2\) |
| 0,5 | \(\sqrt{x}\) |
| 0 | \(\ln{x}\) |
| -0,5 | \(\frac{1}{\sqrt{x}}\) |
| -1 | \(\frac{1}{x}\) |
Pada R penentuan \(\lambda\) optimal dapat menggunakan fungsi powerTransform() dari library car. Fungsi ini memungkinkan kita menghitung nilai \(\lambda\) optimal baik untuk yang seluruh nilai datanya positif, negatif, atau sebagian datanya negatif (transformasi Yeo-Jonhson). Berikut adalah format fungsinya:
powerTransform(object, family="bcPower")Note:
- object: objek dapat berupa kelas formula
lmataulmerMod, atau matrix atau vektor.- family: keluarga transformasi. Nilai yang mungkin adalah “bcPower” jika seluruh datanya positif, “bcnPower” jika seluruh datanya negatif, dan “yjPower” jika sebagian datanya negatif.
airquality, lakukan transformasi Box-Cox pada R untuk agar distribusi konsentrasi Ozone berdistribusi normal serta lakukan pengujian kembali distribusi baru tersebut apakah telah berdistribusi normal atau belum?
Jawab:
Kita akan memvisualisasikan terlebih dahulu data konsentrasi Ozone pada dataset airquality. Visualisasi distribusi Ozone disajikan pada Gambar 3.
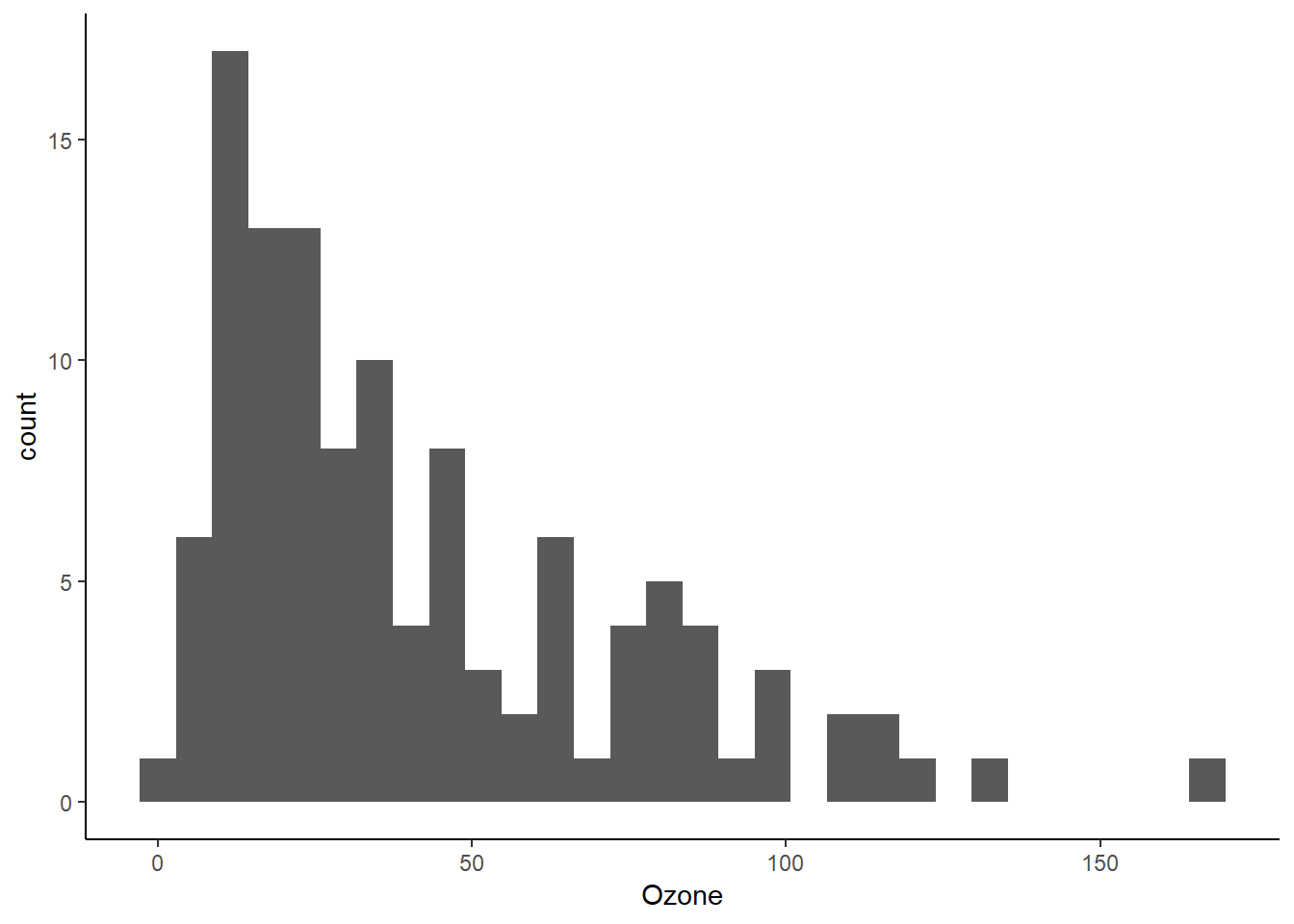
Figure 3: Visualisasi distribusi konsentrasi Ozone
Berdasarkan Gambar 3 distribusi Ozone memiliki kemencengan positif sehingga perlu dilakukan transformasi Box-Cox. Berikut adalah sintak untuk menentukan nilai \(\lambda\) optimum pada transformasi Box-Cox:
library(car)
summary(powerTransform(airquality$Ozone,
family="bcPower"))## bcPower Transformation to Normality
## Est Power Rounded Pwr Wald Lwr Bnd Wald Upr Bnd
## airquality$Ozone 0.2034 0.33 0.0226 0.3842
##
## Likelihood ratio test that transformation parameter is equal to 0
## (log transformation)
## LRT df pval
## LR test, lambda = (0) 5.36145 1 0.020587
##
## Likelihood ratio test that no transformation is needed
## LRT df pval
## LR test, lambda = (1) 56.88925 1 4.6074e-14Berdasarkan hasil yang diperoleh diketahui nilai \(\lambda\) optimum sebesar 0,2034. Kita akan menggunakan nilai ini untuk mentransformasi konsentrasi Ozone. Berikut adalah visualisasi hasil transformasinya:
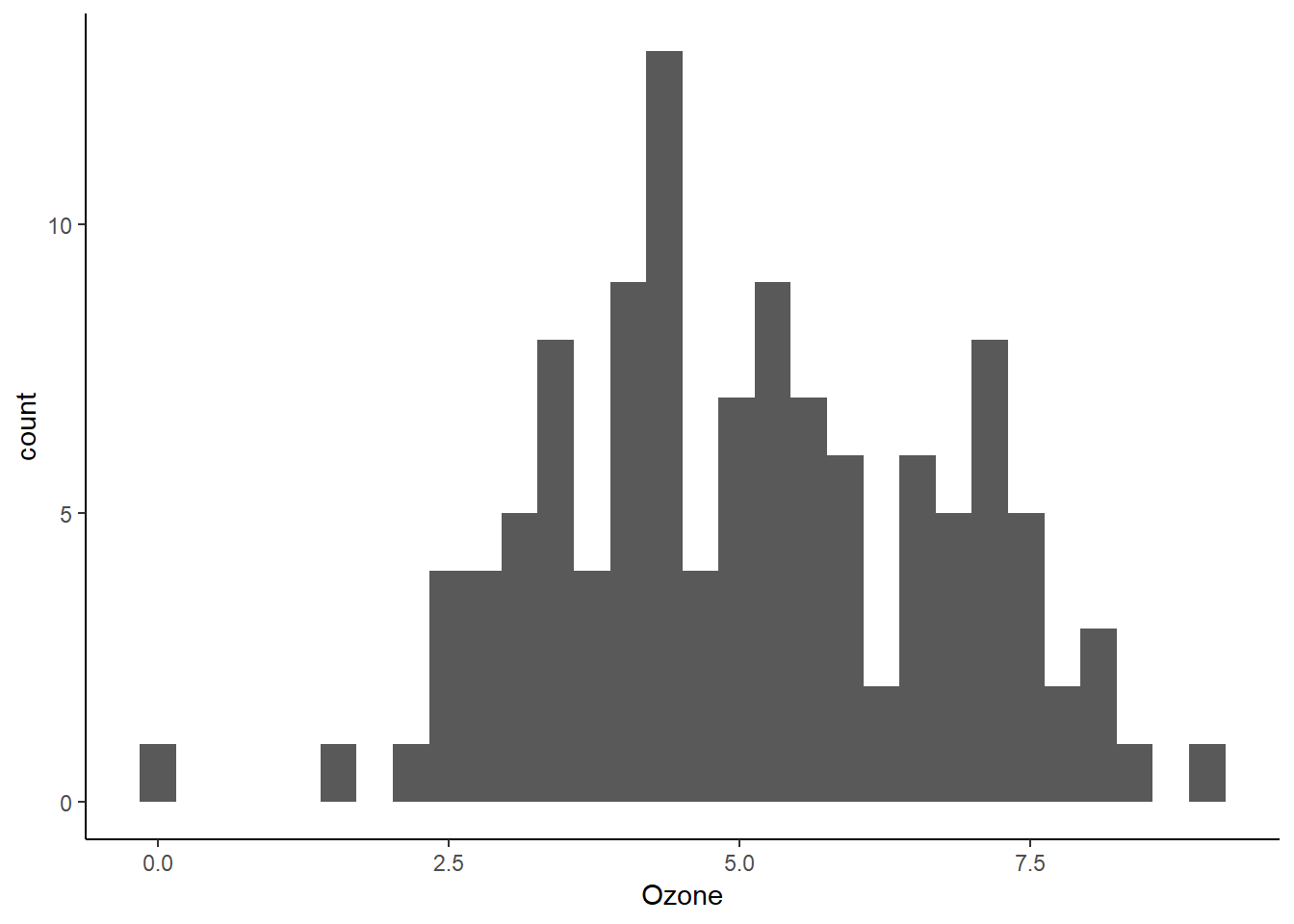
Figure 4: Visualisasi distribusi konsentrasi Ozone hasil transformasi Box-Cox
Berdasarkan Gambar 4 distribusi Ozone hasil transformasi telah mendekati bentuk kurva normal. Selanjutnya distribusi tersebut kembali diuji normalitasnya menggunakan sintaks berikut:
shapiro.test(((airquality$Ozone^0.2034)-1)/0.2034)##
## Shapiro-Wilk normality test
##
## data: ((airquality$Ozone^0.2034) - 1)/0.2034
## W = 0.98714, p-value = 0.3399Kesimpulan: dengan menggunakan \(\alpha=0,05\) dapat disimpulkan bahwa distribusi konsentrasi Ozone hasil transformasi Box-Cox telah berdistribusi normal.
Referensi
- Akritas, M. 2016. Probability $ Statistics with R. Pearson.
- Chi Yau. 2014. R Tutorial with Bayesian Statistics Using OpenBUGS. Amazon Kindle.
- Crawley, M.J. 2015. Statistics: An Introduction Using R. John Wiley & Sons.
- Damanhuri, E. 2011. Statitika Lingkungan. Penerbit ITB.
- Dokumentasi library Car
- Dokumentasi library stats
- Dokumentasi library RcmdrMisc
- Helsel, D.R., Hirsch, R.M. 2002. statistical Methods in Water Resources. USGS.
- Janicak, C.A. 2007. Applied Statistics in Occupational Safety and Health. Government Institutes.
- Kerns, G.Jay. 2018. Introduction to Probability and Statistics Using R Third Edition. GNU Free Documentation License.
- Ofungwu, J. 2014. Statistical Applications For Environmental Analysis and Risk Assessment. John Wiley & Sons, Inc.